Taming Deep Learning: Faster and Cheaper
This work was funded by the NCSU LAS: Laboratory for Analytics Sciences, 2022.
- Mr. Kewen Peng <kpeng@ncsu.edu>, Ph.D. candidate, CSC NC State
- Mr. Suvodeep Majumder <smajumd3@ncsu.edu>, Ph.D. candidate, CSC, NC State
- Dr. Tim Menzies <timm@ieee.org>, professor, CSC , NC State
Summary: A “router-based” reasoning oracle can tell when not-so-hard predictions can be handled by a simple/fast/cheap linear model; or harder predictions need the computational complexity of deep learning.
Much intelligence work needs to monitor streams of textual data (email, blogs, Twitter feeds, newspapers, etc). Deep Learning should be the perfect technology for this task. But due to the computational costs and incomprehensibility of its models, this is not the case.
What if the problem is that we are trying to paint with too broad a brush? Instead of demanding a one-size fits all approach, what about an alternate method where we peek at incoming examples, then route them to deep learning, or some other model, depending on the complexity of that newly arrived problem?
The core intuition here is that not all predictions are at such difficulty level that mandates inference to DL models. Previous works attempt to simplify complex DL models but did not explore the hybrid of hard/easy models as a router mechanism.
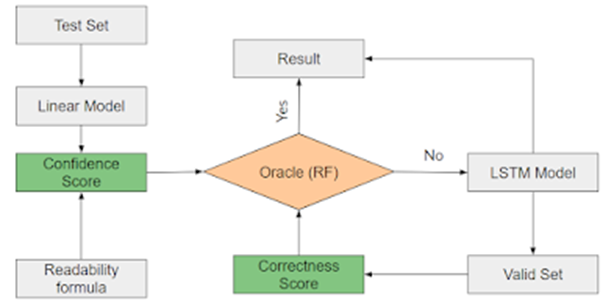
Using the procedure shown at above, we had a router-based pipeline, which contains a complex DL model and a simple linear model. The learning goal is to only activate the DL model when our router oracle believes the next prediction is sufficiently difficult.
To estimate the difficulty level, we explore many semantic-based readability score formulas (some examples shown below) and adapt ones with highest variance.
FRE = Flesch reading ease score =
2.06835 – 1.015*(total words) / (total sentences) – 84.6*(total syllables) / (total words)
Coleman-Liau index =
0.0588*(mean letters per 100 words) – 0.296*(mean sentences per 100 words)
Our proposed approach has reduced the inference time by 10x times (thus the inference cost by 10x cheaper), while making little harm to the prediction power of the DL model.
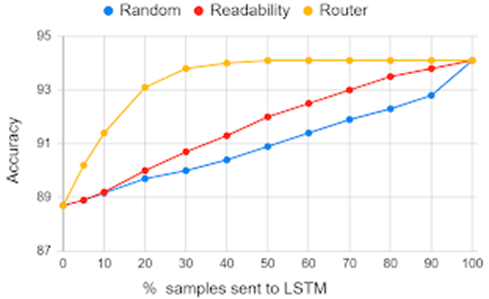
Results for emotion dataset:
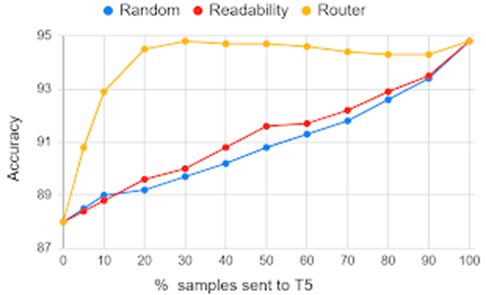
Results for IMDB dataset:
The framework can be applied to many NLP scenarios, such as emotion classification, NER, and machine translation.
- Categories: