Why build a model deployment service (MDS)?
Troy West, Jascha Swisher, Mike Green, Brent Younce, Aaron Wiechmann, Ryan Bock
Our original intentions and discussions on a model deployment service focused heavily on how we could simplify and standardize the process of allowing an LAS researcher to present ML driven prototypes to an analyst. Current solutions involving Jupyter notebooks or one off inference servers were cumbersome and presented a high barrier to entry. Data scientists need to spend time building demonstrations and many analysts are not comfortable using Jupyter. The hope was that we could reduce the burden on our data scientists in demonstrating their work and receiving feedback from analysts.
The model deployment service (MDS) is a platform that’s designed for LAS’s needs but tests techniques and technologies that could scale to the requirements of much larger organizations. It consists of a set of open source technologies and natively runs in Kubernetes. These technologies work well together but can be swapped out as needed ensuring future flexibility in this quickly changing field. But before we go into our technology choices let’s take a broader look at ML infrastructure.
What’s Machine Learning Model Infrastructure?
For the purpose of this blog post let’s separate ML infrastructure into 3 layers: Data Processing, Training and Serving. Each layer can be a separate and independent system or set of systems and does not need to be controlled by the same team/organization. Due to the depth and complexity of each of these layers we’re going to focus primarily on the serving layer. The serving layer is focused on repeatable deployments that scale, monitoring for both micro service and model health and providing standard interfaces for retrieving ML model inferences. LAS’s model deployment service (MDS) is a combination of technologies that enable model deployment, model storage and model health monitoring which all belong in the serving layer.
During our exploration of possible open source technologies for the MDS it quickly became apparent that these systems are complex. Early prototype testing helped us understand those complexities and create requirements for deploying containerized machine learning models in a semi production environment. In order to ensure trust in ML model predictions there would need to be adequate monitoring systems to determine model and data drift, highlight outliers and aid in model explainability. Without these systems it would be difficult to trust if a deployed model was functioning properly and difficult to diagnose issues. We’d also need a consistent pipeline and set of build processes to ensure our users could easily and consistently build containers for deployment.
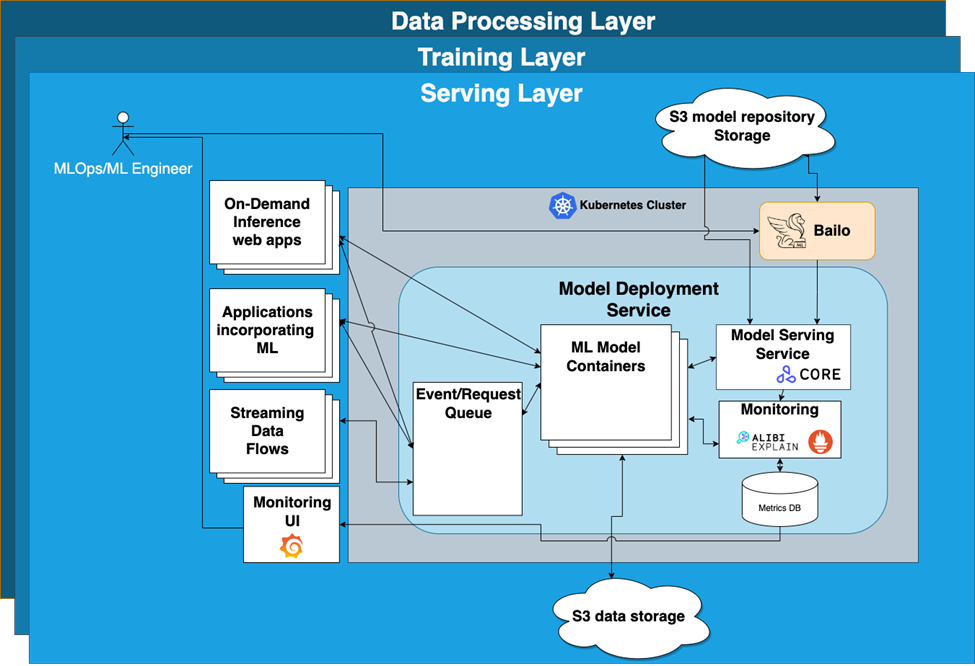
Model Deployment Strategies
How can a model be deployed into a production system? There are a number of different methods but in summary the 2 most common approaches are:
Embedded Model: The model runs directly inside of a streaming application allowing the application to use it directly.
External Server: Containerizing the model into a specialized server that allows inference using HTTP or gRPC. Within this category there is two types of servers:
- Specialized servers for serving a specific type of model such as Tensorflow(TF) Serving for any tome of TF model.
- Generic compound servers allow for the serving of graphs of deployed models which can be in a variety of formats. Seldon Core falls into this category.
We found the external generic compound server strategy was the most versatile option providing support for LAS uses and extendable enough to function at an enterprise scale. As one of the more mature open source model serving options Seldon Core stood out and was chosen to be the core of LAS’s MDS. We liked a lot of the standard features that Seldon Core provides. The ability to deploy a wide variety of ML models, API endpoint documentation with FastAPI, model explainability through Alibi and the ability to construct complex model grafts made it an easy choice.

LAS hopes to test and leverage our MDS system in a variety of inference categories. Let’s define the 3 main categories of inferencing:
- Large Batch: An asynchronous process that bases its predictions on a batch of observations. The predictions are stored as files or in a database for end users or business applications.
- Small Batch/On-demand (or interactive): Models make predictions at any time and trigger an immediate response. This pattern can be used to analyze streaming and interactive application data.
- Streaming: A small batch continuous process and can occur at high volumes. Similar to large batch predictions are stored as files or in a database.
Model Repositories
Model repositories are essential components in both the training and serving layers. In theory defining the purpose of a model repository is straightforward but it can be very different depending on the audience.
ML Engineers: A repository is a place to push and pull model artifacts/containers that are ready to be deployed into a production setting.
Data Scientists: A repository is a place to share and experiment with models as raw model artifacts.
Since we’re looking to support both we chose to evaluate Bailo, an open source model repository. Bailo allows users to upload a standard code template and model artifacts through a webpage and makes those models shareable via a Seldon Core based container deployable as a standalone server or directly into any system that supports Seldon containers. In theory this gives us a happy medium: our data scientists’ lives are simpler because they don’t need to fully understand how to build the containerized models and the ML Engineers have an artifact that can be versioned and deployed via Seldon Core into LAS’s MDS.
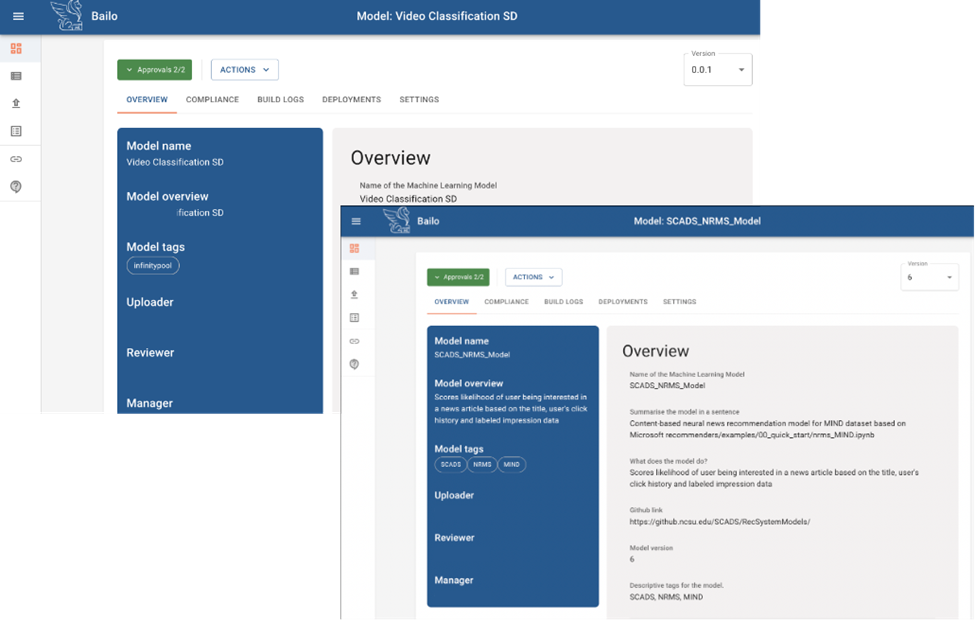
Initially Bailo was tested as a model repository for LAS’s annual Summer Conference on Applied Data Science (SCADS) event. The core motivation being we needed a consistent method for archiving, documenting and sharing machine learning models between years. After creating a project template we had participants interact with the system and attempt to build model containers. This quickly highlighted pain points and areas where further documentation would be needed in order to train data scientists to use Bailo. One of the more challenging elements for users was understanding how to correctly format data to be sent to an inference server and how to convert the sent data to a format which could be used by their model upon being received.
Monitoring
We need to know when a model’s performance degrades and how to explain that degradation. Concept drift monitoring makes sure that the model still behaves correctly while model explainability allows us to figure out why a model came to a certain decision to ensure trust in the model’s behavior. Having this data will be essential to establishing analyst trust and determining when model retraining is necessary.
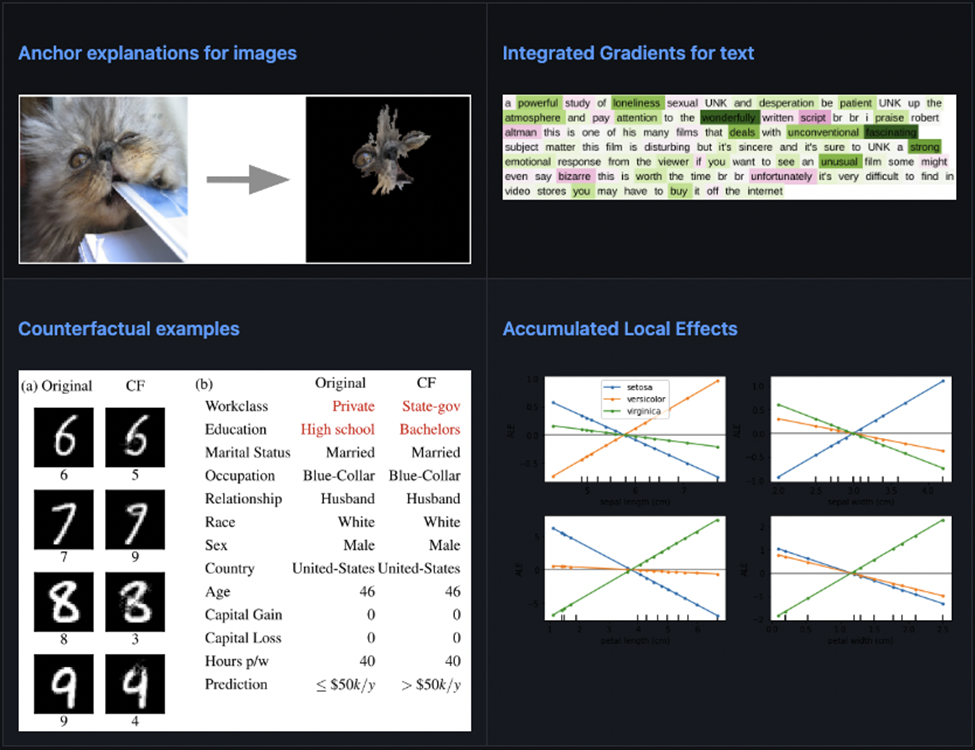
Seldon Core offers a number of features that enable ease of monitoring and metrics.
- Alibi Explain integration for aiding in model explainability.
- Alibi Detect can be used for outlier and adversarial detector monitoring
- Prometheus and Grafana integration provide advanced and customisable metrics monitoring.
- Full auditability through model input-output request logging integration with Elasticsearch.
- Microservice distributed tracing through integration to Jaeger for insights on latency across microservice hops.
- Users are able to submit feedback on model output and have that feedback recorded and reflected in model health metrics.
Great, we have a deployment system! How do we use it?
Since we’ve chosen to focus on the external server method for model deployment, let’s take a look at some of the methods in which this can be used to enable analysts, data scientists and existing applications to integrate ML into their workflows.
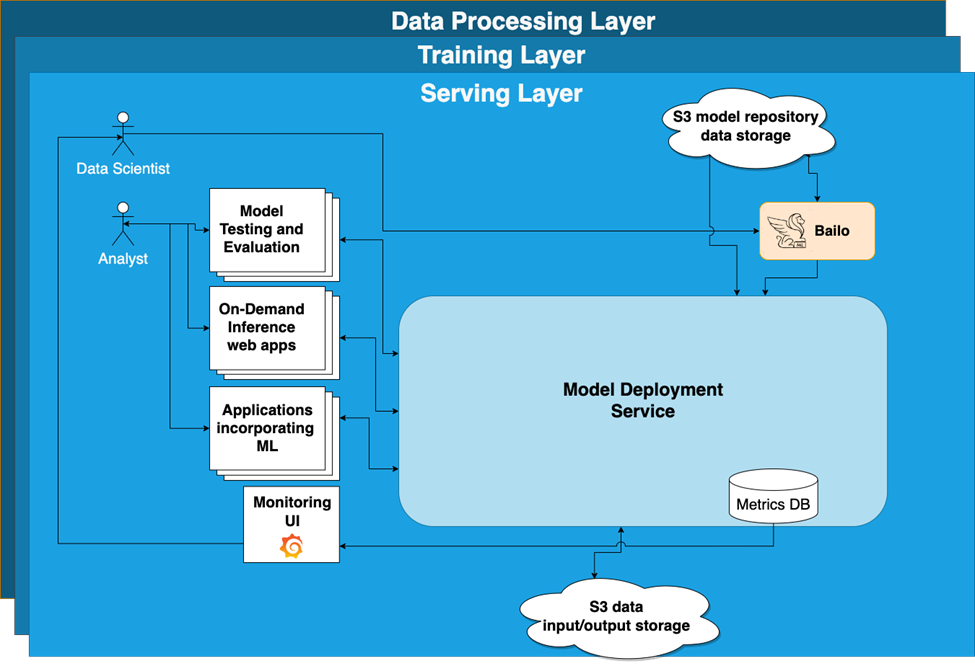
Analysts:
- Rather than Jupyter notebooks, analysts can incorporate ML into their decision making process through the use of inference on demand web apps which connect directly models deployed in the MDS.
Data Scientists:
- Inference on demand web apps and standardized model feedback and health monitoring creates an easier, more consistent means of getting analyst feedback on model prototypes.
- The external server deployment method allows for quicker testing of resource intensive models allowing them to run in scalable architecture.
Analytic/Platform Developers:
- Consistent interfaces and independent scaling ensure existing and new tools will be able to take advantage of ML in their decision making processes without the need to directly embed the ML models within their codebase.
ML Engineers:
- Can easily deploy the Bailo containers created by a data scientist or recreate new containers based off the prototype.
- Standardized containers can have automated testing and monitoring to ensure model output can be trusted.
Other projects at LAS are now working to enable ML through deployed external model servers. INFINITYPOOL is using Bailo built Seldon Core containerized models to provide pre-labeling to data sets. This is powerful as INFINITYPOOL can integrate any number of models for different data modalities without the resource and complexity added with embedding the models within the application. Once active INFINITYPOOL will be able to simply direct its inference requests to the MDS.
Final thoughts
There are many varied methods of building ML infrastructure and deploying ML models, the systems covered in this blog are one of many ways that we can take advantage of ML infrastructure. These methods will not cover every need but we believe they can actually cover a broad range of uses and solutions.
Infrastructure will be essential to drive further improvements and integration of ML models into the decision making processes of users. We hope that our experiments and lessons learned will provide others with the knowledge needed to create systems at a corporate level.
Notable Technologies:
Monitoring:
- Graphana – https://grafana.com/
- Prometheus – https://prometheus.io/
- Alibi Detect – https://github.com/SeldonIO/alibi-detect
- Alibi Explain – https://github.com/SeldonIO/alibi
Model Repository/Model Deployment:
- Seldon Core – https://docs.seldon.io/projects/seldon-core/en/latest/
- Bailo – https://github.com/gchq/Bailo
- Seldon MLServer – https://mlserver.readthedocs.io/en/latest/
Streaming/Scaling Support:
- KNative – https://docs.seldon.io/projects/seldon-core/en/latest/streaming/knative_eventing.html
- Kafka – https://docs.seldon.io/projects/seldon-core/en/latest/streaming/kafka.html
- Categories:


