EYEGLASS: Improving the Quality and Efficiency of Computer Vision Model Development for Out-of-Domain Datasets
Will Gleave, Sam Saltwick, Joe Hackett, Kyle Rose (Amazon Web Services)
Stephen W, Lori W, Al J, Mike G, Troy W, Felicia M, James S, Brent Y
Traditional computer vision model development requires extensive data curation and annotation. This process is time-consuming, labor-intensive, and expensive, in some circumstances requiring up to hundreds of thousands of annotations to train an effective model. Gathering a dataset that is robust to the types of data drift that are often seen in production is also challenging, as developing a model that generalizes well requires a dataset with sufficient diversity. Techniques such as transfer learning, pretraining, knowledge distillation, and the use of larger foundation models have reduced the data annotation burden to allow performant computer vision models to be trained with smaller labeled datasets. In this work, we explore and quantify the tradeoffs of using different combinations of these state-of-the-art techniques in a model development pipeline and identify conditions leading to performance deterioration.
We use the problem of detecting objects in video footage to comprehensively study and optimize computer vision model development pipelines. We gathered a dataset of open-source videos and annotated a subset of the frames for the task of object detection. We construct various model development pipelines with the goal of answering the following questions:
- How do we measure robustness to out-of-domain data?
- How can we train more performant object-detection models?
- How can we make training object-detection models more data-efficient?
Model Development Pipeline
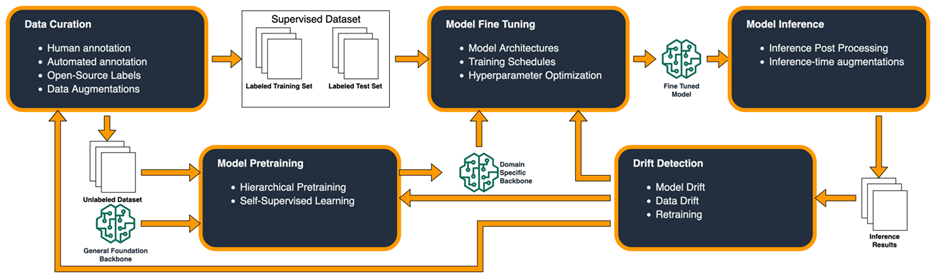
In order to investigate these questions in controlled experiments we defined a model development pipeline. The pipeline consists of five major components:
- Data Curation
- Annotating data using human labor or automated methods
- Identifying open-source datasets with relevant labels
- Augmenting data with visual transformations, tiling, etc.
- Model Pretraining
- Create and/or improve upon foundational vision backbones
- Adapt general foundational backbones into domain-specific backbones
- Trained through self-supervised learning – no labels!
- Model Fine Tuning
- Adapt a pretrained backbone to a specific task and domain
- Select model architecture
- Create training schedule and optimize hyperparameters
- Model Inference
- Generate inference results on unseen data
- Augment data at inference time for improved performance
- Post-process results to improve detections
- Drift Detection
- Measure inherent qualities of the data
- Evaluate model performance on both in and out-of-domain data
- Identify when re-finetuning or re-pretraining would be necessary
Using this standardized pipeline, we can explore different methods for data curation, model training, and drift detection to understand how to train object detection models better.
Measuring Drift & Evaluating Robustness
Data drift occurs when a data distribution at inference time is meaningfully different than the distribution of data used to train a model. Machine learning models often struggle to make high-quality predictions when faced with data drift. Models trained on a limited number of samples may produce confidently wrong results and limit how much an analyst can trust a model. In order to identify drift and limit performance deterioration in our object detection pipeline, we are utilizing three types of techniques: statistical methods for drift detection, representation learning as a measure of drift and uncertainty quantification.
Statistical Methods
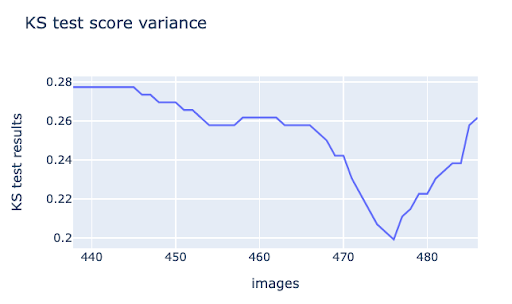
Traditional statistical methods such as the Page Hinkley or Kolmogorov-Smirnov tests can identify large-scale changes in an image at the global level. For example, the KS test score below shows a significant change as a truck passes by and takes up about 1/3rd of the frame in the figure on the right. This can be beneficial for detecting significant changes in a full image. However, it will not capture more subtle changes in data that can cause performance issues in object detection models.

Representation Learning as a Measure of Data Drift
The goal of representation learning is to create a condensed, feature-rich representation of data. These representations, or as they are often called, embeddings, can be used for various downstream tasks, including measuring data drift. Representation learning can be used to identify that data drift has occurred when enough embeddings of new data deviate significantly from the training data’s embeddings. Representation learning can be effective in measuring and detecting data drift in Computer Vision datasets, but is more computationally expensive and requires longer inference times.
Uncertainty Quantification
Neural networks produce a “confidence score” that is commonly misinterpreted as a probability. Uncertainty quantification techniques can help calibrate model outputs by providing estimates to the amount of uncertainty within a model’s predictions. Recent libraries such as Fortuna have made it significantly easier to calibrate model outputs and provide a reasonable probability estimation. We seek to extend these methods into the realm of object detection to appropriately calibrate object detection models and provide analysts with more interpretable and trustworthy predictions.
Improving Performance
Training performant object detection models from scratch requires vast amounts of data, time, and computational resources. This burden is lessened by finetuning pretrained general models on a smaller, domain-specific dataset. When fine-tuning models in this way it is important to ensure they do not become too specialized to ‘in domain’ data. The models should remain adequately performant on ‘out of domain’ data that falls outside the scope of the specific intended application of the model. Optimizing detection performance on both in and out-of-domain data is a primary goal of this research.
Methods for Improving Performance
There are a number of important factors that affect the success of supervised training:
- Dataset Properties—Characteristics of the dataset, such as whether the training set is representative of the application distribution, the size of the dataset, and the degree to which the dataset includes out-of-domain data to prevent over-specialization.
- Model Architecture—Selection of the proper model architecture to balance tradeoffs between prediction quality and speed.
- Model Pretraining—Pretraining a model on supplemental data before fine-tuning on a target dataset. There are multiple methods for pretraining, including supervised pretraining with a benchmark dataset and self-supervised pretraining with masked autoencoders.
- Data Augmentations–During fine-tuning it can be useful to augment the data by modifying the images with augmentations such as random crops, flips and color jitter.
Architecture Comparison
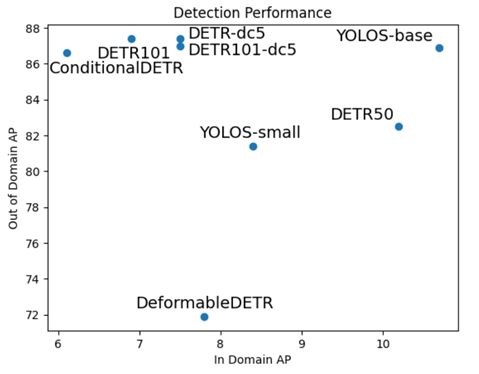
There are dozens of object detection model architectures, and the ideal architecture for a given situation is dependent on the dataset and the goals of the model developer. Model architecture dimensions of comparison include inference speed, prediction quality, and computing resource consumption. In order to better quantify some of these tradeoffs, we compare the performance of a number of recent object detection model architectures, with the goal of identifying models that perform well at detecting objects of interest on datasets that are both in and out of distribution of the model training data. Given the success of convolutional neural networks and vision transformers in object detection applications, we compare both vision transformers (YOLOS) and hybrid CNN/ transformer architectures such as DEtection TRansfromer (DETR) and a few of its variants (DETR-dc5, Conditional DETR, and Deformable DETR).
We evaluate these models on two test datasets, a challenging in-domain dataset and an easier out-of-domain dataset. We apply standard image preprocessing techniques, augment the training images by jittering the brightness, contrast, saturation and hue and adjust hyperparameter configurations to achieve convergence. Model performance as measured by overall AP on both the in and out-of-domain datasets is shown below. YOLOS outperforms other models on in-domain data and achieves top performance on out-of-domain data as well.
Future Work
In the future, we plan to more deeply explore other methods to improve object detection performance on out-of-domain data. The techniques we plan to explore include increasing dataset diversity and experimenting with other pretraining methods and augmentations.
Improving Data Efficiency
Manually labeling data for supervised training is one of the largest roadblocks in building machine learning models. In order to combat this, we explore methods for improving the data efficiency of training object detection models. The methods we explore are using weak supervision and hierarchical pretraining.
Distillation of Large Vision-Language Models
Recent research has demonstrated the power of utilizing language-grounded pretraining for vision models. In particular, the Grounding DINO model is able to use natural language for open-set object detection, locating and classifying objects of interest based on an input prompt.

While these models show promising zero-shot object detection performance, they’re extremely large, with Grounding DINO coming in at over 170M parameters.
In order to leverage the power of these models at a more manageable compute cost, we distill what these models have learned into a closed-set, object detection model. Our distillation process involves running inference with the large model to label over 500,000 images without any human effort. Then we use the inference results as a training dataset for our smaller model. In testing, we use a 40M parameter Faster-RCNN model with a ResNet-50 backbone and a Feature Pyramid Network (FPN).
We compare fine-tuning this smaller model with human-created labels and with Grounding-DINO-created labels. While human labeling required just over 8 hours to label 500 images, we are able to label over 500,000 images with Grounding-DINO in just 2 hours on a compute cluster and with no human labeling effort. When fine-tuning an object detector on these machine-generated labels, we found that we are able to match the performance of fine-tuning on solely human labels.

We also found that Grounding DINO alone, with no fine-tuning, performs slightly worse than our fine-tuned models, even the one trained on only Grounding-DINO labeled images. This also comes with a much heavier compute cost of almost 20x slower inference and approximately 1.5x more GPU memory required to run inference.
Hierarchical Pretraining
In a low-label data environment, it is important to make the most out of all available data. For that reason, we compare starting points for supervised fine-tuning between the following:
- Random initialization – start training from randomly initialized weights
- Transfer Learning – start supervised training with a general backbone model pretrained on a dataset like COCO and/or ImageNet
- Hierarchical Pretraining – start supervised training from a domain-specific backbone, pretrained on in-domain data using self-supervised learning
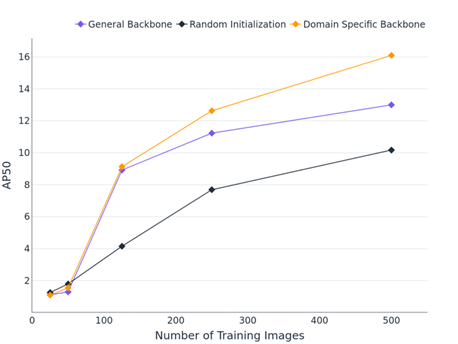
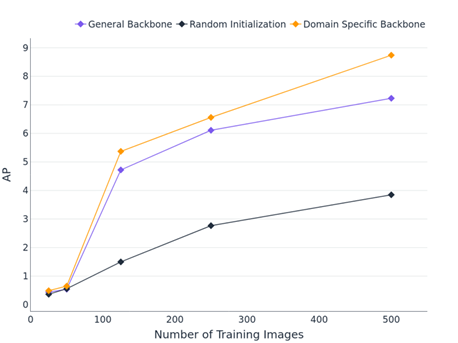
When comparing performance of these three training setups in low-data scenarios (<500 images in the largest data set), we found that starting from a domain-specific backbone can improve object detection performance. We believe this advantage could become even more significant with target datasets that are less similar to the general pretraining datasets like ImageNet and COCO. Future work with LAS may explore these situations and additional pretraining configurations.
Conclusion
It can be time-consuming, expensive, and labor-intensive to train high-quality machine learning models that generalize well to unseen data. Much of the time and human labor required to train a model is expended in the process of data annotation and curation. Machine learning techniques such as transfer learning, model pretraining, and knowledge distillation enable machine learning practitioners to more quickly develop better performing models. As we continue to use these tools and techniques to create and test various components of the model development pipeline, we will create a reusable process that can be used to accelerate model development and more quickly solve mission problems.
Contact Info
- Will Gleave (sgleave@amazon.com)
- Sam Saltwick (saltwick@amazon.com)
- Joe Hackett (jhhack@amazon.com)
- Kyle Rose (kymrose@amazon.com)
- Julie Hong (hongjth@amazon.com)
This material is based upon work done, in whole or in part, in coordination with the Department of Defense (DoD). Any opinions, findings, conclusions, or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the DoD and/or any agency or entity of the United States Government.
- Categories:


