Tailored Cross-Lingual Conversational Data Summarization and Evaluation
In this project, we proposed a set of metrics to help analysts evaluate summary quality.
Project team members:
- Sammi Sung, Hemanth Kandula, William Hartmann, Matthew Snover (RTX BBN Technologies)
- Elizabeth Richerson, Jascha Swisher, Michael G., Paula F., Patricia K., John Nolan (Laboratory for Analytic Sciences)
Introduction
Challenges of LLM summarization evaluation
With the increasing capability and availability of LLMs, LLM-based document summarization is being widely adopted. Unlike traditional summarization systems, LLM-based approaches allow for a significant amount of customization in the summary through prompting. Summaries can be controlled for the number of words, writing style, and topic of interest. While we can generate many different types of summaries for a single document, how do we determine which summaries are good? Using humans to evaluate the summaries would be both prohibitively challenging and expensive. Generating reference summaries for scoring is also problematic due to the variations in style and goals. LLM-based summarization systems are often deployed based on the qualitative feel of a handful of examples as opposed to a systematic quantitative evaluation. Without metrics, it is impossible to objectively compare summarization systems and measure improvement over time.
One will then ask, is there any way to evaluate the summary automatically? Reference-free metrics have been developed to solve this problem, and they can work well for some traditional text problems. However, they do not address domains outside of traditional written text or applications with customized goals. In these scenarios, automatic summary evaluation is still a major challenge. One example, and the focus of our study, is cross-lingual speech summarization.
How traditional metrics work on Cross-Lingual Conversation Speech Summarization
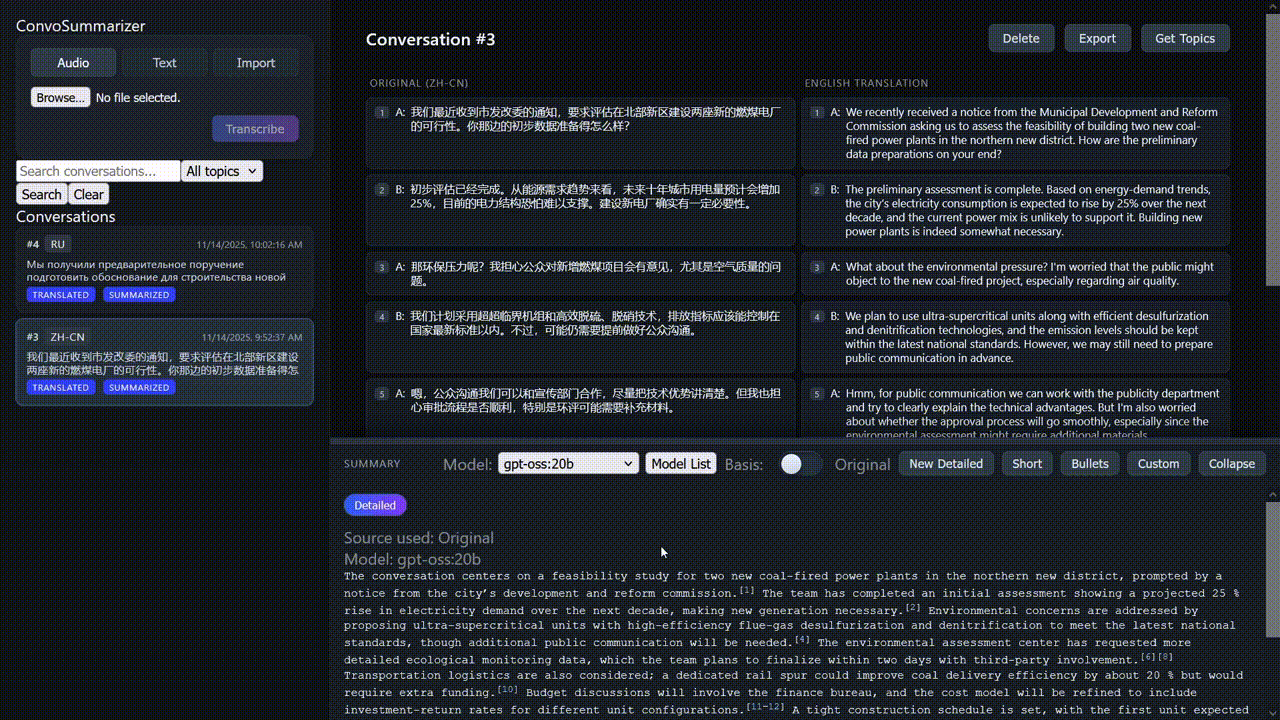
In the scenario of Cross-Lingual Conversation Speech Summarization– A foreign language conversation is recorded, transcribed and translated, and then summarized. The evaluation is challenging due to the multiple layers of information transformation and error introduced.
Let’s look at one example. We have 3 sets of summaries generated from 3 different translations- (1) human translation, (2) machine translation from human transcription, (3) machine translation from machine transcription. We expect the summary quality of (1) to be the best, followed by (2) then (3).
Let see how traditional summarization evaluation metrics work on such a problem. We considered one reference-based metric – ROUGE, and one reference-free metric- SummaC (with two versions SummaCconv and SummaCZS), along with the precision and recall scores BBN proposed (described in the next section).

It turns out that traditional metrics struggle to capture the degradation introduced from machine transcription and translation. ROUGE and SummaCConv look flat and SummaCZS even rates more errorful input as generating better summaries. This is because these metrics are designed for summarization of text documents, not specifically for cross-lingual conversational speech summarization. They do not capture the effect of transcription and translation error, nor the style mismatch between conversational text and written text. This highlights the need for a tailor-made solution for evaluating cross-lingual conversational speech summarization.
BBN’s precision and recall show a consistent drop in summary quality with a reasonable gap between the scores. In the following sections, we will unfold more about the design of our metrics and present some case studies demonstrating how our metrics will be helpful for analysts in solving real world problems.
Proposed Metric Design:
Our evaluation pipeline tries to answer the following questions:
- How many information snippets in this summary are correct? Let’s call this precision.
- How much information is included in this summary? It’s not possible to include everything in the summary so the summarizer must drop some content. Let’s call this recall.
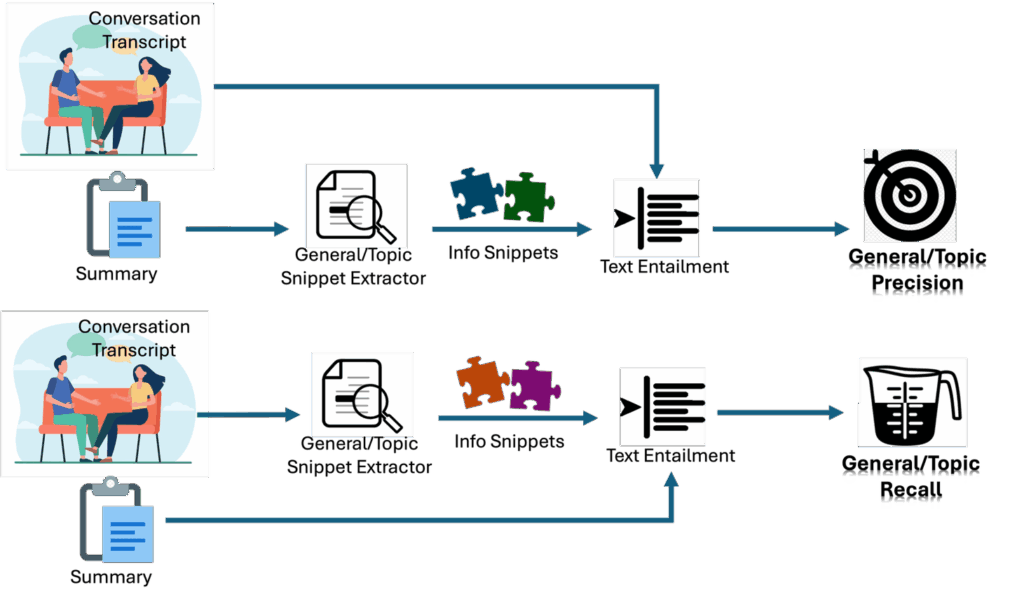
The key elements of the pipeline are the snippet extractor and entailment model. A snippet extractor extracts information snippets from the text. The entailment model measures whether the snippets are entailed by a given statement.
We provided two modes for metrics to handle different types of summaries, general and topic specific.
- General summary: The LLM generates a summary within a given word limit (e.g., 200 words) without giving any context; it’s up to the LLM to decide what information to keep.
- Topic summary: The LLM generates a summary specific to a topic of interest to the user, with no limitation. In the case of topic specific summaries, topic precision and topic recall will look only consider information snippets related to the specified topic.
Case Studies: How to use the metrics?
How useful are our metrics in helping analysts with handling real world problems? Here we illustrate 3 use cases to show the advantages of our metrics.
- Capture quality degradation in the summary from machine transcription and translation error
- Detect summaries with hallucinations – insertion, reduction of information
- Compare different LLMs for summarization
Case Study 1: Summary with ASR and MT error
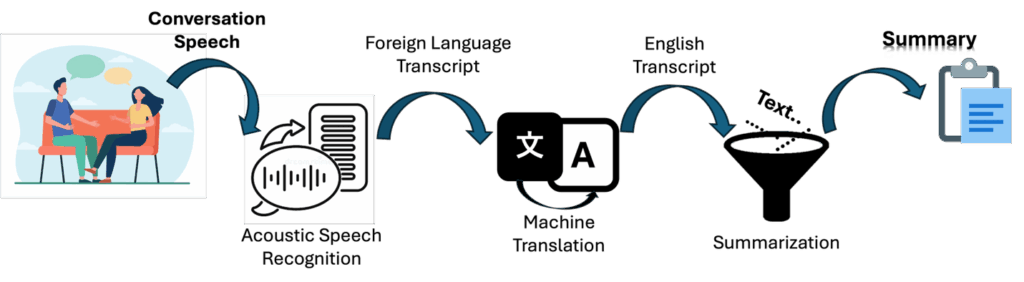
We have a set of Mandarin telephone conversation recordings. The traditional approach to convert these audio recordings to English transcriptions for summarization is to use Acoustic Speech Recognition (ASR) followed by Machine Translation (MT). This will produce error that will distort some meaning of the text, hence degrade the summary quality.
In our use case, we have 33.3% Word Error Rate and 6 points BLEU score drop after running ASR and MT. We can see from the plot that there’s consistent drop in precision and recall for both general and topic summaries when more errors are introduced. This gives the analyst a quantitative sense of how the error effects summary quality.
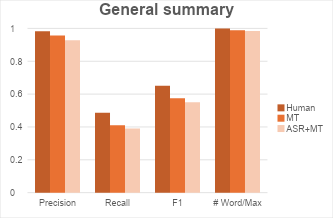
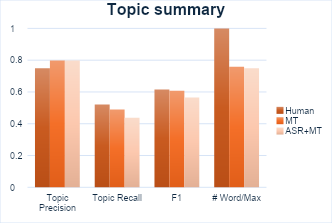
Case Study 2: Impact of hallucinations on summaries
Another use case is how can we detect if irrelevant information is inserted or information is missing from the summary? We prepare 2 extra copies of summaries which ask GPT-4o to hallucinate the summaries as follow:
- Insert: Insert 5 interesting pieces of information to the summary and rewrite it.
- Reduce: Remove 5 pieces of information from the summary and rewrite it.
In the results, we can see a drop in precision when extra information is inserted, meaning the summary become less accurate. Sometimes recall increases a little bit when GPT-4o is able to insert relevant information interpreted from the context. Recall drops when information is reduced, as there’s less information in the summary.


Case Study 3: Which LLM for summarization?
There’s so many open source LLM options, how can we tell which off-the-shelf model is better for summarization? Let’s use our evaluation pipeline to figure this out!

Here we have 4 candidates: Gemma3-27B, LLama3-70B, Mistral-small-2501, Qwen3-32B. We will prompt each of them to generate a few generic and topic specific summaries on human translated conversations. The summaries are scored with our general and topic metrics.
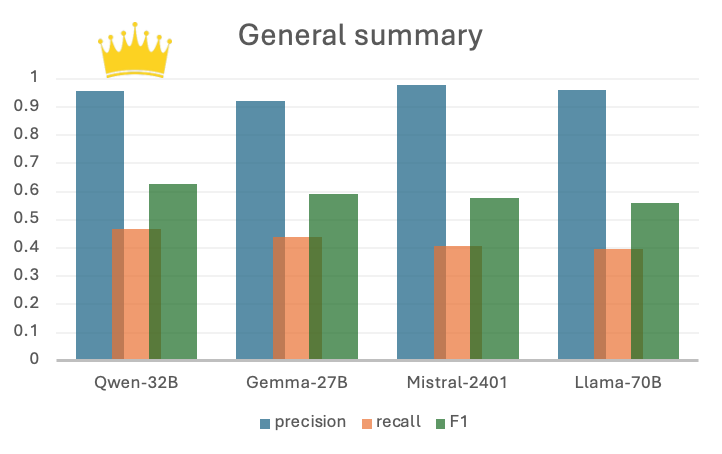

By sorting the scores with overall F1 score (combination of precision and recall), we can see Qwen-32B is suitable for general summaries, and Gemma-27B is good for topic specific summaries. We do not necessarily need to choose the largest 70B model available given the performance.
Evaluation without human reference
What if there’s no human translation, can we still use the metrics? Not a problem!
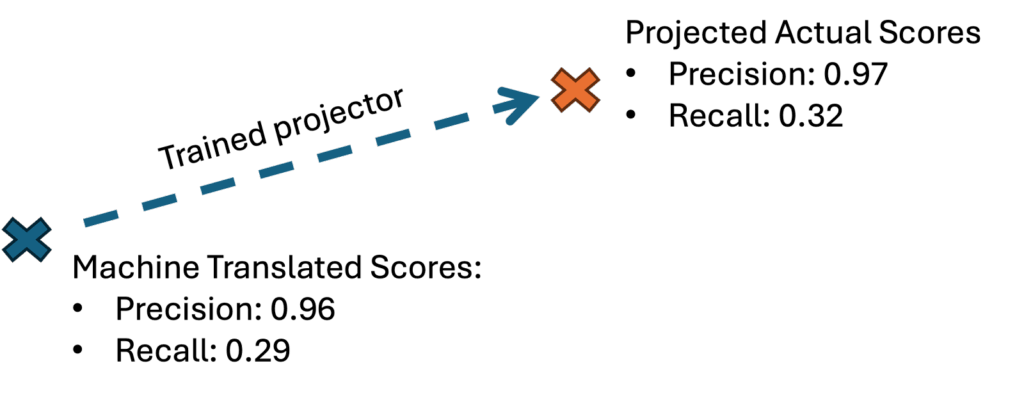
We trained a linear regressor that projects the score if we only have the machine translated conversations. By training the regressor with translated data from 4 languages and testing on one of the held-out-languages, the average MSE (mean square error) is 0.26% on projected precision and 0.58% on projected recall.
We applied this metric projector on Cantonese conversational data where only Chinese transcription is available. We projected the actual precision and recall on the general summary when extracting information snippets from MT English translation for scoring, assuming that the English transcription contains error.
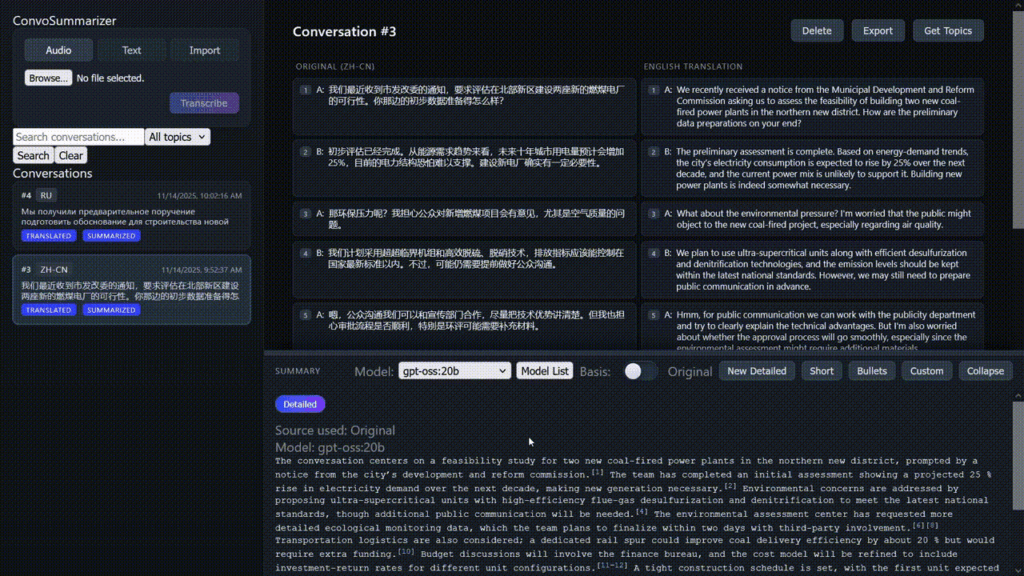
Summary referencing
Sometimes the analyst will find points described in the summary interesting and will want to dig into the detail of what is actually discussed. We provide summary referencing, which displays the part of the conversation that corresponds to a section in the summary. Sentence level and segment level referencing are available. Segment level referencing provides references to the conversation for specific named entities and clause within sentences. This function achieves 93.7% accuracy in our experimental example.
Conclusion
In this project, we proposed a set of metrics to help analysts evaluate summary quality. The metrics consist of two stages of snippet extraction followed by entailment. We showed several successful case studies where our metrics capture missing information from different kinds of machine introduced error, and how people can identify suitable LLMs for deployment given the resource constraints and quality concerns.
Limitations and Future Directions
While our metrics have shown initial success in factually evaluating the summary against the raw conversation transcripts, our snippets extractor currently heavily relies on GPT-4o or GPT-5 which can bias the model’s preference.
In the future, we would like to do a more in-depth study on the current snippet extractor, and identify better replacement to API models. We hope to train a general snippet extractor that can fairly extract snippet statements that are informative for the customized use cases, and in a format that can represent the information for entailment.
There are also more questions we want to answer:
- How does this metric pipeline work on the transcript in its original language?
- How is the quality of the summary of the conversation in original language?
- What is the limit of training data for the ASR, MT and summary models when the summary quality or metrics start to break?
We hope that after the establishment of the metrics, we can continue to expand this framework and address more interesting problems ahead.
This material is based upon work supported in whole or in part with funding from the Department of Defense (DoD). Any opinions, findings, conclusions, or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the DoD and/or any agency or entity of the United States Government.
- Categories: