Meta-Embeddings for Small Object Image Search
QuARI helps to emphasize the specific visual cues in the query, like that specific bit of art, or a lamp shape, or carpet pattern.
- Robert Pless, George Washington University
- Abby Stylianou, Pranavi Kolouju, St. Louis University
- Nathan Jacobs, Eric Xing, Washington University in St. Louis
- Richard Souvenir, Temple University
Analysts and researchers use image search tools to comb through huge collections of photos. Our team’s work in this space is specifically motivated by our efforts to support the National Center for Missing and Exploited Children in recognizing where victims of human trafficking and child sexual abuse are photographed. Their analysts use our investigative image search tool, called TraffickCam, to find images that match victim images in our database of millions of hotel room images. In 2024, our team worked with LAS to improve text-guided image retrieval performance for real world, challenging search problems like this.
This year we focused on addressing improvements to the core retrieval task: can we help people find exactly what they’re looking for in very large datasets of images, even when the differences between images are extremely subtle?
These efforts led to QuARI (Query-Adaptive Retrieval Improvement), a method we developed and recently published at NeurIPS 2025. QuARI introduces a new idea: instead of relying on one static way of comparing images, we let the query itself decide how the search space should be shaped.
Below, we walk through why this matters, how QuARI works, and what makes it a step forward for large-scale image and text-guided retrieval.
Modern vision-language models like CLIP have dramatically improved how we match images and text. But these models still compress every image into a single “global” representation that tries to capture everything at once. That’s great for broad tasks like coarse-grained classification. But it’s not great when you need subtle distinctions—like the difference between:
- one beige hotel room and another almost identical beige hotel room, or
- two species of birds that differ only by a pattern near the tail, or
- a particular object instance hiding in a cluttered scene.
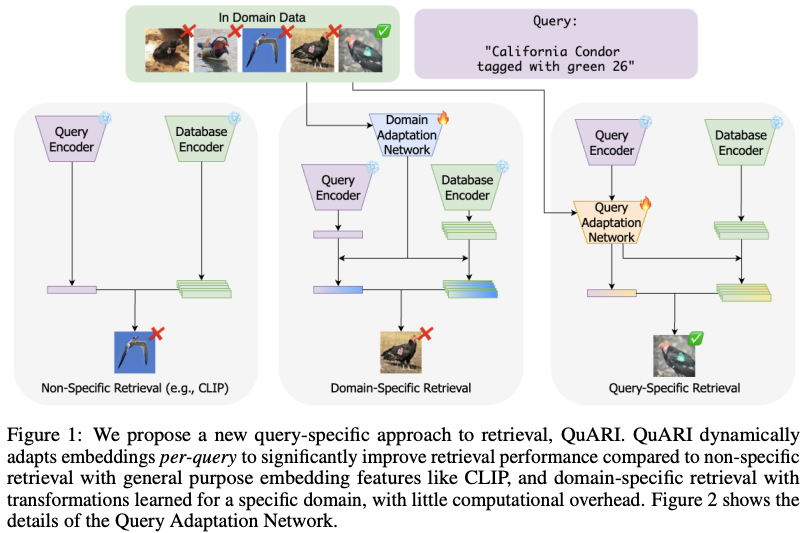
Figure 1 makes this challenge concrete. It shows three retrieval strategies: non-specific retrieval (using a multimodal encoder like CLIP as-is), domain-specific retrieval (tuned for a single dataset), and QuARI’s new idea: query-specific retrieval, where the query actually helps to determine what matters.
Unlike older systems that always use the same embedding space, QuARI adapts that space on the fly. It learns what features matter for a specific query and down-weights features that don’t.
How QuARI Works
The idea behind QuARI is as follows:
- Start with a query — this could be an image or a text description.
- Use a small “hypernetwork” to read that query and generate a custom transformation.
- Apply that transformation to every database embedding (quickly and efficiently).
- Retrieve results using these adapted embeddings.
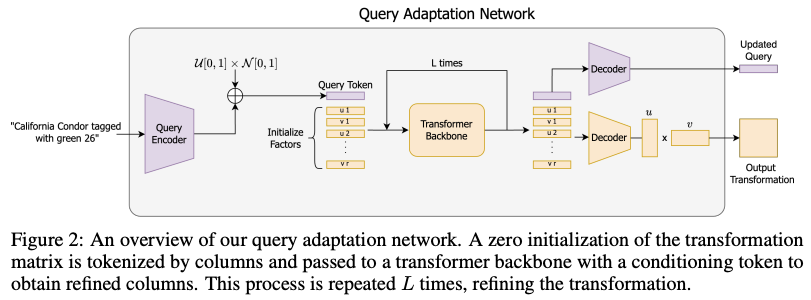
Figure 2 shows this “query adaptation network.” The core idea is that the system uses the query to reshape how the database is viewed, highlighting the fine-grained features that matter for this search, and ignoring irrelevant ones. And because the transformation that we learn is linear and low-rank, we can apply it extremely fast, even across millions of images.
Results
To understand how much this helps, the table below compares standard vision-language model features to the same models enhanced with QuARI.
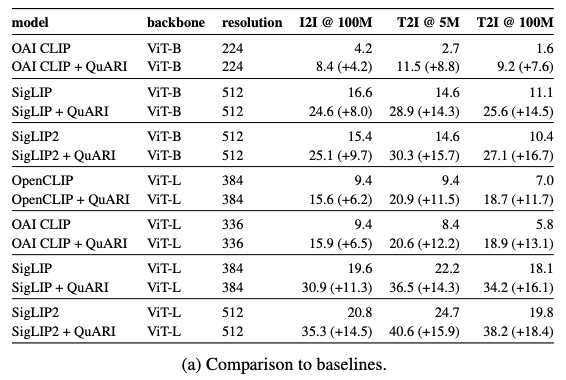
Across multiple backbones, including CLIP, OpenCLIP, SigLIP, and SigLIP2, QuARI provides large jumps in retrieval accuracy, often doubling performance:
- On the ILIAS dataset (instance retrieval at 100 million scale), QuARI improves CLIP-ViT-B from 4.2 to 8.4.
- On SigLIP2-ViT-L, it improves from 20.8 to 35.3.
- On text-to-image retrieval at 5M scale, improvements are even larger: +15 to +18 percentage points.
QuARI achieves large improvements without modifying the original encoder at all. We simply adapt the space those features live in, per query.
A Look at How the Embeddings Change
Figure 3 visualizes these effects. It compares original embeddings to QuARI-adapted ones using t-SNE maps for two different queries.

In the original embedding space, the correct matches are scattered. After applying the query-specific transformation, those correct matches cluster tightly around the query. This provides visual confirmation that QuARI is adapting the embedding space based on the query so that the right results are much closer together.
Faster and Better
Recent work in retrieval research has focused on improving accuracy by adding more computation, such as extra cross-attention layers, large re-ranking transformers, or expensive nearest-neighbor matching over local features. On the other hand, QuARI learns simple linear transformations applied to precomputed global embeddings, making it extremely efficient. Figure 4 compares retrieval performance against computation time.
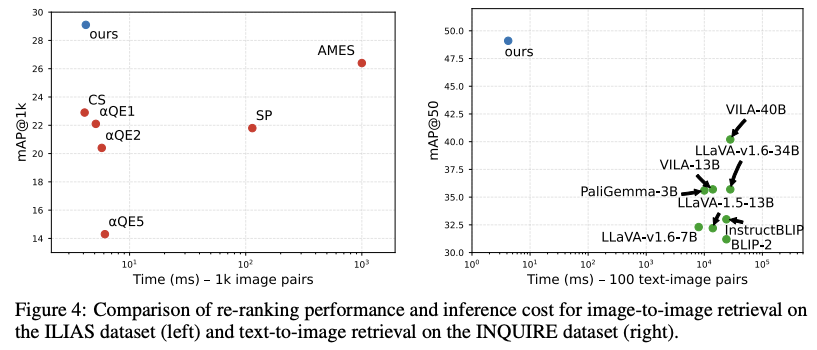
Across both image-to-image (left) and text-to-image (right) re-ranking tasks:
- QuARI is orders of magnitude faster than alternative approaches to re-ranking
- QuARI is also more accurate
- And for text-to-image search, QuARI even outperforms all open-source multimodal LLMs, and is competitive with proprietary ones like GPT-4V and GPT-4o, while being vastly more efficient.
This makes QuARI uniquely suitable for real-world, large-scale deployments, like those needed by analysts in our operational collaborations.
What This Means for Real-World Use Cases
When performing investigative image search to recognize where victims of human trafficking and child sexual abuse are photographed, very small details matter – for example, a small piece of artwork in the background of a victim image might be the only detail that actually matches to an image in the database. But those sorts of matches don’t necessarily get retrieved using typical image retrieval approaches that operate on global image similarity. Because QuARI helps to emphasize the specific visual cues in the query, like that specific bit of art, or a lamp shape, or carpet pattern, or window layout, and down-weights irrelevant features, it allows us to better support the needs of the analysts using TraffickCam. And because QuARI sits on top of existing models (CLIP, SigLIP, OpenCLIP – or even hotel recognition specific encoders that we’ve trained on our own dataset.), it can plug into many existing systems without retraining or rebuilding the underlying encoders.
Code for QuARI can be found at https://github.com/mvrl/QuARI.
This material is based upon work supported in whole or in part with funding from the Department of Defense (DoD). Any opinions, findings, conclusions, or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the DoD and/or any agency or entity of the United States Government.
- Categories: