Findings from the 2024 Data Augmentation for Event Extraction (DAFEE) Project
Parenthetic LLC
Project Overview
Identifying events and the key entities, locations and features that characterize those events can be a useful tool in intelligence analysis, as it supports an intelligence analyst’s ability to address operational objectives such as assessing or predicting potential future actions and threats. The computational extraction of structured events can provide key inputs to forecasting systems and help automate analyst workflows.
The event extraction task is typically supported by a closed-domain (i.e., pre-defined) event ontology (e.g., ACE, CAMEO, ICEWS, IDEA, TAC-KBP, PLOVER) and a corresponding hand-labeled training corpus. In contrast, open domain (i.e., latent variable) models do not require an event ontology or a training corpus, but their model performance is consistently lower. Unfortunately, it is often the case that existing closed-domain event ontologies either do not capture all event types of interest to analysts, or the training corpora developed do not contain enough examples of an event type to train robust models. The effort involved in developing a novel event ontology and training corpus is exceptionally complex, time consuming, expensive, and not conducive to integration with existing analyst workflows. These factors limit the portability of event extraction models, preventing their application in mission-specific contexts.
In our 2023 LAS work [1], Parenthetic developed a domain-specific event extraction framework that hybridizes the benefits found in both closed- (supervised, performant) and open-domain (unsupervised, automated) approaches, by using domain adaptation coupled with data augmentation to train more robust event extraction models on event types of interest (Figure 1). Our 2023 results showed that data augmentation can improve performance of event extraction models and strongly decrease the amount of effort required to model a custom event type of interest with minimal human-in-the-loop involvement. Of all the data augmentation solutions we explored, ChatGPT was a top performer; however, we found that several other methods still showed improved signal when the number of human-labeled “seed” sentences was higher than 30.
In our 2024 LAS work, Parenthetic worked to
- replace ChatGPT with local LLMs to serve air-gapped environments,
- improve the throughput of the pipeline by leveraging Triton and multi-GPU inference and
- develop downstream analytics built from custom event data generated by the pipeline.
The DAFEE Pipeline
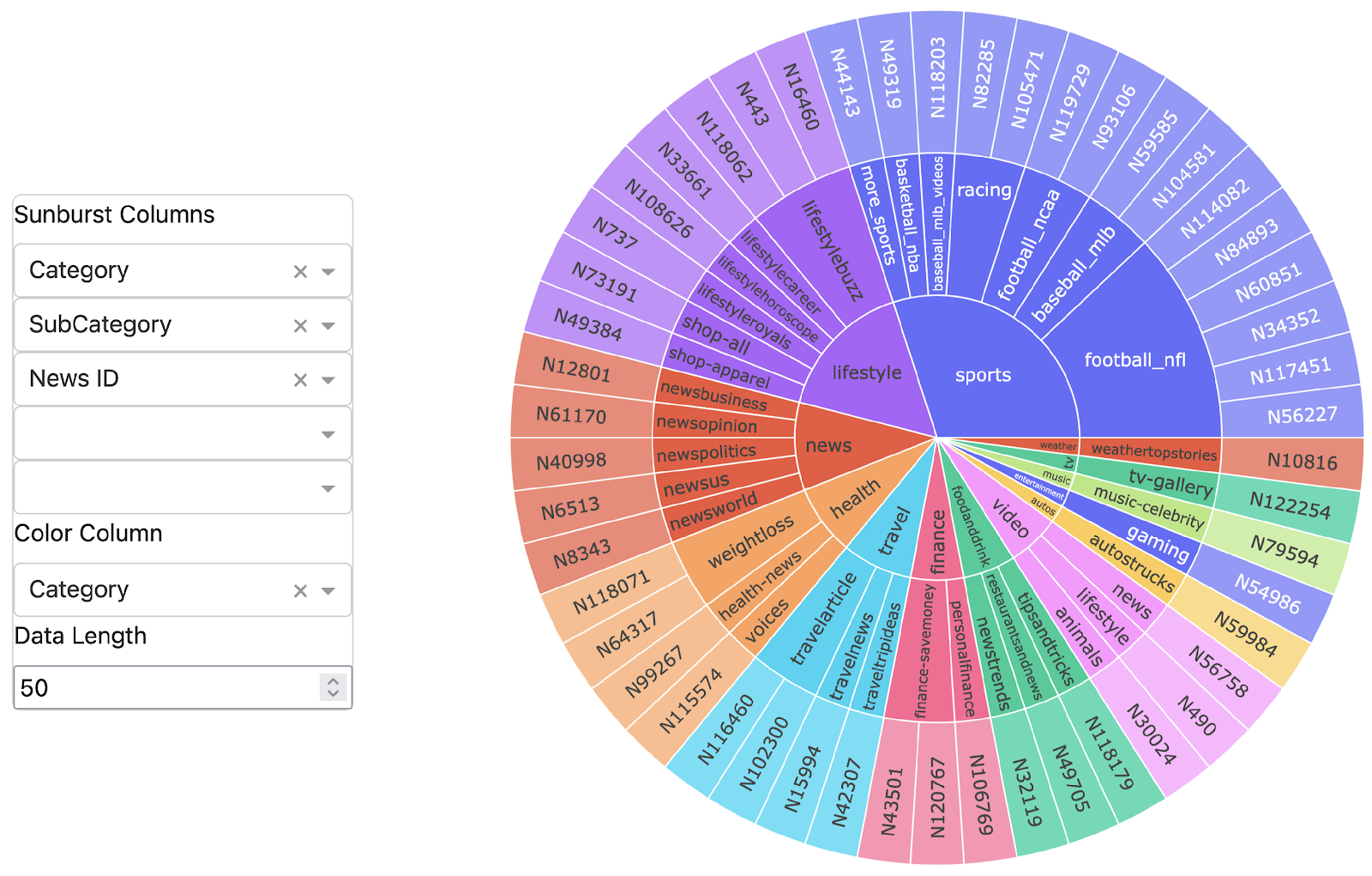
DAFEE is composed of six major modular components (Figure 1), all which were optimized independently:
- a base event extraction model [3],
- sentence-level data augmentation,
- trigger labeling,
- argument labeling,
- a high-quality data filter step, and
- an integrated training phase.
Milestone 1: Make Training Pipeline More Robust & Inference Pipeline Faster
A major goal we had for 2024 was to improve the latency of the inference pipeline so that we could better support quick turn analyses on any scale of input data. By improving batching in the base extractor itself and also leveraging NVIDIA Triton’s ability to leverage multi-GPU compute, we were able to very easily speed up inference to 25x that of our 2023 pipeline (Table 1).
| Version | Compute | # Events | Throughput | Latency (H:M:S) | Total Cost |
| 2023 – Offline batching | g5.xlarge ($1.006/hr) | 5585 | (7.44 s / article) | 7:11:31 | $7.24 |
| 2024 – Offline batching | g5.xlarge ($1.006/hr) | 5585 | (1.20s / article) | 1:09:35 | $1.16 |
| 2024 – 1 GPU Triton | g5.xlarge ($1.006/hr) | 5585 | (1.20s / article) | 1:09:44 | $1.17 |
| 2024 – 4 GPU Triton | g5.12xlarge ($5.672/hr) | 5585 | (0.30s / article) | 0:17:26 | $1.65 |
| 2024 – CPU only Triton | r6i.2xlarge ($0.504/hr) | 5585 | (2.95s / article) | 2:51:04 | $1.44 |
Milestone 2: Replace ChatGPT with local LLMs to Support Air-Gapped Environments
There are two modular components of the DAFEE pipeline that leveraged ChatGPT in our 2023 DAFEE pipeline: the AugmentData and TriggerLabeler modules. Performance comparisons between ChatGPT and local LLM replacements are described for the AugmentData module using heuristic measurements for synthetic data quality, including uniqueness, diversity and latency. Furthermore, the effect of the type of prompting strategy and its relationship to the quality of trigger and argument labeling performed by the various LLM models can be deduced by the downstream performance in the Integrated Training step, also described below.
The AugmentData module
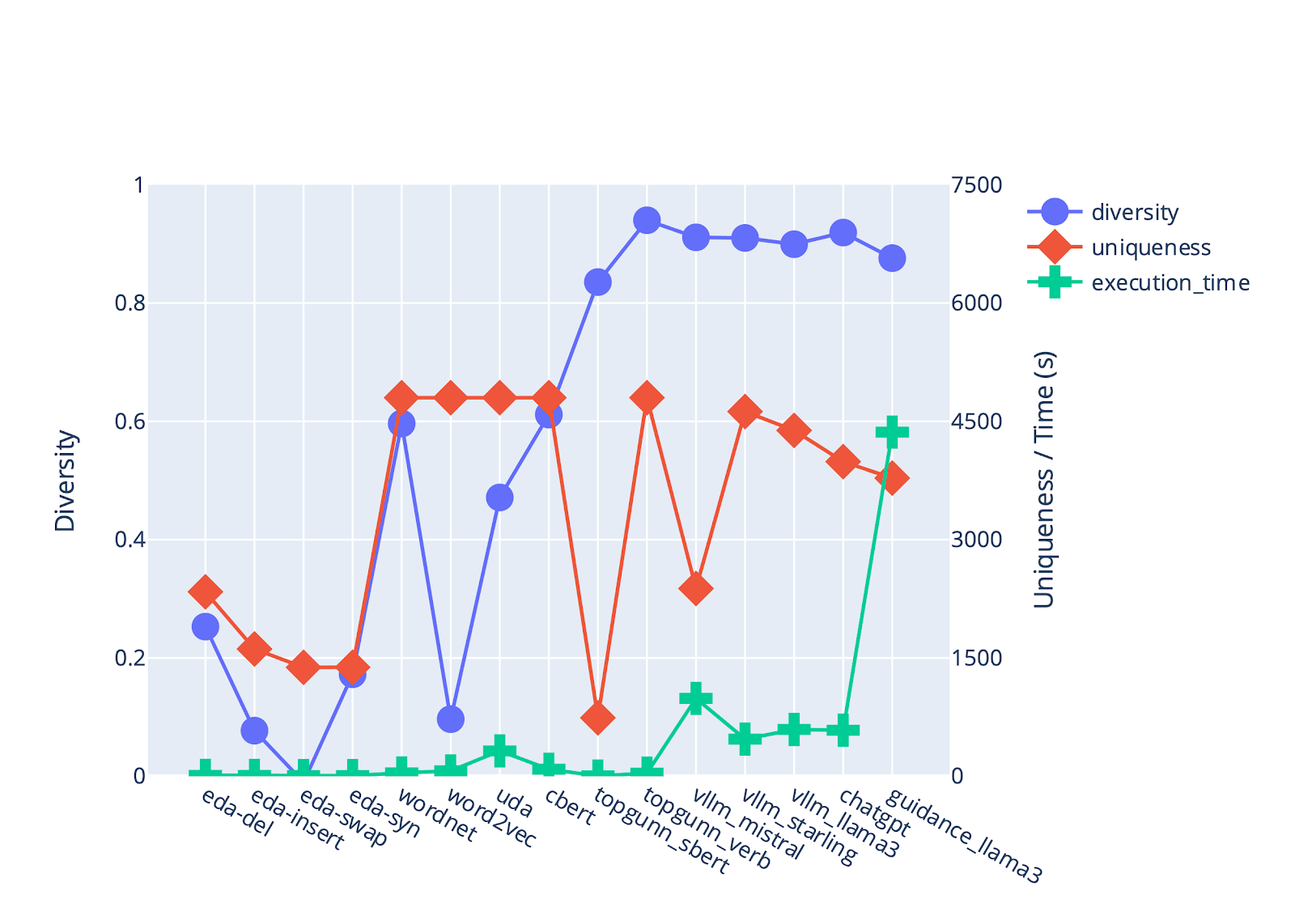
In 2023, the AugmentData module implemented 11 different data augmentation solutions, including several (“naive”) benchmarks as well as several state-of-the-art text-based augmentation methods: 4 EDA flavors [4]; WordNet and Word2Vec [5]; TopGUNN [6]; CBERT [7], DiPs [8], UDA [9], and ChatGPT [2]. In 2024, we looked to see if local LLMs could perform just as well as ChatGPT did at generating novel sentences about a custom event type. Table 2 summarizes each augmentation solution explored and gives an example of an augmented sentence generated from a given seed sentence.
| Method | Example (changes in red) | How It Works |
| Seed Sentence: ByteDance releases CapCut Plugin for ChatGPT | ||
| ChatGPT | AT&T introduces a new mobile phone plan at a telecommunications conference. | Uses the OpenAI API to send requests for augmented versions of the seed sentence. |
| Mistral-7B | Amazon announces the launch of its new Kindle Paperwhite e-reader at an event in Seattle, featuring a longer battery life and waterproof design. | Uses vLLM to directly prompt Mistral-7B. |
| Starling-7B | Apple Inc. launches the new iPhone 13 at the Apple Worldwide Developers Conference held in the San Francisco Convention Center. | Uses vLLM to directly prompt Starling-7B. |
| Llama3-8B | Google announces new Pixel 6 smartphone at its annual hardware event in San Francisco. | Uses vLLM to directly prompt Llama3-8B. |
| Llama3-8B-Guidance | Meta releases Horizon Worlds for Facebook Gaming. | Uses Microsoft Guidance’s context free grammars to prompt Llama3-8B and constrain the generated responses. |
Figure 2 illustrates the strengths and weaknesses of each augmentation method, comparing the diversity, uniqueness and speed at which seedlings are generated. Diversity is defined by 1 minus the average Jaccard similarity between the words in a seed sentence and all augmented sentences generated by a given augmentation method. Uniqueness is defined by how many unique augmented sentences are returned by the augmentation method. The maximum number of generated examples was set to 5000 for the target event type PRODUCT_RELEASE, including the hand-labeled seed sentences (n=32) already provided.
The Integrated Training Step
Figure 3 outlines an experiment where we compare the efficacy of using ChatGPT as a trigger and argument labeling solution compared to using 3 local LLMs that fit onto 1 GPU.
(A) 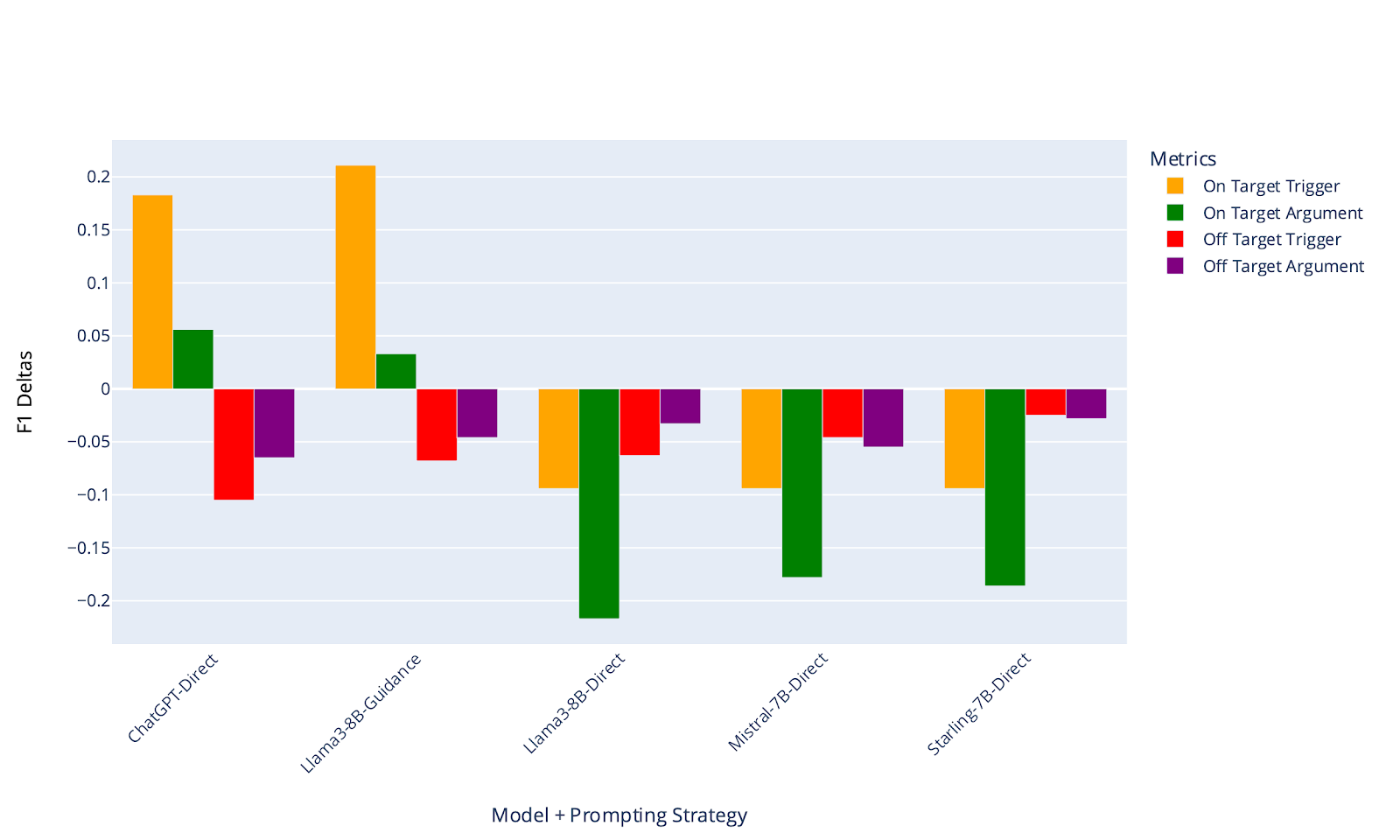 |
(B)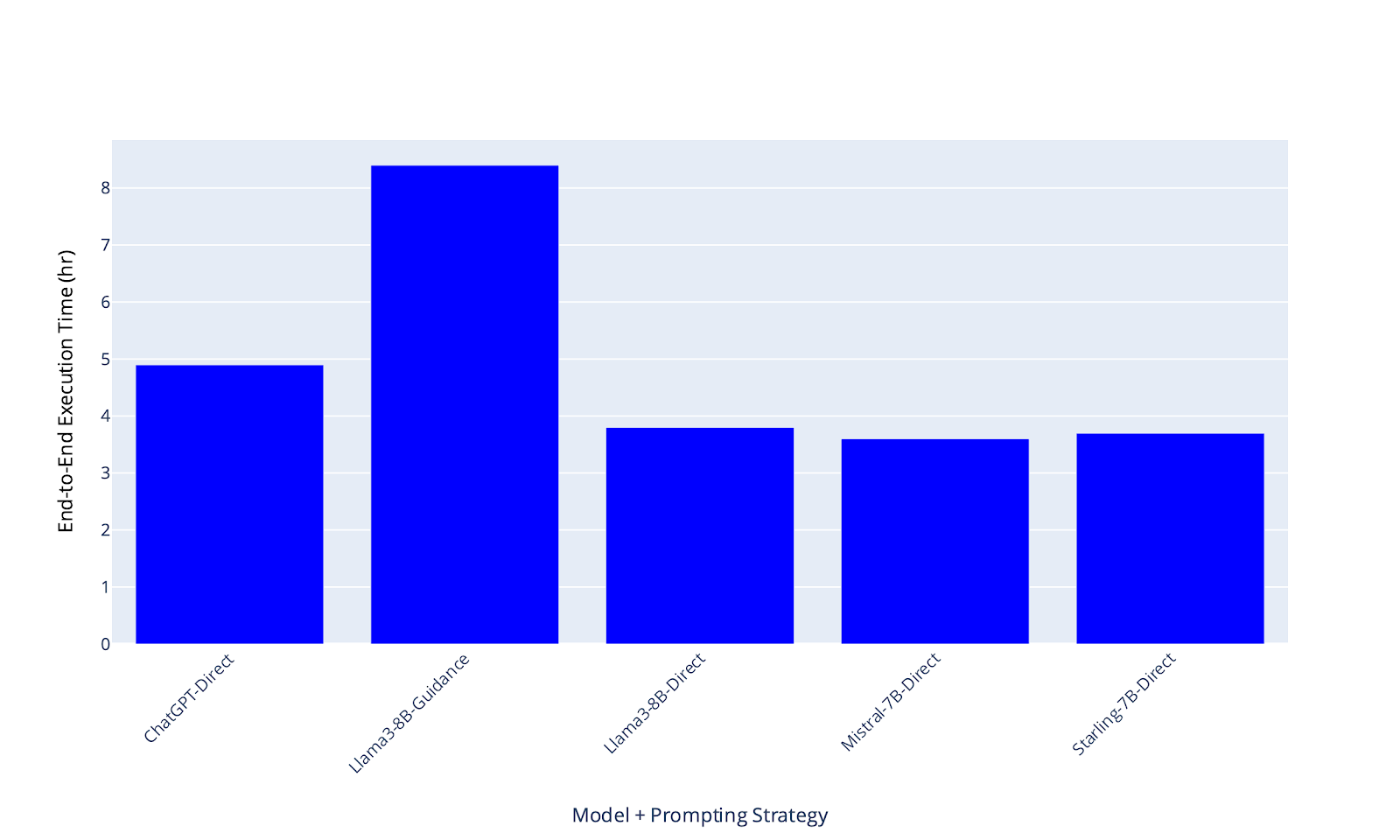 |
(A) On Target and Off Target values are reported as “delta F1” values and are generated by comparing performance gains/losses associated with a run for a given custom event type where no data augmentation was used. Optimal results would contain a strong positive F1 delta for On Target and at worst a minimal negative impact on the Off Target F1 delta values.
(B) End-to-end latencies (Synthetic Data Generation + High Quality Data Filter + Integrated Training) associated with prompting each model using one of two prompting strategies (direct prompting or Microsoft Guidance). While Guidance enabled competitive performance with ChatGPT, it is much slower to generate synthetic examples.
Milestone 3: Develop Downstream Analytics Built from Custom Event Data
In order to showcase the usefulness of event data generated by our pipeline, we developed a number of downstream analytics driven by event data. For this article and in other public forums, we demonstrate these analytics on a space news corpus that we have previously worked with at Parenthetic.
First, we trained a custom event extraction model to model custom events Announce-Award, Rocket-Launch and Conference-Symposium, and then we applied the model on a news corpus where various Space government agencies and officials of interest (e.g., SSC, SDA, SpRCO, and AFRCO) were discussed between January 2019 and July 2024. After doing some basic entity linking by linking mentions of these government agencies and other top actors identified in the corpus with WikiData identifiers, we ingested extracted events into Postgres, and ran the data through 5 downstream analytics, including:
- Event Type Counts Timeseries,
- Key Event Caller,
- Vector Autoregression Model,
- an Event Similarity Tuple Lookup capability (not described), and
- a Network-based Timeseries analytic.
Research questions of interest for this corpus included:
- How are the four agencies presented in the media?
- What event types increase mentions of each agency?
- Are agencies mentioned together?
- What topics come up alongside each agency?
We found that some of our event-based analytics helped answer some of these questions.
Analytic 1: Event Type Counts Timeseries
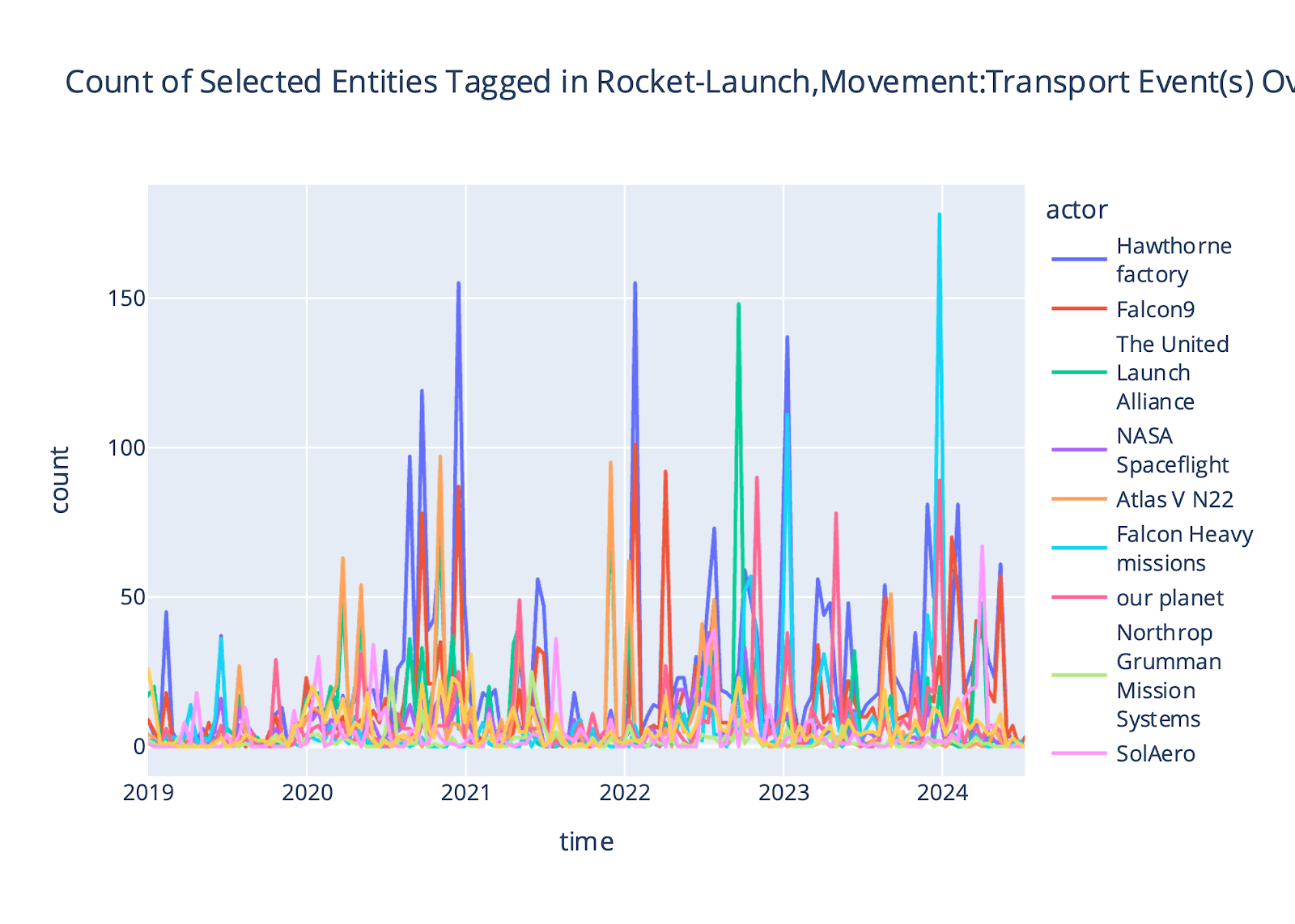
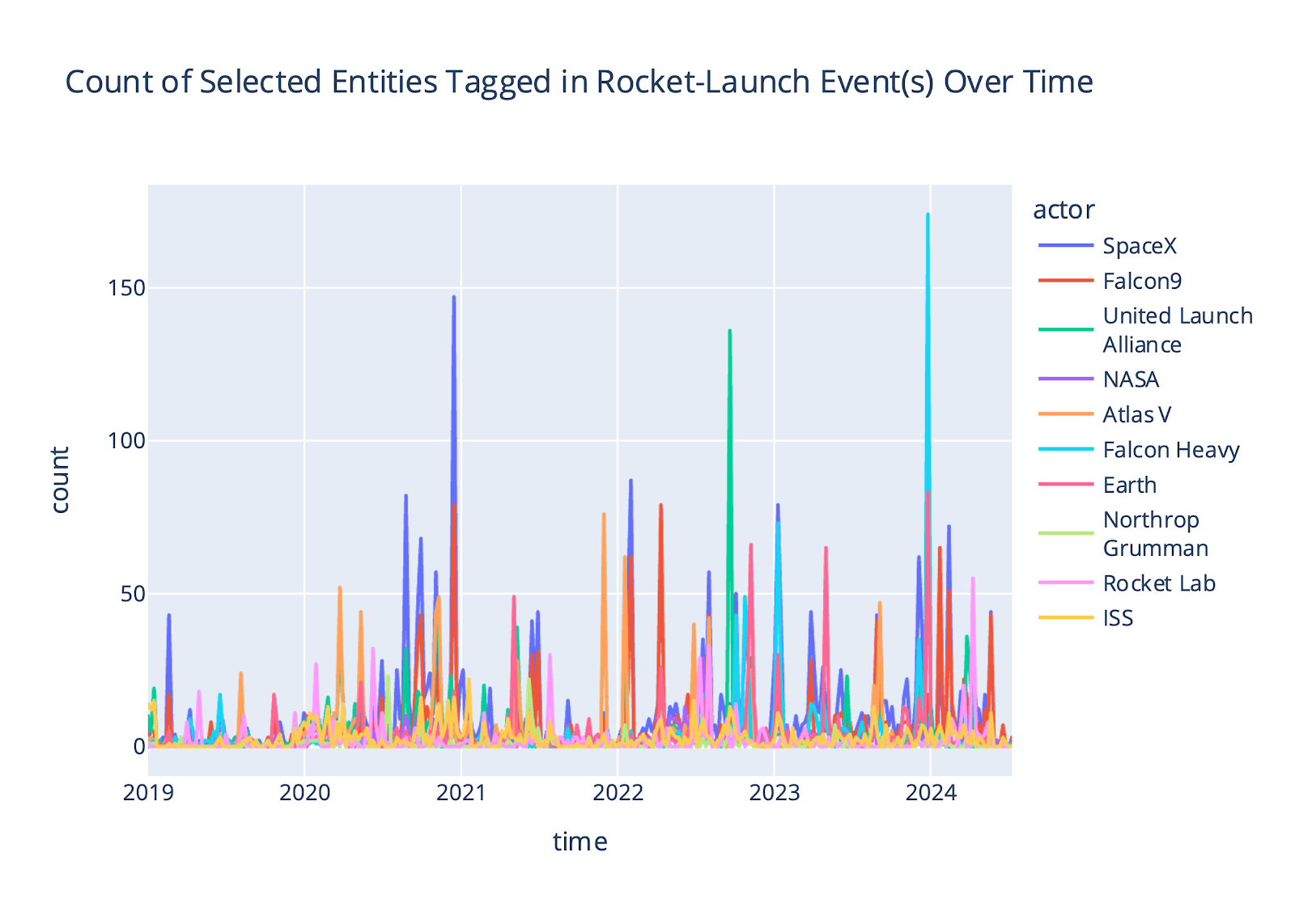
When analyzing basic event type counts (e.g., custom events Announce-Award and Rocket-Launch) for articles ingested in the Space news corpus, we found that when we compared spikes found in events where our entities of interest (EOIs) were tagged (Figure 4a) to spikes in the “baseline” event data (i.e., all events of these types found in the corpus), we could identify two moments in the timeseries where our EOIs were particularly described in the media. This comparison helps analysts identify moments where clients’ communications strategies and campaigns were successfully recognized in the media for their involvement in relevant events. For example, the first Rocket-Launch spike occurred in Nov 2021, when a Space Force (with SSC) had a major rocket launch. The second Announce-Award spike occurred in August 2023, and around that time the SSC announced a large portfolio of awards.
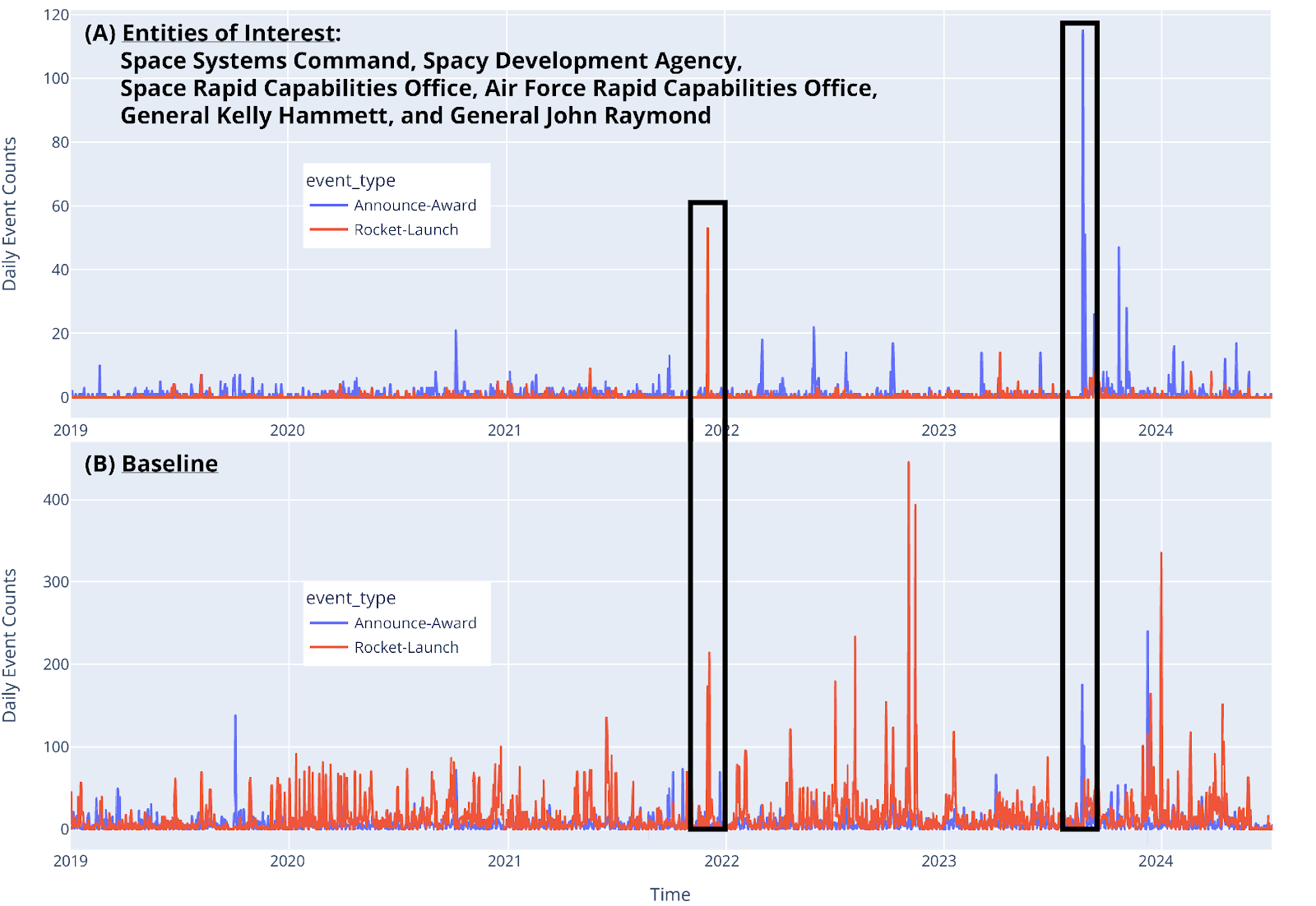
(a) Event counts with EOIs tagged.
(b) Counts of all events.
The two peaks where our EOIs were heavily involved in the communications about awards and rocket launches are highlighted.
Analytic 2: Key Event Caller
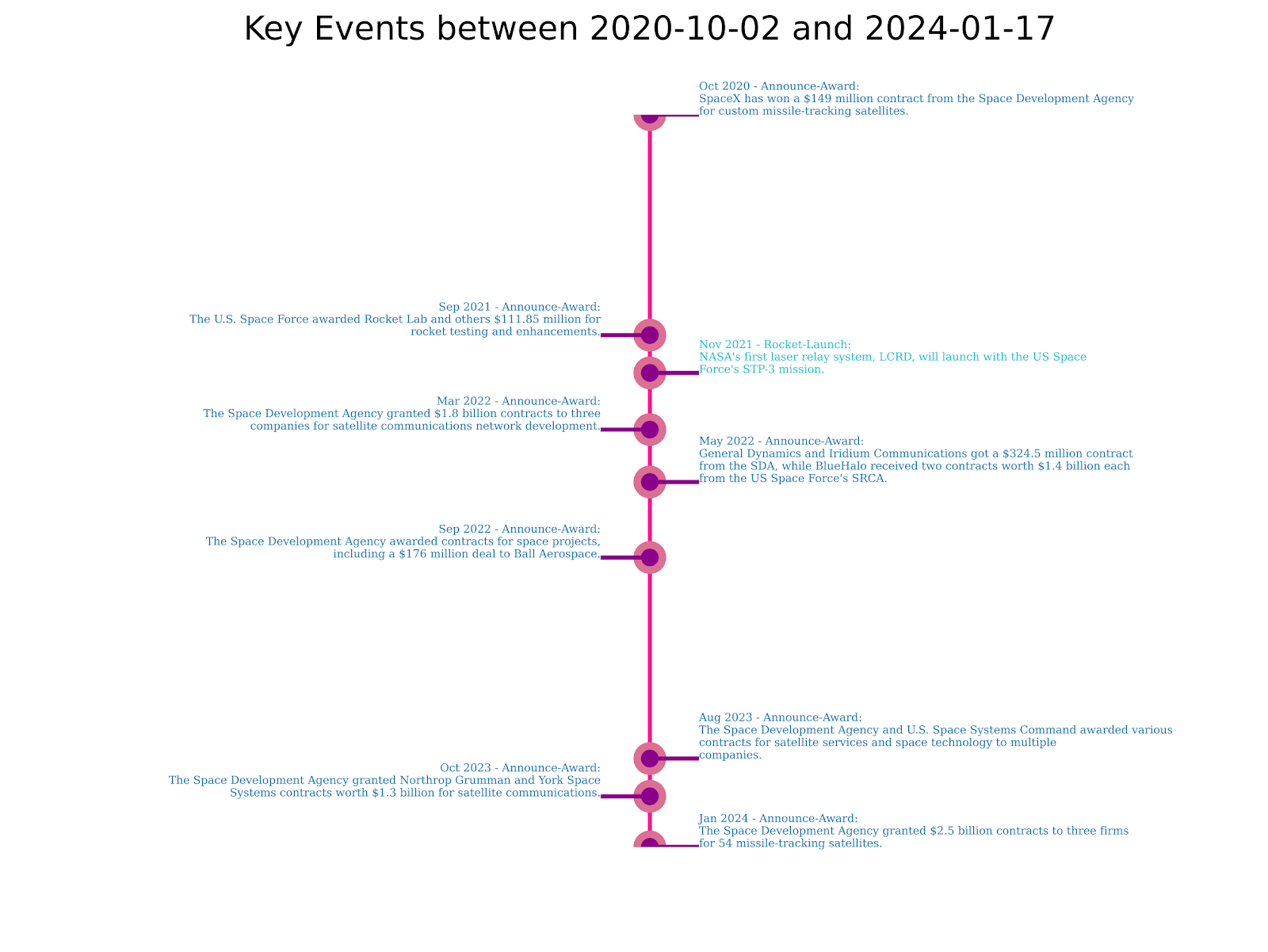
The key event caller takes event data and uses the event types as the “topic” of the event, plotting event counts in a heatmap over time. A change detection algorithm is then leveraged to identify “hot zones” to determine topics that were discussed heavily in a specified time window width (e.g., 7 days). The red rectangles in Figure 5a show the “hot zones” called by the change detection algorithm for events that our EOIs were tagged in (n=3,154) and are represented by a concentrated count in a specific 7-day time window that was >95 percentile. Each event located in a “hot zone” is then sent to an LLM to summarize the text and plot on a timeline as in Figure 5b.
| (A) |
| (B) |
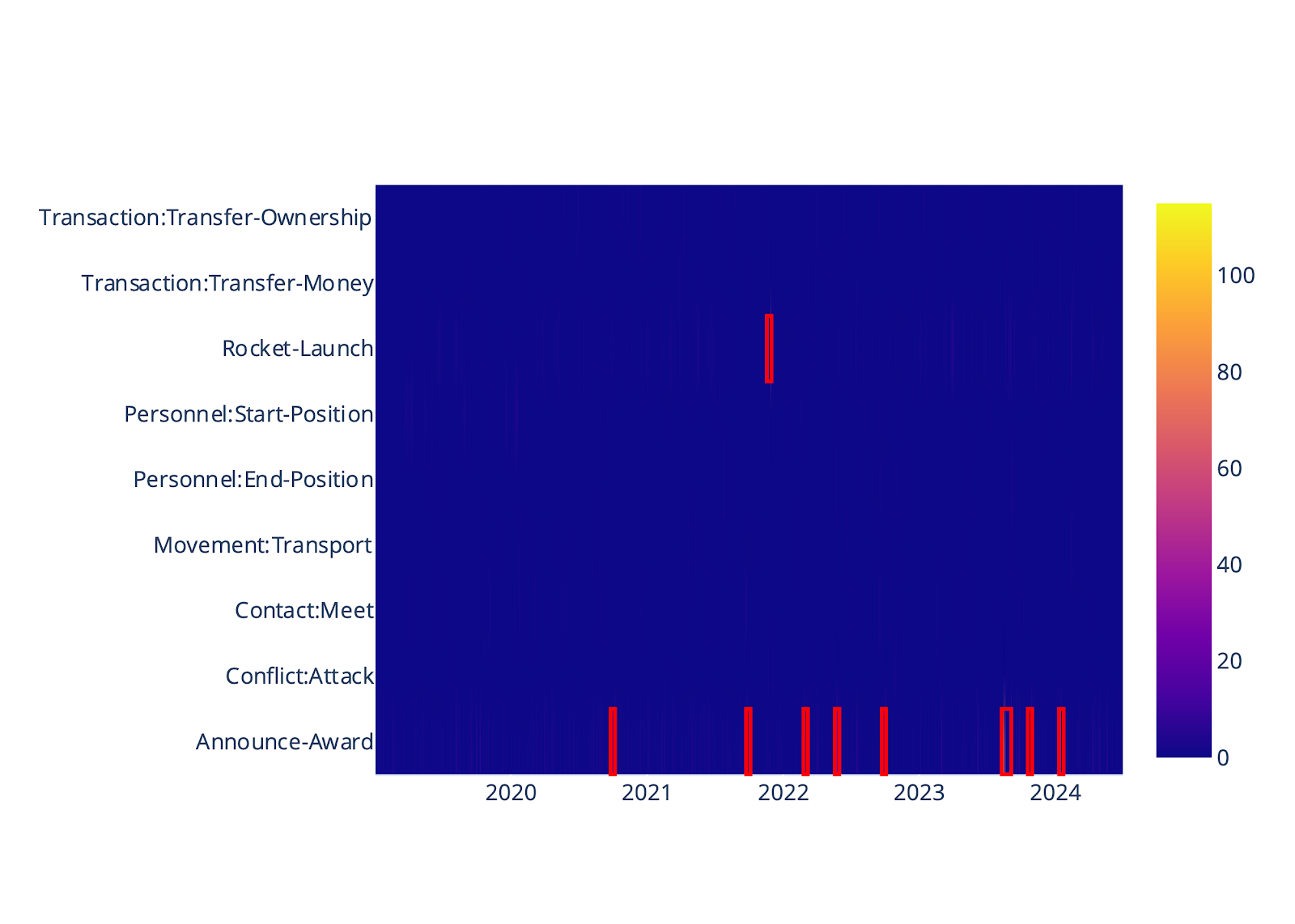
(A) Hot zones detected for specific event types using a change detection algorithm.
(B) Key events are called from the hot zones and events are summarized using an LLM.
Analytic 3: Vector Autoregression Model to Examine Co-occurrence Relationships Between Event Types
Table 3 shows our results from running a vector auto-regression model on the full event dataset (n=108,689) and looking at the relationships between the events with various time delays. In general, relationships with 1 time delay (i.e., L1 is 1 day later) tend to show the most common event type co-occurrences in the data, which is useful for dimensionality reduction between event types, if desired. For example, Rocket-Launch and Movement: Transport appear to be heavily interchangeable in this dataset. Other relationships reflect sensible causality relationships such as a Conflict:Attack predicting a Life: Die event the next day, or a Transaction: Transfer-Ownership or Transaction:Transfer-Money event predicting an Announce-Award event the next day. While this dataset didn’t reveal many dependencies between event types at longer time delays (>1d), this analytic has the capacity to model longer range dependencies when the data supports those trends. Relationships with multiple-hypothesis corrected (Holm) p-values > 0.05, and coefficients between -0.10 and 0.10 were filtered out for brevity.
| Outcome (Y) | Predictor (X) | Coef | P-value |
| Conflict:Attack | L1.Life:Die | 0.351 | 0.000 |
| Contact:Meet | L1.Life:Die | 0.171 | 0.000 |
| Movement:Transport | L1.Rocket-Launch | 0.157 | 0.000 |
| Transaction:Transfer-Money | L1.Business:End-Org | 0.138 | 0.020 |
| Movement:Transport | L1.Life:Die | 0.131 | 0.004 |
| Announce-Award | L1.Transaction:Transfer-Ownership | 0.131 | 0.000 |
| Contact:Phone-Write | L1.Contact:Meet | 0.123 | 0.000 |
| Business:Start-Org | L1.Contact:Meet | 0.106 | 0.000 |
| Personnel:End-Position | L1.Business:Start-Org | -0.111 | 0.003 |
| Contact:Meet | L1.Conflict:Attack | -0.121 | 0.001 |
| Personnel:Start-Position | L1.Business:End-Org | -0.164 | 0.001 |
| Life:Die | L1.Conflict:Attack | -0.247 | 0.000 |
Interpretation of table output: A 1 unit increase in a Predictor at 1 time lag (L1) predicts Outcome at current time, for relationships with a positive coefficient.
Analytic 4: Network Timeseries Analytic
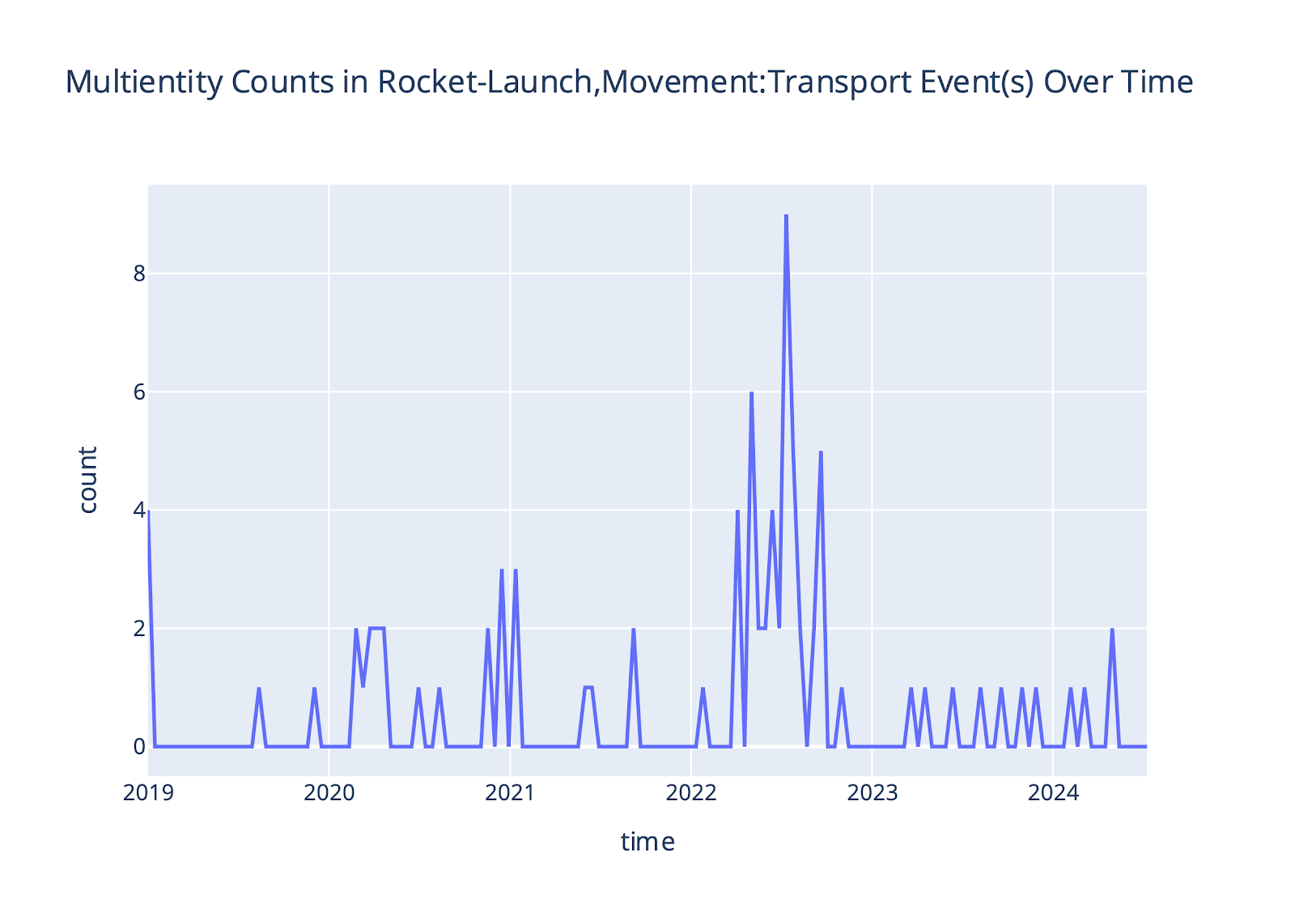
Our last analytic leverages an information-theoretic modularity metric [10] (Figure 6c). When the modularity analytic’s value is compared to a more basic single actor event count (Figure 6a) and direct co-mention count between top actors (Figure 6b), the modularity metric provides more granular information that is directly interpretable. The time window associated with each peak in the modularity analytic provides information on how the top actors were co-mentioned or indirectly linked via intermediate actors in targeted event type’s event data (Figure 6c). In contrast, only examining direct co-mentions (Figure 6b) results in missing important context about intermediate actors that intelligence analysts aren’t specifically looking for. For example, by drilling down on what actors were heavily connected in March 2020, we were able to unveil not only the United Launch Alliance’s Atlas V NASA launch to Mars, but also the launch of the Dragon Demo-2 launch test flight, and the SpaceX Falcon 9 which carried the Dragon spacecraft to the ISS. The Cygnus spacecraft from Northrop Grumman also sent supplies to the ISS and was deorbited at this time (Figure 6c-d).
| (A) Top actors Rocket-Launch Events | |
  | |
| (B) Direct co-mentions | |
 | |
(C) Modularity of Top Actors in Rocket-Launch Events (Direct + Indirect Mentions)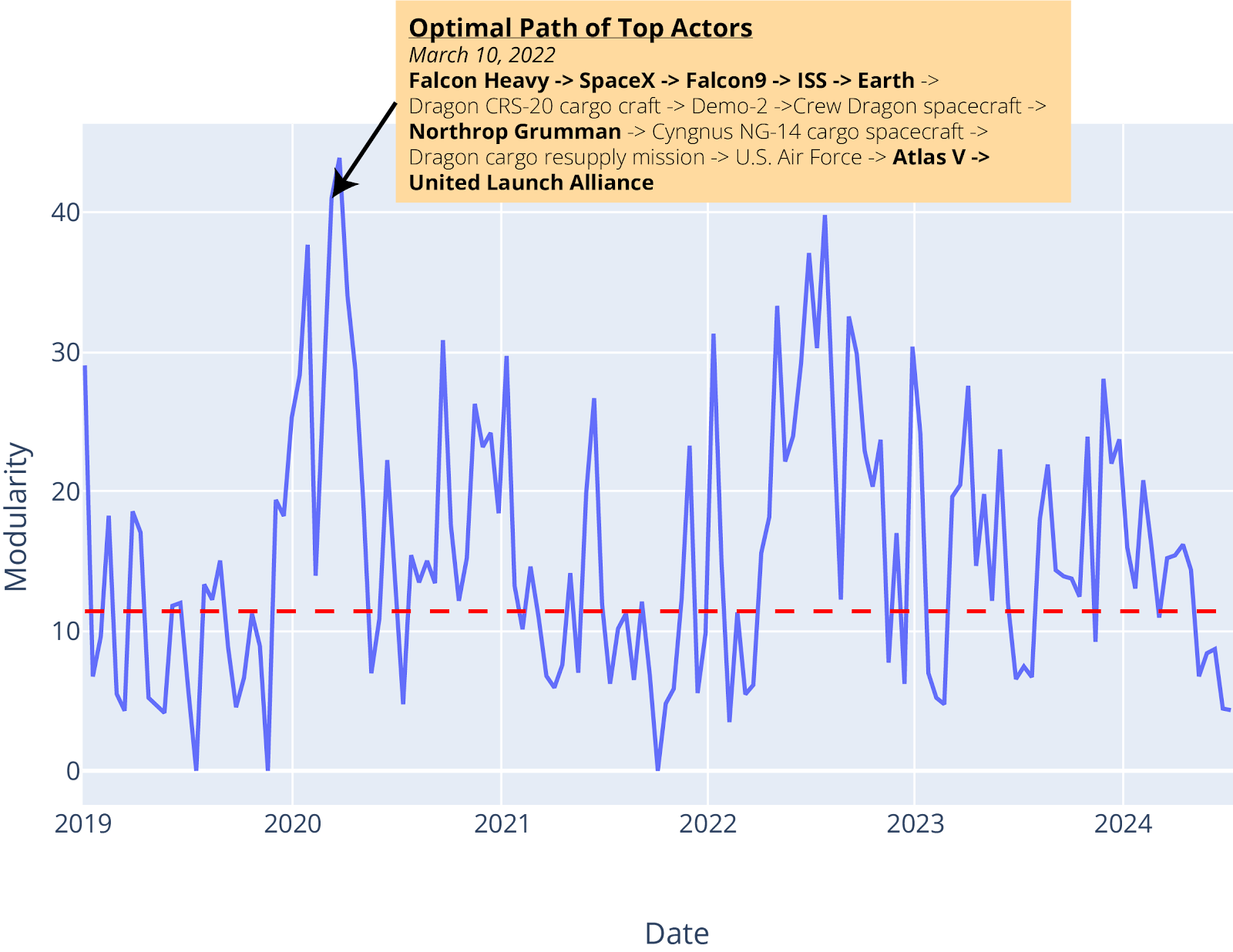 | |
(D) Drilling Down on the March 2020 Time Window in Network View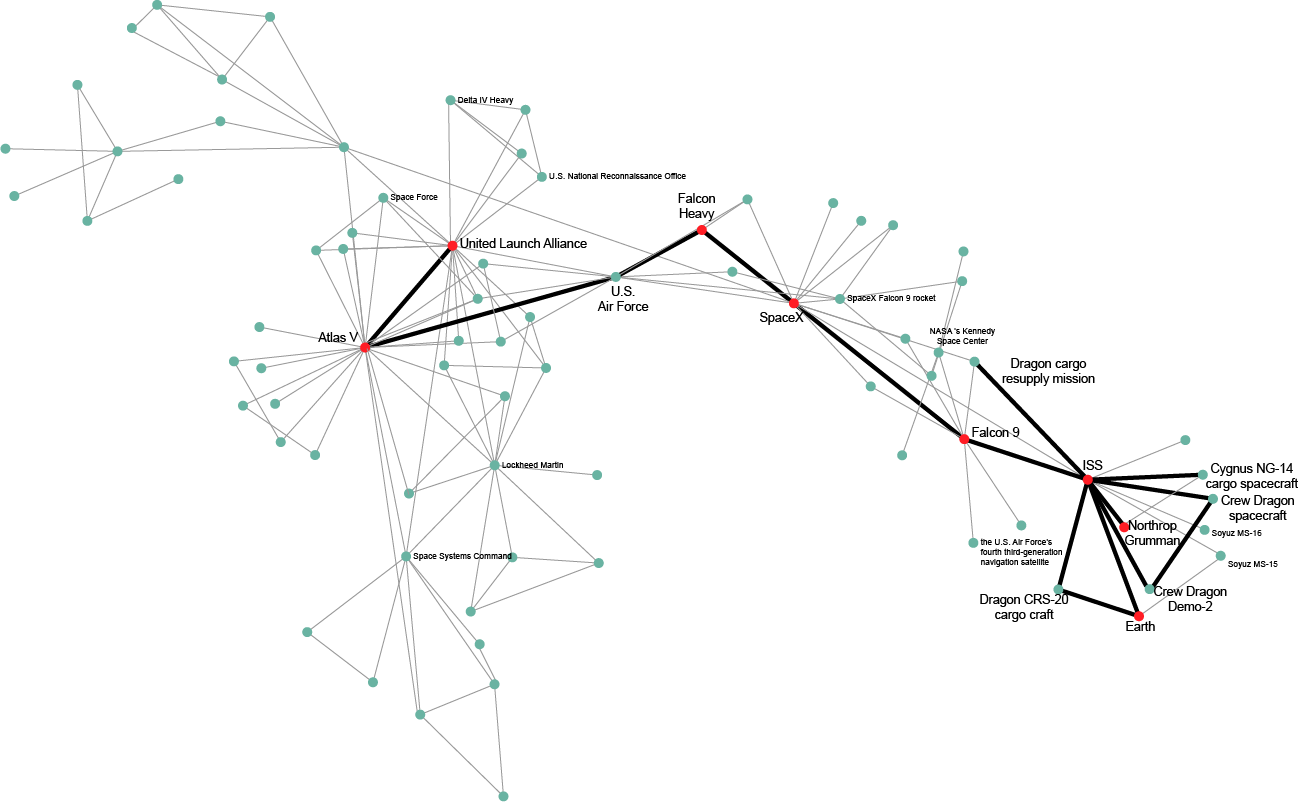 | |
(a) Single entity counts
(b) Multi-entity boolean counts (at least 2 actors present in an event) and
(c) Modularity score of all actors in a time window’s event network. The red dotted line represents a Bonferroni corrected p-value of 0.05. Peaks above this line are considered significant above baseline.
(d) Network details for the March 2020 time window which helps explain why the modularity of top actors (red nodes) peaked.
Conclusions
Our 2023-2024 work with LAS shows that data augmentation can improve performance of event extraction models and strongly decreases the amount of effort required to model a custom event type of interest, with minimal human-in-the-loop involvement. Our results can support LAS application areas such as
- support of the Presidential Daily Brief staff by generating recommendations for event-level summaries of classified documents from a domain or event schema of interest,
- the rapid analysis of technical or classified documents to assess adversary capabilities and develop countermeasures,
- more rapid, human-in-the-loop tearline report generation in the particular context of structured extraction rules applied to classified documents.
Especially for proprietary or classified communications, having a custom extraction pipeline for event types or topics of interest, and a means to summarize events for analysts, will drastically improve the scale and depth by which analysts can ingest and generate knowledge for the intelligence community.
We found the best performing solution overall to be ChatGPT but that with the right prompting strategy, equal performance could be observed using local LLMs to serve air-gapped environments. Bulking up a training dataset using data augmentation with local LLMs gave us the performance we sought on custom event types in a domain of interest, without the drawbacks of cost and lack of data privacy associated with an API-based model like ChatGPT.
This material is based upon work done, in whole or in part, in coordination with the Department of Defense (DoD). Any opinions, findings, conclusions, or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the DoD and/or any agency or entity of the United States Government.
References
- [1] Findings from the Data Augmentation for Event Extraction (DAFEE) Project. https://ncsu-las.org/2023/12/title-findings-from-the-data-augmentation-for-event-extraction-dafee-project/
- [2] OpenAI. (2023). ChatGPT. https://chat.openai.com/chat
- [3] Mingyu Derek Ma, Jiao Sun, Mu Yang, Kung-Hsiang Huang, Nuan Wen, Shikhar Singh, Rujun Han, Nanyun Peng. 2021. EventPlus: A Temporal Event Understanding Pipeline. arXiv:2101.04922, 1-10.
- [4] Wei J., Zou, K. 2019. EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks. arXiv:1901.11196v2, 1-9.
- [5] Marivate V., Sefara T. 2020. Improving Short Text Classification Through Global Augmentation Methods. Machine Learning and Knowledge Extraction, 385-399.
- [6] Iglesias-Flores, R., Mishra, M., Patel, A., Malhotra, A., Kriz, R., Palmer, M., Callison-Burch, C. 2021. TopGuNN: Fast NLP Training Data Augmentation using Large Corpora. In Proceedings of the Second Workshop on Data Science with Human in the Loop: Language Advances, 86–101. Association for Computational Linguistics.
- [7] Wu X, Lv S, Zang L, Han J, Hu S. 2018. Conditional BERT contextual augmentation. arXiv:1812.06705.
- [8] Kumar A., Bhattamishra S., Bhandari M., Talukdar P. 2019. Submodular Optimization-base Diverse Paraphrasing and its Effectiveness in Data Augmentation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 1: 3609-3619.
- [9] Xie Q., Dai Z., Hovy E., Luong M-T., Le Q.V. 2019. Unsupervised Data Augmentation for Consistency Training. arXiv:1904.12848.
- [10] Thistlethwaite L.R., Petrosyan V., Li X., Miller M.J., Elsea S.H., Milosavljevic A. (2021). CTD: An information-theoretic algorithm to interpret sets of metabolomic and transcriptomic perturbations in the context of graphical models. PLOS Computational Biology, 10.1371/journal.pcbi.1008550.
- Categories: