Rare and Uncommon Object Detection
Felecia ML., James S., Donita R.
Background
What happens when open-source computer vision models such as You Only Look Once (YOLO) try to detect objects such as customized weapons or flags of adversaries in foggy or dark environments? As you may guess, the models tend to perform poorly. Why, you might ask? These types of objects are considered rare and uncommon which are objects that are underrepresented or not represented at all in datasets. Developing object detection models for rare and uncommon objects is hampered by the lack of relevant training data. For example, open-source computer vision/object detection models are pre-trained to detect common objects such as people, cars, and pets in perfect lighting or weather conditions. However, rare/uncommon objects, which can be just as important as detecting common objects, may be misidentified or missed altogether. Therefore, what is the best approach for increasing the accuracy of detecting rare/uncommon objects by computer vision models?
The Laboratory for Analytic Sciences (LAS) is partnering with Fayetteville State University (FSU) and the SAS Institute to research the best approach to develop object detection and segmentation deep learning models for rare/uncommon objects under various environmental conditions. Three methods are currently being explored:
- Synthetic Data Generation (SDG)
- Generative Adversarial Networks (GANs)
- Neural Radiance Field (NeRF)
The LAS collaboration with FSU, led by Dr. Sambit Bhattacharya, is a project titled “Development of Detectors for Rare, Uncommon Objects Supported by Synthetic Data.”
The LAS collaboration with the SAS Institute, an analytics software company in Cary, NC, is titled “Assessment of Novel Modeling and Synthetic Data Methods to Reduce Labeling Burden.”
Synthetic Data Generation
Synthetic data is artificial data generated to have the same properties as an actual/real dataset. Developing synthetic objects and environments using photorealistic graphics simulation software can assist with augmenting training data to detect rare/uncommon objects by computer vision models. Detecting Chinese-manufactured surveillance or street cameras (CCTVs) has been the initial use case to further explore leveraging synthetic data generation.
In amassing publicly available datasets composed of Chinese-manufactured CCTV images to train computer vision models, the LAS team immediately noted
- the variety of CCTVs were scattered throughout the internet and were not contained in a centralized data repository such as MS CoCo or ImageNet;
- there are limited-to-no pre-trained labeled datasets for Chinese manufactured CCTVs;
- the overall lack of images depicting specific manufactures of the CCTVs.
In 2022, the LAS and FSU collaborated to assist in addressing the need of augmenting training to detect rare/uncommon objects in images and videos. The team used the open-source graphics software tool, Blender and an API called ZPY by Zumo Labs to generate synthetic CCTVs at various angles and perspectives. ZPY creates a JSON file that supports the Common Objects in Context (CoCo) format which includes bounding box information, labels, segmentation, depth and location of each image. These synthetic images were then used as training data to aid in increasing the detection of actual/real CCTVs in images and videos. For more information about the 2022 rare object detection research, please click here.

The LAS team has also been partnering with the SAS Institute who developed an interactive dashboard to track and centralize synthetic and labeled data, model iterations, and performance metrics. SAS assessed the synthetically generated CCTV dataset for model performance. Some key takeaways were
- synthetic data reduced the amount of manual labeling required to iterate on computer vision models;
- over-training on similarly structured synthetic images can lead to an over-fitted model that does not perform well on new scenarios;
- combining synthetic, augmented, and real-world training data yielded the highest mean average precision (mAP).
For more information about the SAS research, please visit their LAS symposium poster.
In 2023, the team explored new approaches such as
- using few shot learning to improve model performance;
- make the synthetically generated objects appear more photorealistic;
- and place those objects in various environmental conditions (e.g., cities, towns, weather).
The software graphics tool Unreal Engine was used to render 3D photorealistic objects and immersive environments. This allowed for
- objects to be captured at various viewpoints and environmental conditions using a virtual camera;
- generating additional training data by exporting keyframes of the object.
Also, FSU researchers developed a custom script in Unreal GT to generate and organize metadata that is similar to the CoCo format (i.e., segmentation, depth, bounding box and automatic labeling) about the rendered object. In Figure 2 (below), rendered CCTVs were placed in various cities/towns and captured at different viewpoints to augment training data.

Figure 3 (below) demonstrates how customized/rare military weapons can be trained with the aid of synthetic data generation. Using the Unreal Engine, the weapons (in Figure 3) were rendered and captured (with Unreal Engine’s virtual camera) at various angles and depths. These captured images were then exported as keyframes to augment training data. The videos on the right (in Figure 3) demonstrate the trained object detection model on actual/real videos. To learn more about the outcome of FSU research on rare object detection, please review their 2023 LAS symposium poster.

(Left) Synthetically generated rare weapons placed on an airfield using Unreal Engine;
(Right) Training models to detect rare weapons in publicly available videos
Cycle Generative Adversarial Networks (GANs)
Cycle GANs automate the training of image-to-image translation (unsupervised) models with unpaired examples and capture the characteristics of Domain A (e.g., CCTVs) to generate new images from Domain B (e.g., environmental conditions) that share the same characteristics. By using Cycle GANs, models can be trained to detect objects in different environmental conditions, such as rain, fog, and dusk.
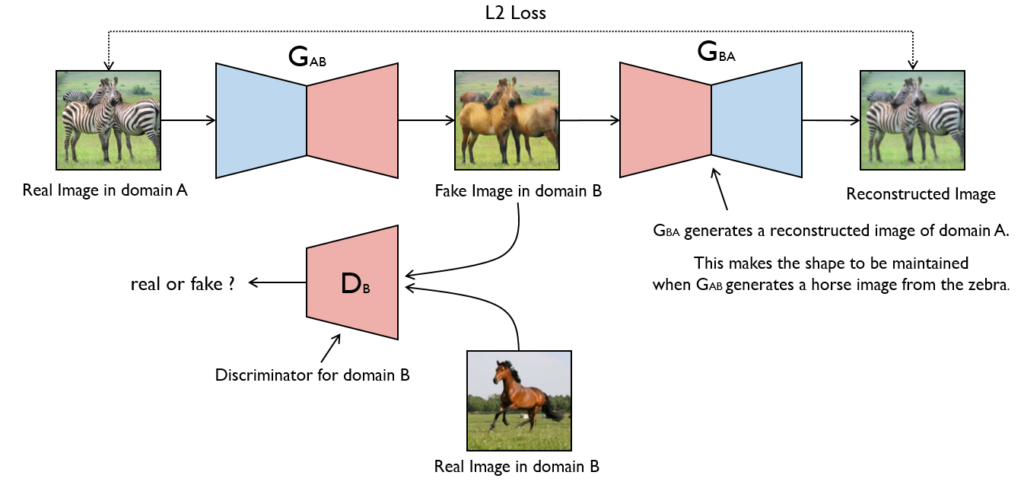
In the example image below (Figure 5), the LAS team used unpaired images of actual CCTVs and rainy environments to generate new images of CCTVs in rainy environments.

In the example below (Figure 6), unpaired images of synthetically generated CCTVs in day environments and images of dusk environments were used to render new images of CCTVs in dusk environments using Cycle GANs. This method can train models to detect outdoor objects at different times throughout the day (e.g., lighting, shadows, etc).


Neural Radiance Field (NeRF)
In the Summer of 2023, the LAS team explored using Neural Radiance Field (NeRF) to minimize the process of manually rendering objects using software graphic tools such as Blender and Unreal Engine. The team tested various NeRF versions, including commercial and open-source options. A version of NeRF, called Instant-NeRF, appeared to have the most potential due to its ease of use and the ability to customize code.
A team of AI researchers from UC Berkeley, Google Research, and UC San Diego first introduced NeRF in 2020. NeRF uses real 2D images and/or videos to render 3D photorealistic scenes automatically, thus reducing the amount of time it takes to render objects and/or scenes in software graphic tools. NeRF maintains various textures, performs novel view synthesis, approximates reflections, captures shading and lighting more accurately, and provides image segmentation.
The example image below (Figure 7) shows video screenshots (at eye-level) of a publicly displayed jet at Ft. Liberty (left). The results of the video using Instant NeRF is demonstrated on the right. Instant NeRF automatically rendered the object (e.g., jet) at various viewpoints, beyond what was originally recorded at eye-level, without using any software graphic tools.

Because NeRF is relatively new in the computer vision world, additional research is being explored by AI researchers to improve its performance. However, the LAS will continue exploring NeRF as a way to automatically render rare/uncommon objects.
Sub-Linear Deep Learning Engine (SLIDE)
Training complex and large deep-learning models can become very expensive to run. For example, as the LAS explored using Cycle GANs, the team quickly realized that more than one GPU was needed to train the model. Therefore, the LAS is exploring the Sub-Linear Deep Learning Engine (SLIDE), which is an alternative way of running deep learning models on a CPU versus a GPU.
Some benefits of using SLIDE are:
- Back-propagation dependence on matrix multiplication is severely reduce
- Neural networks is turned into a search problem that could be solved with hash tables (Locality-Sensitive Hashing)
- If different neurons are activated, then SLIDE can update and train them independently (CPU Parallelism)
- The downside is that SLIDE requires significant memory (cache thrashing)
- There will be a lot of cache misses
Next Steps
As data for rare/uncommon objects continues to grow, ongoing research is needed to improve the robustness of computer vision models for object detection. For 2024, the LAS team will continue to explore the following:
- Enhance the performance of few-shot learning
- Address video data challenges such as motion blur, unusual viewpoints, and the detection of small objects
- Improve rendering objects in environmental variations using GANs
- Differentiate between objects similar in design
- Continue to research the various implementations of NeRF
- Implement alternative option to GPUs: Sub-Linear Deep Learning Engine (SLIDE)
- Automated rare/uncommon object detection workflow

- Categories:


