Structured Annotation of Audio Data
Rob Capra, Jaime Arguello, Bogeum Choi, Mengtian Guo
School of Information and Library Science, University of North Carolina at Chapel Hill
Overview
Analysis of audio data is an important activity in the intelligence community. Typically, operators transcribe audio data into a text file. While they transcribe, they may make annotations called operator comments (OCs) to help downstream analysts make sense of the audio (e.g., clarifications, entity identifications). These OCs are often typed directly into the transcript as unstructured text. The main goals of this project are:
- to understand the types of OCs that analysts make and the information that they record,
- to understand challenges operators face when making OCs, and
- to develop systems to support analysts in effectively and efficiently making structured OCs that can be used in downstream processing and linked knowledge bases.

Study Design

We conducted a study with 30 language analysts to investigate the three research questions outlined above. We provided participants with transcripts from the Nixon Whitehouse Tapes in MS Word format and asked them to make OCs at places in the text they normally would make OCs. We asked participants to indicate what information they would include with the OC and to describe why they were making the OC. At the end of the study, we asked open-ended questions about what challenges they faced while making OCs during the study and while working on real-world tasks.
Results
Based on the data collected and analyzed in the study, we report
- a taxonomy of types of operator comments, and
- a set of challenges faced by analysts when making OCs.
The list below shows the taxonomy of operator comments along with counts of how often each type occurred.
Taxonomy of Operator Comments
- Entity identification – info to help identify a referenced entity
- Person (721) – names, aliases, position, link to KB
- Event (42) – name, date, location
- Object (41) – description of object
- Organization (39) – full name, description of organization
- Location (29) – name of place, lat/long
- Time (26) – day, date, month, year, time, timezone
- Acronym (18) – e.g., TSA
- Currency conversion (3) – to help understanding
- Clarification – info not documented outside the transcript (e.g., in a KB).
- Abstract (205) – info of potential use to other analysts
- Situational (135) – info to help understand the situation
- Idiom (58) – e.g., “till the cows come home”
- Domain-specific (15) – meaning of term in this domain/culture
- Unfamiliar (6) – analyst is not familiar with the expression
- Context (259) – link to another source with informative context
- Reference (121) – co-reference resolution
- Nature of statement (22) – e.g., speculation, hypothetical, assertion, question, opinion
- Implication (20) – possible real-world consequences of the statement
- Speculation of unintelligible (38) – words omitted, unclear; OC speculates about what was said
- Underlying intent (12) – speaker’s real intent behind what they say
- NFI (8) – no further info; analyst checked, but more info is needed
- Cover term (3) – e.g., “the plumbers” refers to the Watergate break-in team
Below is a list of the main challenges analysts faced when making OCs.
Challenges Faced Making/Viewing Operator Comments
- Tracking down information to complete an OC (9)
- Not knowing the target audience (8)
- Creating visual clutter (3)
- Differentiating OCs from non-OC content (3)
- Lacking contextual knowledge to understand the “big picture” (2)
- Distinguishing known facts from speculations (2)
- Lacking cultural/vernacular knowledge (2)
- Discerning intentions (2)
- Defining the scope (i.e., start and end point) of an OC (2)
- Resolving intentional vagueness (1)
- Indicating level of uncertainty of information included in an OC (1)
- Lack of community-wide standards (1)
- Avoiding misinterpretation (1)
Requested Features
Through analysis of the open-ended questions from our study, we collected a list of tools/features requested by participants to help support analysts in making OCs. These included: predicting places where OCs should be made, automatic suggestions of information to include in OCs, reducing keystrokes, supporting/encouraging standards, linking to related transcripts, integration with knowledge graphs and knowledge bases, and standardizing formatting.
Prototype
As part of our ongoing efforts, we are developing a prototype tool to support analysts in making structured OCs. Figures 2 and 3 show screenshots of our current prototype. In Figure 2, an analyst has selected a section of the transcript to make an OC about (“Barker”) and used a sequence of hotkeys (alt-e, alt-p) to indicate that this is an Entity-Person type of OC. The system then presents a structured form with fields relevant to the Entity-Person OC type.
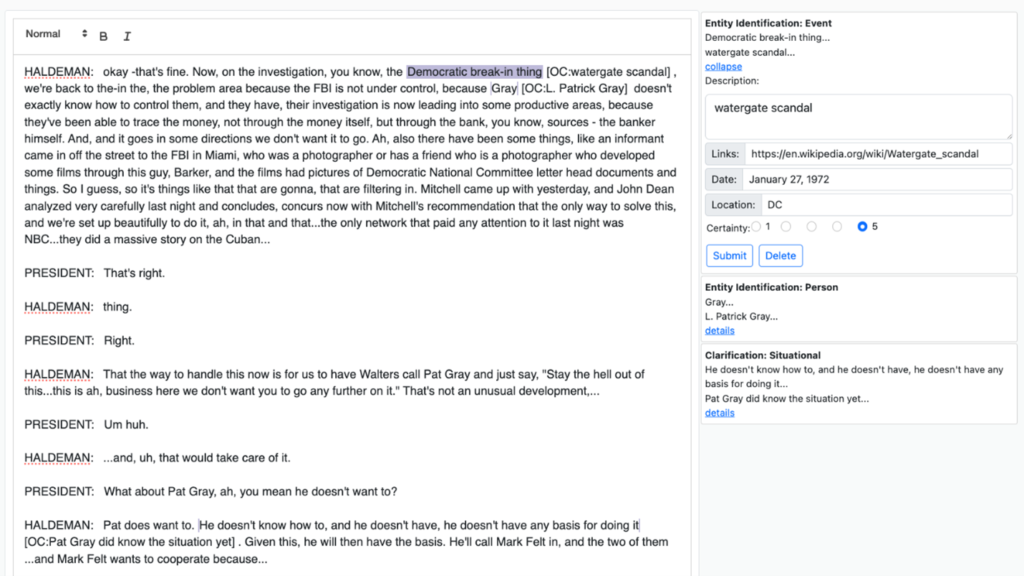
Figure 3 shows a transcript with several OCs already entered. In this situation, the analyst has selected an existing OC for the text “Democratic break-in thing.” This expands the OC in the right-hand column and allows the analyst to make edits. In addition to displaying a summary of each OC in the right-hand column, OCs can (optionally) be shown in-line with the transcript (e.g., [OC: watergate scandal]). This is to help facilitate use of the OCs by downstream analysts.
Summary
Results from our work this year have led to a taxonomy of operator comments and a set of challenges that operators face when entering OCs. We are incorporating these findings into a prototype tool to help support analysts in making structured OCs that can be integrated with knowledge graphs and knowledge bases.
- Categories:


