Findings from the Data Augmentation for Event Extraction (DAFEE) Project
Parenthetic LLC
Project Overview
Identifying events and the key entities, locations and features that characterize those events can be a useful tool in intelligence analysis, as it supports an intelligence analyst’s ability to address operational objectives such as assessing or predicting potential future actions and threats. The computational extraction of structured events can provide key inputs to forecasting systems and help automate analyst workflows.
The event extraction task is typically supported by a closed-domain (e.g., pre-defined) event ontology (e.g., ACE, CAMEO, ICEWS, IDEA, TAC-KBP, PLOVER) and a corresponding hand-labeled training corpus. In contrast, open domain (i.e., latent variable) models do not require an event ontology or a training corpus, but their model performance is consistently lower. Unfortunately, it is often the case that existing closed-domain event ontologies either do not capture all event types of interest to analysts, or the training corpora developed do not contain enough examples of an event type to train robust models. The effort involved in developing a novel event ontology and training corpus is exceptionally complex, time consuming, expensive, and not conducive to integration with existing analyst workflows. These factors limit the portability of event extraction models, preventing their application in mission-specific contexts.
In our 2023 LAS work, Parenthetic developed a domain-specific event extraction framework that hybridizes the benefits found in both closed- (supervised, performant) and open-domain (unsupervised, automated) approaches, by using domain adaptation [1] coupled with data augmentation to train more robust event extraction models on event types of interest. At the time we proposed our 2023 contract work, the cutting edge for event extraction was largely composed of small transformer-based neural methods. However, since then ChatGPT [2] and its competitors have emerged. A preliminary study of ChatGPT’s efficacy for augmenting event extraction training datasets, and its competency as a zero-shot event extraction model itself, was conducted during 2023 LAS contract work, alongside several other data augmentation solutions that were considered cutting edge prior to the release of ChatGPT. In total, DAFEE performs event extraction with custom event types from a niche set of communications (Figure 1).
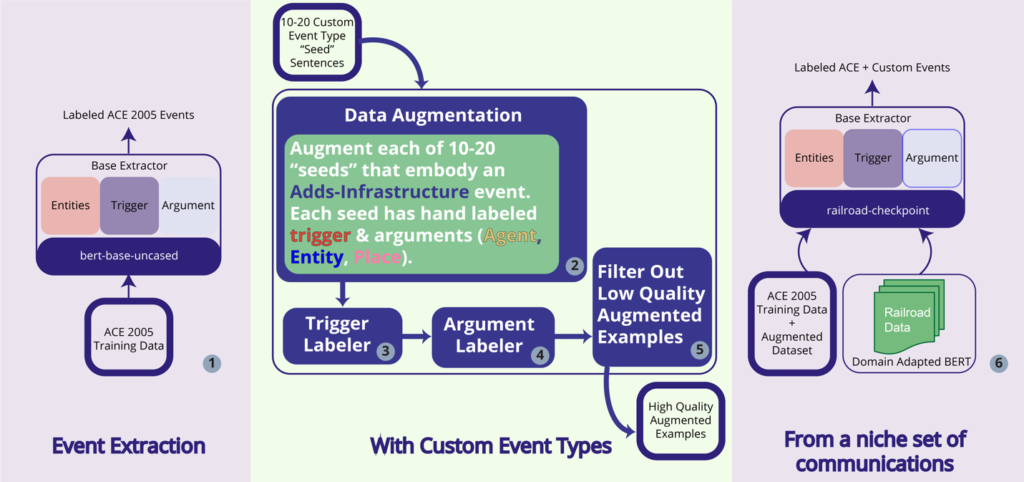
The DAFEE Pipeline
DAFEE is composed of six major modular components (Figure 1), all which were optimized independently:
- a base event extraction model [3]
- sentence-level data augmentation
- trigger labeling
- argument labeling
- a high-quality data filter step and
- an integrated training phase.
(1) Baseline Learning (No Augmentation) Using a Base Event Extraction Model
Domain Adaptation of a Pre-trained Encoder via Continued Pretraining
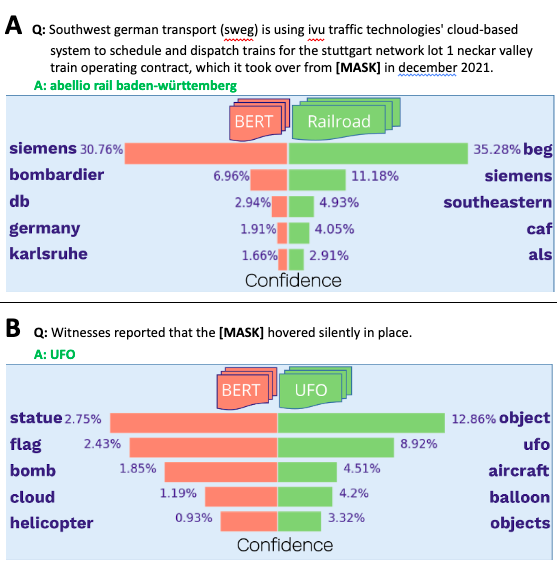
Using fill-mask modeling, an NLP task where a subset of words in a sentence are “masked” and the model predicts what the masked words are, we continued training starting from a pre-trained BERT model checkpoint (bert-base-uncased), using domain-specific corpi from: i) the railroad industry and ii) a UFO dataset. For both domain adaptation experiments, top predictions for a masked word in an example sentence shows striking improvements in the domain adapted checkpoint as compared to a pre-trained BERT model (Figure 2). For example, the top prediction for the masked example using the Railroad industry’s domain adapted checkpoint was “beg”, which is an acronym for “Bayerische Eisenbahngesellschaft”, a leading competitor of “Abellio Rail Baden-Würtemberg”, the correct answer in Figure 2a. Furthermore, the correct answer for the masked example from the UFO dataset was “ufo” and was ranked second in the predictions from the UFO domain adapted checkpoint in Figure 2b. Not only are the predictions more accurate using the domain-adapted checkpoints, but they are also more confident as compared to the predictions made by bert-base-uncased.
When comparing performance of the event extraction task on event types composing the 2005 ACE event dataset, all three “flavors” of BERT checkpoints performed similarly overall, but for some event types in particular, performance can be drastically affected (Figure 3).

(2) The AugmentData module
The AugmentData module implements 11 different data augmentation solutions, including several (“naive”) benchmarks as well as several state-of-the-art text-based augmentation methods: 4 EDA flavors [4]; WordNet and Word2Vec [5]; TopGUNN [6]; CBERT [7], DiPs [8], UDA [9], and ChatGPT [2]. We also looked at a few “latent variable” perturbation methods but found they did not perform well for our complex token-level label space. Table 1 summarizes each augmentation solution explored and gives an example of an augmented sentence generated from a given seed sentence.
Table 1. Comparison of augmentation solutions explored by the DAFEE pipeline. The seed sentence was selected from news articles from the railroad industry and embodies the Adds-Infrastructure event type.
| Method | Example (changes highlighted) | How It Works |
| Seed Sentence: Dortmund Railway takes delivery of its first Vectron Dual Mode locomotive | ||
| EDA deletion | Dortmund Railway delivery Vectron Dual Mode | A random selection of words is deleted. |
| EDA insert | Dortmund Railway engine takes delivery of its first Vectron Dual Mode locomotive | A random selection of words is inserted. |
| EDA swap | Dortmund Mode takes delivery of its first Vectron Dual Railway locomotive | A random selection of words is swapped. |
| EDA synonym | Dortmund Railway acquire delivery of its first Vectron Dual Mode locomotive | A random selection of words is replaced using a synonym lookup (wordnet). |
| WordNet | dortmund railroad takes bringing of its first vectron dual fashion locomotive | Similar to EDA-synonym but targets only nouns or verbs. |
| Word2vec (glove) | Dortmund Railway takes delivery of its first Vectron Dual Mode carriages | Similar to EDA-synonym but uses token similarity and pre-trained glove embeddings instead of synsets. |
| UDA | Dortmund Railway acquires first Vectron Dual Mode Locomotive | Translates the sentence into German and then back into English, with beam search to allow for variation in responses. |
| CBERT | dortmund first takes delivery of iraqi first vectron dual mode locomotive | Using a conditional masked language modeling, a random selection of words is masked and a BERT-based model predicts the missing words conditional on the event type label. |
| TopGUNN | RAIL Cargo Hungary (RCH) has taken delivery of a hybrid battery-powered shunting locomotive from CRRC Zhuzhou of China. | Uses sentence similarity (TopGUNN SBERT) to find similar sentences to the seed sentence. Alternatively, you can choose to compare contextual word embeddings of the candidate sentences’ verbs and do token similarity with the seed’s trigger word (TopGUNN VERB). |
| DiPs | Dortmund Train takes delivery first double locomotive type single power engine in Dortmund for two consecutive decades following deliveries of the Vevtor 4G series | Uses a text summarization model to generate highly likely sentences given a starting token sequence taken from a seed sentence. |
| ChatGPT | The city of Los Angeles announces plans to build a new subway line connecting downtown to the airport. | Uses the OpenAI API to send requests for augmented versions of the seed sentence. |
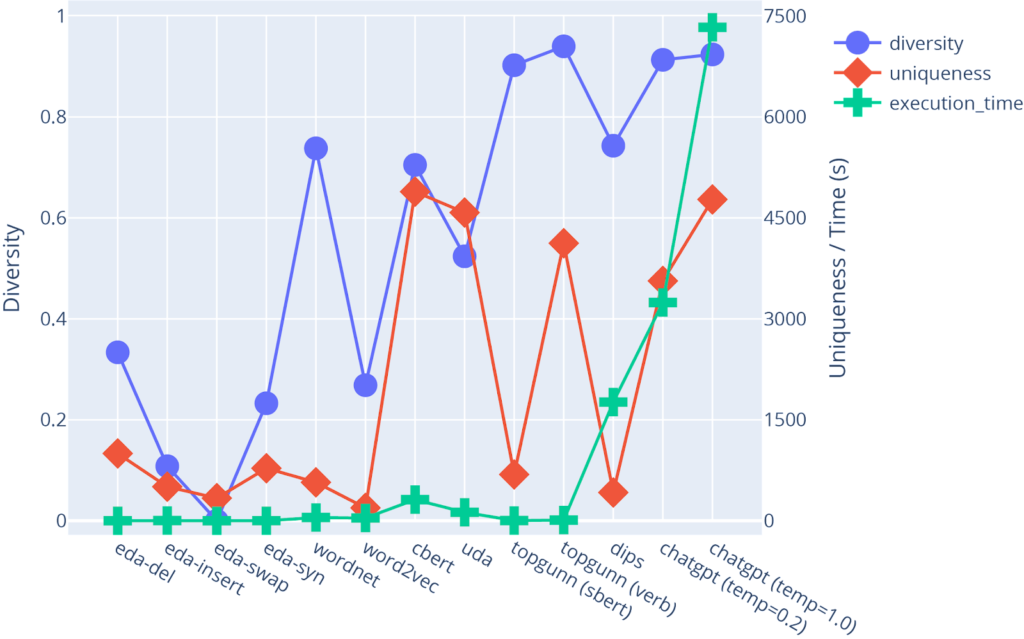
Figure 4 illustrates the strengths and weaknesses of each augmentation method, comparing the diversity, uniqueness and speed at which seedlings are generated. Diversity is defined by 1-the average Jaccard similarity between the words in a seed sentence and all augmented sentences generated by a given augmentation method.
Uniqueness is defined by how many unique augmented sentences are returned by the augmentation method. The maximum number of generated examples was set to 5000 for the target event type Adds-Infrastructure, including the hand-labeled seed sentences (n=14) already provided. Because some augmentation methods are limited by the number of available combinations of words that can be swapped in/out in a seed sentence, these augmentation methods do not reach this maximum uniqueness value, and thus have lower uniqueness as compared to alternative augmentation methods. Because many of our analyst-provided seed sentences were taken from article titles which tend to be shorter length than full sentence article text, we saw even more drops in the uniqueness levels for several of our “benchmark” augmentation methods (e.g., all EDA flavors, WordNet, Word2Vec). Two other more “state of the art” methods, TopGUNN (SBERT) and DiPs, had lower uniqueness values for other reasons having to do with constraints we put on the size of the vector storage database we were using to test TopGUNN (#records ~100,000) and for DiPs, the algorithmic complexity was high enough that we only allowed a maximum of 50 seedlings per seed to be generated (a constraint that is configurable). These constraints can be relaxed with changes to the implementation we currently have in production and are still being considered.
(3) The TriggerLabeler and (4) ArgumentLabeler Modules
For the TriggerLabeler module, our benchmark solution (“token_sim”) used a token similarity approach based on word embedding similarity between the labeled seed sentence trigger and words in the augmented sentence. For the ArgumentLabeler module, our benchmark solution (“cands_by_schema”) leveraged the pre-defined event schema and known mappings to named entity categories in order to identify and filter candidate arguments based on detected entities in augmented sentences.
Table 2 outlines an experiment where we compare the efficacy of using both benchmarks to performance gains associated with using ChatGPT as a trigger and argument labeling solution. For these experiments, we used ChatGPT as the data augmentation method for all runs and only modified the trigger and argument solutions (token_sim/cands_by_schema vs. ChatGPT). We found that while the ChatGPT trigger/argument labeling solution took a longer time to label examples (i.e., approximately twice as long), performance was vastly improved for event types of interest with very little number of human-labeled seed sentences (e.g., Adds-Infrastructure n=14; and Tests n=7) (Table 2). What’s encouraging, however, is that our benchmark trigger and argument labeling strategies seemed to be sufficient for finding signal in the Product-Release event type, whose number of human-labeled seed sentences was n=32.
Table 2. Comparison of trigger and argument labeling solutions for the novel event types, “Tests”, “Adds-Infrastructure”, and “Product-Release”. On Target and Off Target values are reported as “delta F1” values, and are generated by comparing performance gains/losses associated with a run for a given custom event type where no data augmentation was used. Optimal results would contain a strong positive F1 delta for On Target and at worst a minimal negative impact on the Off Target F1 delta value.
| Event Type | Labeling Strategy | End-to-End Execution Time (hr) | On Target | Off Target |
| Tests | token_sim + cands_by_schema | 4.0 | 0.000 | -0.0027 |
| ChatGPT | 9.1 | 0.500 | 0.0014 | |
| Adds-Infrastructure | token_sim + cands_by_schema | 3.7 | 0.000 | -0.0066 |
| ChatGPT | 10.8 | 0.333 | -0.0604 | |
| Product-Release | token_sim + cands_by_schema | 3.8 | 0.259 | 0.0185 |
| ChatGPT | 8.2 | 0.159 | 0.0307 |
(5) The High-Quality Data Filter Step
It has been shown that the quality of augmented data can be just as important as quantity, and that augmented data that is too homogeneous does not improve the predictive power of resulting models [10]. Thus, balancing the need for heterogeneity (i.e., “diverse” augmented examples) with noise (i.e., incorrect labeling of augmented examples) is key for identifying an optimal data augmentation and trigger+argument labeling approach. As a result, the High-Quality Data Filter step takes the automatically labeled, augmented data generated by steps 2-4 and identifies examples that have high misclassification rates using the benchmark event extractor from step 1, prior to integration with the ACE 2005 corpus (step 6).
We did an experiment using LAS’s InfinityPool labeling service, where we compared sets of random samples of augmented sentences generated by steps 2-4 to a random set of augmented sentences that survived the High-Quality Data Filter and found the augmented sentences that survived the filter to be of higher quality than the random sample on all generated sentences. While examining this filter, we found that each data augmentation method required slightly different treatment. For example, augmented sentences generated the “naive” EDA flavors are filtered out if an example is not classified correctly in a percentage of the training epochs during the high quality filter training phase. However, with more intelligent methods such as ChatGPT, TopGUNN and DiPs, only the last epoch’s training performance is evaluated and low-quality examples are identified based on a low token-level F1 score. While this element of our pipeline is still considered experimental, we are encouraged by its general aptitude for automatically identifying low quality augmented examples.
(6) The Integrated Training Step
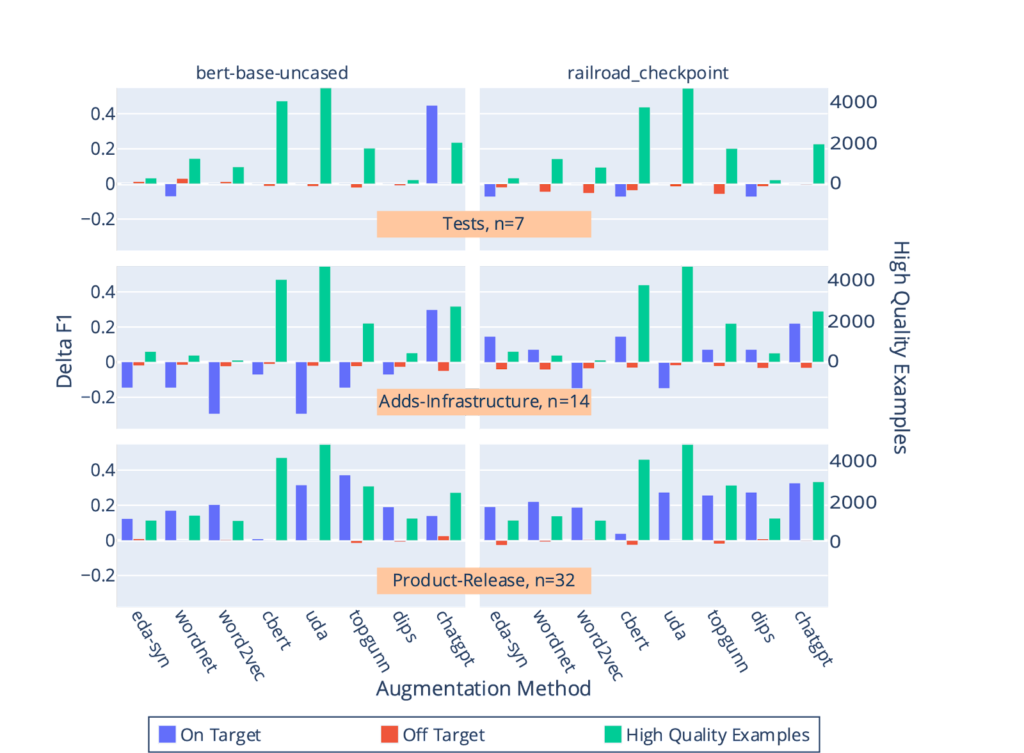
The output of the pipeline are high quality augmented examples of a target event type, which gets integrated with the ACE 2005 event dataset for a final “integrated” training step with the base extraction model. When compared to baselines (training runs where no data augmentation was used), we found that the high-quality augmented sentences improved final performance in the integrated training step for all three novel event types, including event types with very few human-labeled “seed” sentences (Figure 5). ChatGPT was consistently a top performer, but surprisingly, several other augmentation methods showed strong signal for event types with at least ~14 seed sentences as input. Interestingly, the domain adapted checkpoint, railroad_checkpoint, seemed to help several augmentation methods show signal in event types with at least 14 hand labeled “seed” sentences, but was not helpful for the Tests event type which had only 7 seed sentences.
Conclusions
Our 2023 work with LAS shows that data augmentation can improve performance of event extraction models and strongly decrease the amount of effort required to model a custom event type of interest with minimal human-in-the-loop involvement. Our results can support LAS application areas such as
- support of the Presidential Daily Brief staff by generating recommendations for event-level summaries of classified documents from a domain or event schema of interest
- the rapid analysis of technical or classified documents to assess adversary capabilities and develop countermeasures
- more rapid, human-in-the-loop tearline report generation in the particular context of structured extraction rules applied to classified documents.
Especially for proprietary or classified communications, having a custom extraction pipeline for event types or topics of interest, and a means to summarize events for analysts, will drastically improve the scale and depth by which analysts can ingest and generate knowledge for the intelligence community.
We found the best performing solution overall to be ChatGPT as both a trigger and argument labeling solution, as well as a sentence-level data augmentation solution. However, we found that several other methods for both trigger and argument labeling as well as data augmentation still showed improved signal when the number of human-labeled “seed” sentences was higher than 30. We also concluded that while one can certainly rely on ChatGPT to label all novel event types of interest, the main drawbacks are the low throughput associated with an API-based model, and high cost of performing inference at scale. Bulking up a training dataset using data augmentation gave us the performance we sought on custom event types in a domain of interest, without the drawbacks of cost and throughput associated with an API-based model like ChatGPT. Future work will examine local (i.e., non-proprietary) LLMs as an alternative to ChatGPT and the augmentation solutions examined in this report, as well as start formalizing the events extracted by our pipeline into an event-centric knowledge graph purposed to assist analysts in creating clean, relevant time-based analytics for events of interest.
References
[1] Gururangan S., Marasovi A., Swayamdipta S., Lo K., Beltagy I., Downey D., and Smith N.A. 2020. Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 8342-8360. Association for Computational Linguistics.
[2] OpenAI. (2023). ChatGPT. https://chat.openai.com/chat
[3] Mingyu Derek Ma, Jiao Sun, Mu Yang, Kung-Hsiang Huang, Nuan Wen, Shikhar Singh, Rujun Han, Nanyun Peng. 2021. EventPlus: A Temporal Event Understanding Pipeline. arXiv:2101.04922, 1-10.
[4] Wei J., Zou, K. 2019. EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks. arXiv:1901.11196v2, 1-9.
[5] Marivate V., Sefara T. 2020. Improving Short Text Classification Through Global Augmentation Methods. Machine Learning and Knowledge Extraction, 385-399.
[6] Iglesias-Flores, R., Mishra, M., Patel, A., Malhotra, A., Kriz, R., Palmer, M., Callison-Burch, C. 2021. TopGuNN: Fast NLP Training Data Augmentation using Large Corpora. In Proceedings of the Second Workshop on Data Science with Human in the Loop: Language Advances, 86–101. Association for Computational Linguistics.
[7] Wu X, Lv S, Zang L, Han J, Hu S. 2018. Conditional BERT contextual augmentation. arXiv:1812.06705.
[8] Kumar A., Bhattamishra S., Bhandari M., Talukdar P. 2019. Submodular Optimization-base Diverse Paraphrasing and its Effectiveness in Data Augmentation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 1: 3609-3619.
[9] Xie Q., Dai Z., Hovy E., Luong M-T., Le Q.V. 2019. Unsupervised Data Augmentation for Consistency Training. arXiv:1904.12848.
[10] Sohn H., Park B. 2022. Robust and Informative Text Augmentation (RITA) via Constrained Worst-Case Transformations for Low-Resource Named Entity Recognition. Association for Computating Machinery, 1616-1624.
- Categories:


