WOLFSIGHT Looks at Video
If you’ve ever watched a movie and understood a plot point based on off-screen noises rather than what the characters are acting out on screen, then your viewing experience relied on multimodal context.
Edward S., Liz Richerson, John Nolan, Nicole F.
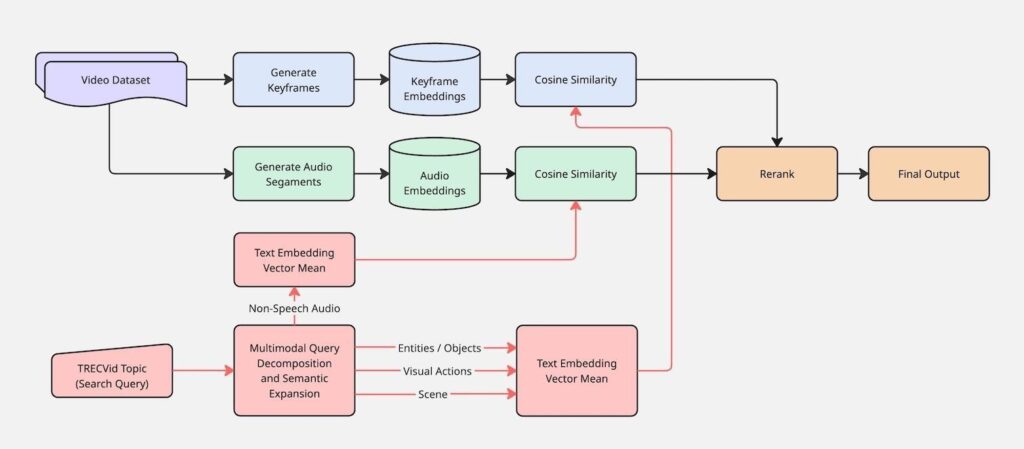
Analysts face the challenge of reviewing vast amounts of complex data that spans multiple modalities. In previous work we sought to understand the feasibility of incorporating Large Vision Language Models (LVLMs) into the image triage process, with a goal of reducing analyst workload and improving both the efficiency and accuracy of technical intelligence analysis. We created a technical document search system with a coarse first pass search that compared a user-provided query against CLIP embeddings of images from documents. Users could optionally apply query expansion to have an LLM generate additional similar queries, which could broaden the coarse filter to identify additional images. The user then selected the number of images to include in the next processing stage, which employed an LVLM to enrich the CLIP image summary with the document text related to that image, resulting in a “contextualized image summary.” The system then conducted semantic search of the user’s query against the contextualized image summaries to provide the user with the most relevant documents to their query based on information conveyed in both document images and text.
The resulting search system provided different search results than those obtained by searching text and image modalities in isolation, indicating the value of the integrated approach. Initial user reviews were overall positive, with users agreeing that such a system would be useful in triaging documents with images. Furthermore, for a small set of technical documents, users largely agreed with the LVLM’s assessment of document portions relevant to an image. Based on these positive outcomes, the system components were subsequently transitioned for use in some mission applications and also helped inform continued development decisions where relevant.
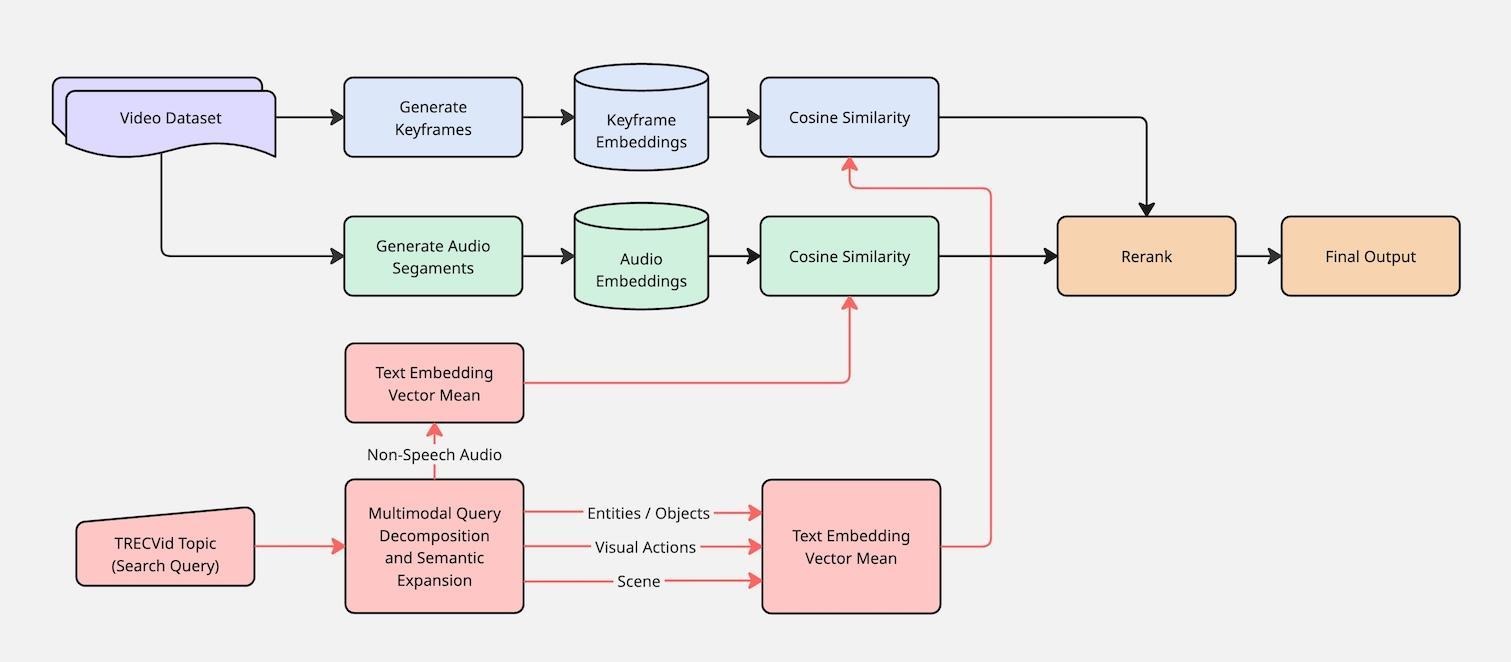
In the next phase of work, we sought to build upon the previous success by expanding the multimodal approach to include additional data types, specifically video, which introduced audio and movement considerations. We aimed to leverage a combination of smaller, focused models—such as text-image (CLIP) and text-audio (CLAP) models—to enrich data from one modality with context from another, ultimately creating a more thorough and searchable data description for the analyst. This small-model approach allowed for searching and filtering data based on events detected across different modalities. For example, when searching for video scenes of rain, a purely image-focused model might fail to recognize the visual cues. However, a text-audio (CLAP) model could recognize the sound of rain, and this audio information then served as a filter to include relevant scenes in the search results, even if the image model output gave no indication of rain. Similar to the prior work, which used low-resource text-image models as a coarse filter before engaging a resource-intensive LVLM, the team explored how to strategically combine these smaller multimodal models with LLMs and LVLMs to help analysts prioritize which data deserved immediate focus.


Looking toward video
We explored how existing components generalize to video search tasks. The team adopted several elements from the previous pipeline, including some pretrained small multimodal models, query expansion, semantic search, and LVLM-based relevance judgments. To accommodate the video modality, we augmented the system with several new core functions to provide different capabilities.
Core Functions
Query transformation
- Modality-aware query decomposition
- Employs an LLM to assign each user query at least one of five categories that reflect semantic, syntactic, and acoustic properties: scene setting, entities and objects, semantic actions, spoken content, and non-speech audio.
Video preprocessing
- Segmentation
- Defines a distinct range of a video. When segments were not provided with the dataset, we applied one of two approaches: basic approach of pre-defined time intervals, or establish segment boundaries where adjacent frame embeddings exceed a certain distance from each other.
- Key frame identification
- Selects a representative frame of a video sequence. We implemented a basic approach of sampling one frame per second when keyframes were not provided with the dataset.
Multi-Modal Pretrained Models for Retrieval Tasks
- Contrastive Text-Image Embedding Model
- Captures information conveyed in text and image modalities. We selected nine pretrained models from the CLIP, SigLIP, and SigLIP2 families, and fine tuned a CLIP model (FG-CLIP). Include fine-tuned clip version (FG-CLIP)
- Traditional Text-Based Information Retrieval (IR) Models
- Searches text data without the assistance of LLMs. We chose BM25 and SPLADE IR methods. The text data being searched is a text caption of each keyframe from a video segment generated using phi-3.5-vision-instruct, with pixtral-12B-Base-2409 as a fallback model for videos phi-3.5-vision-instructe refused to caption.
- Audio-Based Retrieval
- Captures information conveyed in text and audio modalities. We used CLAP embeddings to index and retrieve audio segments. We selectively applied this module only to queries which the modality-aware query decomposition step predicted audio information was relevant, with a goal of maintaining computational efficiency and minimizing false positives.
Relevance judgments
- LVLM-Based Relevance Judging
- An LVLM assesses the relevance of keyframes to natural language queries, which serves (1) as a proxy metric to evaluate embedding model quality and (2) as a reranking mechanism in downstream retrieval pipelines following initial coarse filtering. We used GPT-4.1-mini as the LVLM judge.
Retrieval workflows
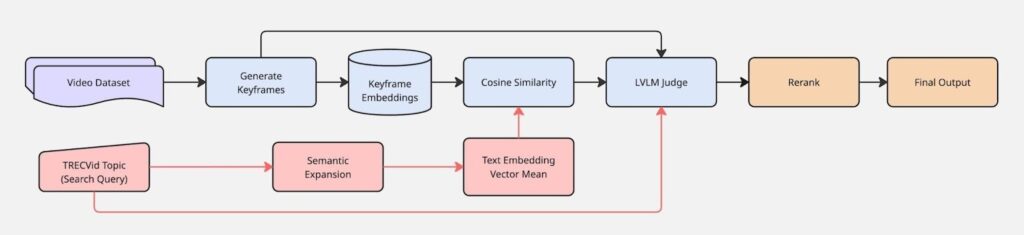
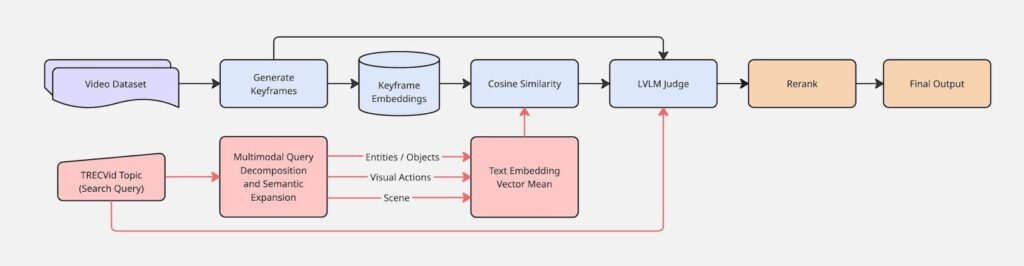
The Ad-hoc Video Search (AVS) task, part of NIST’s annual Text REtrieval Conference (TREC), provided context for applying WOLFSIGHT to a video retrieval scenario and an opportunity to evaluate system performance on a dataset with human-judgments. We combined the system components in the following four ways to generate submissions to the 2025 task, where each workflow tested a different configuration of embedding, query augmentation, and reranking strategies.
- Embedding-Only Baseline (FG-CLIP)
- Semantic Expansion + LVLM Judge
- Multi-modal query decomposition + LVLM Judge
- Multi-modal query decomposition + CLAP
Findings
We applied WOLFSIGHT workflows to three different datasets to understand performance in multiple scenarios. Two were toy datasets, with one consisting of a selection of approximately 10 technical documents from arXiv and associated user queries, and another of a sample of approximately 100 snippets from publicly available FAA airport videos. For the arXiv data, user queries were aimed toward image content, text content, or content that required combining image- and text-based information. An LVLM assessed the relevance of the search query to documents retrieved on a scale from “0 – not at all relevant” to “3 – extremely relevant.” Queries for the airport data focused on airplane actions, where a human manually labeled actions in the videos. The third dataset came from the TREC AVS task, where ground truth for prior tasks was available but withheld for the 2025 task. The query decomposition results on the AVS dataset showed that those queries focused largely on image-based information with a few queries relying on non-speech-based audio information. No AVS queries relied on information conveyed through speech. The toy datasets enabled some insight into system performance, but lacked scale and rigorous development offered by the AVS data.
Our manual inspection of search results from the different WOLFSIGHT implementations found that search results were generally more relevant when reranking with LVLMs to combine information from different modalities. Analysis of the search results supported this observation. For the arXiv data, the LVLM judged documents retrieved for combined image- and text-based queries as extremely relevant more often than for either query type focused on a single modality. This suggests that the WOLFSIGHT pipeline could provide enhanced support to analysts seeking information conveyed through multiple modalities over modality-specific approaches. Future work could expand the arXiv dataset to enhance the types of analysis the data can enable.
Results on the airport data showed that reranking search results with an LVLM had the intended effect of raising the most relevant results to the top ranks, as indicated by the increase in nDCG@10 scores when calculated before and after the rerank step. Further work is needed to expand the dataset to include more relevant results to be found for each of the queries, and explore the impact of additional pipeline steps like query expansion.
| Query | nDCG@10 Before Rerank | nDCG@10 After Rerank |
| Plane lifting off | 0.269 | 0.967 |
| Plane landing | 0 | 0.362 |
| People being loaded on plane | N/A | N/A |
| Cargo being loaded on plane | 0 | 0 |
| People being removed from plane | N/A | N/A |
| Cargo being removed from plane | N/A | N/A |
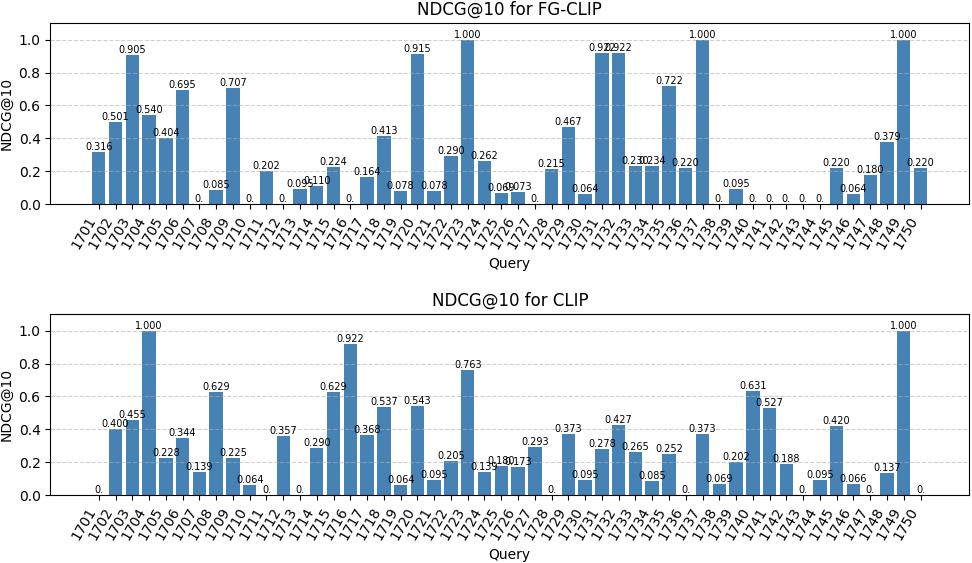
The available ground truth data from previous AVS tasks allowed us to calculate some retrieval performance metrics for different combinations of pipeline components. Looking at the impact of pre-trained CLIP vs fine-tuned FG-CLIP showed mixed results on nDCG@10 for available test queries, where some queries exhibited more relevant results when FG-CLIP provided image-based information while CLIP produced more relevant results for other queries.
When analyzing the effect of multi-modal aware query decomposition in the retrieval pipeline, we again saw mixed results when using the original user queries compared to decomposed queries. For example, the user query embedding modestly outperformed the object-only decomposition across all cutoffs, with an nDCG@10 of 0.592 and 0.341, respectively. We hypothesize that modality-aware decomposition is most useful for semantically complex queries, whereas decomposing a simple concrete query may dilute rather than enhance the retrieval focus. The following table shows nDCG@10 and 100 by decomposition categories for the query “At least two persons are working on their laptops together in the same room indoors.”
| Embedding Strategy | nDCG@10 | nDCG@100 |
| object action | 1 | 0.776 |
| objects only | 1 | 0.769 |
| action only | 0.852 | 0.737 |
| scene object action | 0.852 | 0.501 |
| scene object action | 0.827 | 0.412 |
| original user query | 0.779 | 0.336 |
| scene action | 0.643 | 0.339 |
| scene only | 0 | 0.015 |
Our findings show promise that small multimodal models as coarse filters in multimodal search pipelines can extend to video search scenarios. Constructing effective search pipelines from available system components requires scenario-specific considerations to ensure that the components enhance relevance results to better assist analysts. This might mean building search pipelines that are tailored to a specific data source so the most appropriate models for the source are included, or perhaps be interpreted to mean incorporating query transformation assistance within a system to help users curate the search terms that would generate the most relevant results.
This material is based upon work supported in whole or in part with funding from the Department of Defense (DoD). Any opinions, findings, conclusions, or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the DoD and/or any agency or entity of the United States Government.
- Categories: