Knowledge-MiNER: Efficient Knowledge Extraction and Curation for Analyst Annotation

Stephen S., Sue Mi K., Stacie K, Susie B.
Knowledge-MiNER is a prototype application designed for use in studying and enabling human-in-the-loop interactions and AI-infused workflows. Uniquely, it focuses on curation of knowledge artifacts that human analysts already create, whether they are in notes, transcripts, report drafts, or other documents. Knowledge-MiNER works with analysts by using named entity recognition (NER) to facilitate entity tagging, entity grouping, and entity linking. It further utilizes transformer models to perform information extraction for both entity properties and relationships. Knowledge-MiNER uses AI-infused workflows to streamline manual knowledge curation processes and reduce cognitive load on analysts, while facilitating analyst interaction and correction at all stages of the process. Knowledge-MiNER also presents a means to populate our corporate knowledge repositories at scale – with human-verified information that is more complete, accurate, and reliable. Knowledge-MiNER has the potential to feed robust knowledge repositories, which are consequential for the entire analysis and production cycle.
Importantly, Knowledge-MiNER is intended as a space to study the best ways that AI-infused workflows and NER – a machine analytic with tantalizing yet not fully realized potential – can be used to solve real problems that analysts encounter in their current knowledge curation processes. We seek to evaluate interdependencies for AI-human interactions, while concurrently:
- automating manual data-entry and data-linking tasks,
- populating structured repositories for knowledge management, and
- providing a tranche of truth marked data (where analysts are already invested in knowledge curation) for analysis at scale.
The Challenge: Organize and Make Sense of Analyst Artifacts
Every day, analysts both encounter and produce huge reams of unstructured data. Unstructured data refers to any type of data that does not have a predefined data structure or organization. While there are other efforts to structure the data that analysts sift through in search of reportable information, our focus is structuring the information and knowledge that analysts themselves are producing – what we refer to as “analyst artifacts.” Here, a human has already determined an underlying piece of information to be valuable and is documenting that information in a largely unstructured fashion. The question we seek to answer is, how can AI be applied to these established and time-proven analyst behaviors to make their work easier, faster, and more easily searchable and discoverable?
Let’s take a closer look at these analyst behaviors. As analysts triage and assess information, they concurrently engage in annotation and documentation tasks – producing text that may summarize, translate, abstract key pieces of information, or draw connections to other knowledge. But while machines naturally produce information in a structured manner, humans do not! Especially when dealing with complex concepts, humans naturally document information in an unstructured format. An effort to add structure to that information, when undertaken at all, generally occurs as a secondary process. Forward-leaning analysts who engage in this secondary process must take the additional time to manually link entities in their unstructured notes to structured repositories in order to organize that knowledge and make it discoverable by others.
The sheer volume of unstructured knowledge that analysts are producing, however, makes this task time consuming and even overwhelming. In most instances, an analyst is manually linking to the same subset of entities repetitively – across notes, transcripts, and reports. In addition, unstructured data can be highly complex and varied, and analysts may not always know the granularity of structured information that corporate ontologies can contain. As a result, analysts may struggle to effectively manage and organize even their own knowledge. The upshot of these challenges is that the vast majority of analyst-produced artifacts remain in a mostly or entirely unstructured format, and only a small fraction of the classifiable information they contain ever makes it into a structured database.
Our Solution
This is where AI-infused information extraction and knowledge curation comes in. Knowledge-MiNER evolved from previous Laboratory of Analytic Science (LAS) work on the RedThread prototype, which demonstrated machine learning assistance to augment analytic workflows. Knowledge-MiNER leverages many of the same technologies, but integrates additional AI mechanisms to decrease the cognitive burden placed on analysts as they link entities and curate knowledge.
Knowledge-MiNER offers the opportunity for true human-machine teaming (HMT), starting with the human insight already present in text that has been generated by analysts, linguists, and reporters. Knowledge-MiNER moves beyond the human marking of machine-generated data that many analysts are painfully familiar with, and instead asks machines to mark human data. [1] Moreover, our prototype is designed to reduce clicks and cognitive load on analysts, making entity linking and data structuring a seamless step within existing workflows.
How it Works: Entity Recognition and Resolution
Let’s consider how we put the “NER” in Knowledge-MiNER!

Named entity recognition is a natural language processing (NLP) technique that involves automatically identifying and classifying entities in unstructured data sources, such as text documents. These entities can be anything from people and organizations to locations, dates, and other important and classifiable pieces of information. NER is foundational for the creation of knowledge graphs and opens the potential for knowledge graph analytics. Given a text document, we can extract information as subject, predicate, object triplets. Visually, we can present the subject and object as entity nodes, and the predicate as the relationship link. Entity types and relationship types are defined by an ontology, as well as entity and relationship properties.
Knowledge-MiNER begins by using an NER model to analyze human-written, English-language texts (analyst artifacts). It uses SpaCY NER, a commercially available entity recognition package, to search for and label commonly-used entity types such as PERSON or ORGANIZATION. SpaCY identifies those entities of interest which are then cross-checked to see if they already exist in the background database or not.
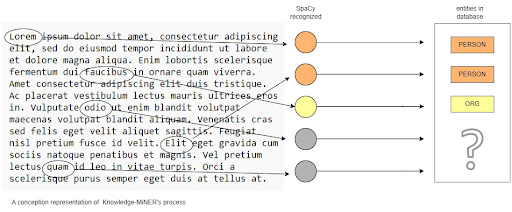
If the entities already exist, Knowledge-MiNER proposes to link the instance to the matching entity within the database. The analyst can reject, edit, or accept that proposed linkage. If an entity does not already exist in the database, the analyst can choose to add it. Once the analyst has confirmed all the linked entities of interest, the analyst can stop at that point (just linking the entities) or continue on to an information extraction phase.
How it Works: Information Extraction
During the optional information extraction phase, Knowledge-MiNER applies a set of templated questions to the confirmed entities to extract information of interest from the text using a MiniBert question answering model. The templated questions stem from the underlying ontology of the database, with each question derived from a property or relationship structure that pertains to the given entity type. All possible questions for a given entity type are “asked” of the text, and resulting answers are then checked against entries in the database. The analyst, then, is only presented with and asked to confirm new information, or information from the text that contradicts what is already recorded in the database. In addition to confirming the information extracted, the analyst can also edit or reject that information. The analyst will not, by default, be asked to confirm information that is already present in the database.
Before pushing the extracted information to the database, Knowledge-MiNER will ask the analyst to confirm all the links and information extracted. Source data will be automatically collected and appended.
Knowledge-MiNER in Practice
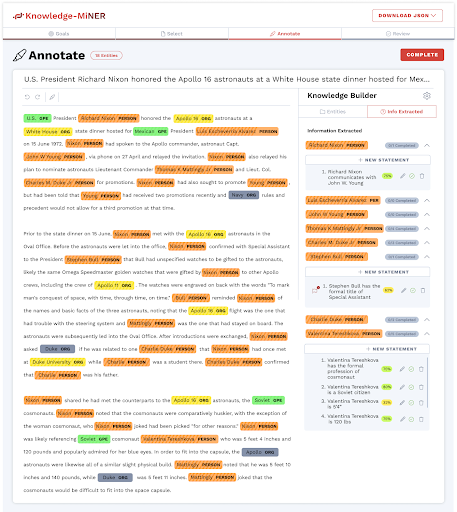
Let me show you how this works in practice. An analyst begins with a text they have written synthesizing some knowledge, which could be a note, a transcript, a report, or something else. The SpaCy model is used to identify and tag certain entity types of interest. For this prototype, we have started with PERSON, ORGANIZATION, and COUNTRY (also captured by SpaCy as GPE). These initial entity types represent the entities most used by analysts.
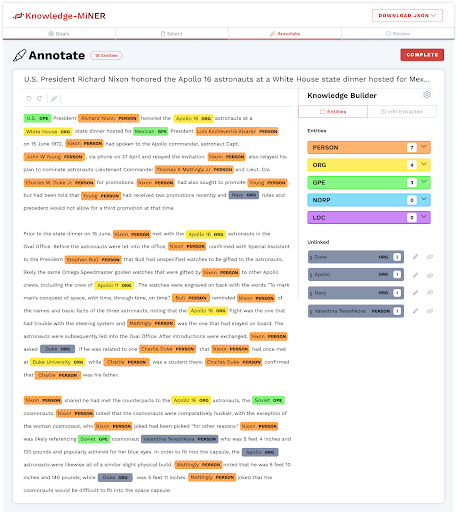
All entities that have been recognized by both the NER model and exist in the underlying database are color coded and “linked” together. When an NER-identified entity could not be matched – potentially because it is not present in the database or exists but is annotated incorrectly – it is shaded gray for analyst action. In this example, we see that Richard Nixon is recognized in the database, but Valentina Tereshkova is not.
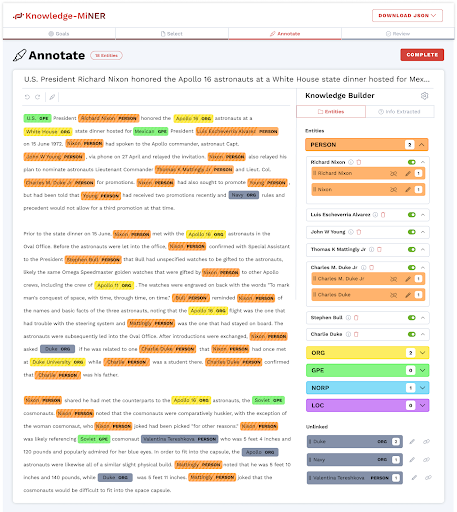
Above is the Knowledge Builder panel. This is a self-contained space in which the analyst can do manipulations and corrections at all the stages of the curation process. Entities are grouped by type or class. The analyst can expand entity types and individual entities, as well as drag and drop entities to group them together for coreference resolution – i.e. asserting when two expressions refer to the same real-world entity.
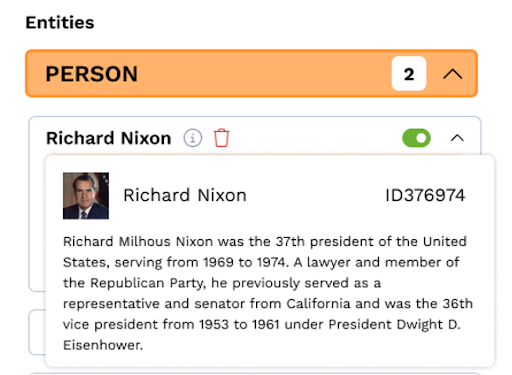
The analyst can verify Knowledge-MiNER link assertions by hovering over the information icon to display a “baseball card” viewof the entity linked in the database.
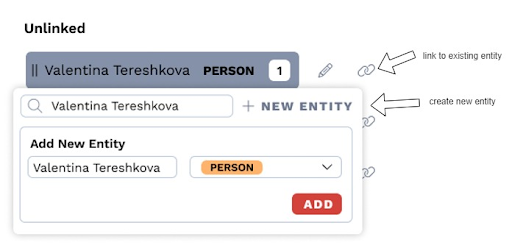
The analyst can further manipulate the entities within the unlinked section by updating the entity type, pointing it to an existing entity in the database, or creating a new entity for entry into the database. A newly linked entity will be grouped with the other existing linked entities.

After confirming all entities for accuracy, Knowledge-MiNER can perform information extraction against all of the entities of interest to the analyst.
In the Knowledge Builder Info Extracted panel, we can see new information from the text about our confirmed entities – that is, information that does not already exist in our database. Analysts are presented with a confidence measure from the extraction algorithm, and can customize the minimum confidence threshold for information extraction. We can also see any information from the text that contradicts what is in the database.
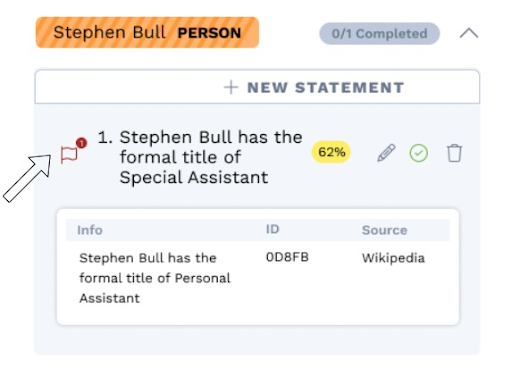
Contradicting information is indicated with a red flag, and the analyst can hover over the flag to get additional information on the root of the contradiction.

When the analyst is satisfied with the entity links and information extraction, the analyst can move to the review stage. This allows for a final human verification of the extracted knowledge before being linked and curated in the database.
Importantly, analysts may select “complete” at any time to skip past the information extraction phase and just use the linking functionality.
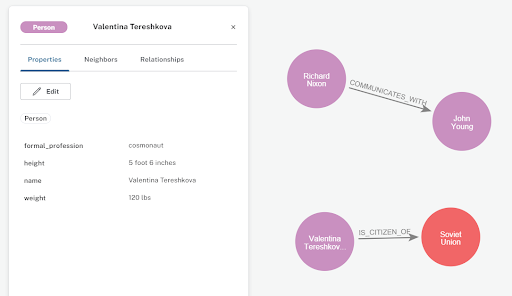
Here is a graph representation of that same extracted information.
Future Work
The Knowledge-MiNER lowside prototype is in its final stages of development and will be ready for testing in the coming weeks. Given the human-centered goals of this project, we intend to use the lowside Knowledge-MiNER in human subjects research (HSR) to study and evaluate interdependencies for AI-human interaction. We will be actively recruiting analysts to participate in the coming months. Knowledge-MiNER offers a rich space in which to study many aspects of human-machine teaming, which may include:
- task performance measures (efficiency gains, accuracy gains),
- cognitive load (workload, attention allocation),
- latency impacts,
- user experience (user satisfaction and preferences),
- coordination metrics (task distribution, collaboration quality),
- user adaptability and learning curves, and
- user trust.
We are also seeking funding and support to bring Knowledge-MiNER and its user testing highside, to complement and inform other corporate efforts involved in knowledge curation and AI-infused workflows. We envision Knowledge-MiNER on the highside as a plugin version of the interface, with potential for integration into an existing corporate tool.
These research and implementation activities will bring the power of AI-infused workflows to bear against formerly intractable problems of knowledge extraction and curation, making corporate information more retrievable and trackable while informing human-machine teaming implementations on the highside.
If you are interested in getting involved, please contact Stephen S. (seshaug@ncsu.edu), Sue Mi K. (smkim2@ncsu.edu), Stacie K (skuamoo@ncsu.edu), or Susie B.(smbitter@ncsu.edu).
- Categories:


