Sound Event Detection
Triaging Non-Speech Sounds in Audio Content
Tina Kohler, Patti Kenney, Sean Lynch, Jacque Jorns
The Pitch
Over the past year the LAS Sound Event Detection (SED) team explored whether we can provide language analysts with a triage capability to detect specific, mission-relevant, non-speech sounds of interest in audio recordings. Why do we believe this will be helpful? We have found several cases in the public space where sound event detection has found practical application. As a couple of examples, military and police forces use it to detect gunshots, and self-driving cars designers see its potential application in improving the cars’ performances in reacting to environmental sounds such as horns or sirens.
Nixon’s Press Secretary Ron Ziegler
To understand how such a capability might be helpful for intelligence analysts, we can turn to a data set LAS is using for several projects related to voice language analysis: the Nixon White House recordings. These recordings are publicly available, and contain the conversations President Nixon recorded in various locations of the White House from 1971 – 1973. As one of our LAS analysts listened to portions of the recordings, she discovered that she could hear the sound of Press Secretary Ron Ziegler’s pen as he took notes during some of his most important conversations with President Nixon. In separate recordings, she could also hear the notes of “Hail to the Chief” emanating from a music box that President Nixon liked to show off to important Oval Office visitors. “What if,” she pondered, “analysts could use their own ‘sounds of interest’, in order to more quickly locate audio files of potential significance?” And thus, our sound event detection project was born.
Sifting Through the Noise
At LAS, much of the lab’s focus in recent years has been on Content Triage: the discovery of valuable intelligence information within potentially very large data sets. LAS projects like SED aim to improve analysts’ ability to efficiently and effectively search, explore, prioritize, retain and extract value from an ever-increasing amount of data in various formats. In simple terms, the idea is centered around how we leverage unique parameters, such as context, environmental or even behavioral clues (regarding the latter, see this year’s work on Voice Characterization Analytics for Triage), to more efficiently comb through large datasets. Or in other words, how do we use those pertinent clues about our intelligence targets to quickly find more valuable intelligence information. While the SED team has not yet solved this problem for language analysts, that is the overarching goal of this project.
‘OLIVE’
Our first approach in beginning this project was to learn who else was interested in and perhaps also studying sound event detection capabilities. We quickly found that a mission office had recently had a similar idea and had begun working with the VISTA Research team to deploy a near-term solution. In collaboration with VISTA Research, the SED team decided that the best way we could add value to the nascent, existing effort was to apply rigor to the evaluation of existing technical capabilities and methods. — One of the many reasons LAS is well positioned to conduct this type of work (in addition to having an expert technical workforce) is its access and familiarity with unclassified proxy datasets; a primary example for this project and other LAS’ research efforts, is the corpus of Nixon White House recordings. Thus, our LAS researchers worked with their VISTA counterparts to evaluate VISTA’s initial solution – DARPA’s OLIVE (Open Language Interface for Voice Exploitation) algorithm. This work progressed on two fronts: 1) an evaluation of existing OLIVE sound models on the Nixon White House recordings, and 2) the creation and evaluation of OLIVE pen-scratching models.
To conduct our evaluation of existing OLIVE sound models we processed the entire Nixon White House corpus with the algorithm and analyzed many aspects of the resulting labels. Since the corpus had no labels, we created a sampling of the detected sounds and annotated them using the LAS-created InfinityPool labeling application. What we learned was quite disappointing: OLIVE labeled none of the sounds correctly.
Our second evaluation of OLIVE focused on pen-scratching sounds explicitly. To facilitate this, our LAS analysts on the team located 188 examples (approx. 3,600 seconds) of the sound within the Nixon White House recordings. The models we trained on these pen-scratching sounds achieved poor results as well. However, after using standard data augmentation techniques (Python’s Audiomentations package) to increase the pen-scratching label set (over 25-fold) we subsequently greatly improved the accuracy to a level that is probably useful operationally.
Mission Impact
After rigorous evaluation, the SED team determined OLIVE’s accuracy was likely insufficient for mission applications and communicated such to the mission stakeholder/VISTA. As a result, the mission stakeholder was able to reinvest personnel resources, which had been invested in testing OLIVE on mission data, onto other mission priorities.
A Promising Way Forward
After the initial work to determine whether this research was more broadly valuable to analysts and performing evaluation of existing capabilities, our SED team turned its gaze toward the identification andevaluation of other potentially useful machine learning algorithms. We chose to focus first on transfer learning algorithms, specifically experimenting with varied sound embeddings and machine-learning algorithms on open-source, sound-labeled corpora. Not only did we vary the features and algorithms, but we also experimented with variations to the machine-learning parameters. To date we have evaluated openL3 and VGGish embeddings as features for both support vector machines (SVM) and multi layer perceptrons (MLP) using sweep metrics to compare results. The bar chart below shows the best results from the thousands of experiments we performed. The chart plots errors, hence lower numbers are better.
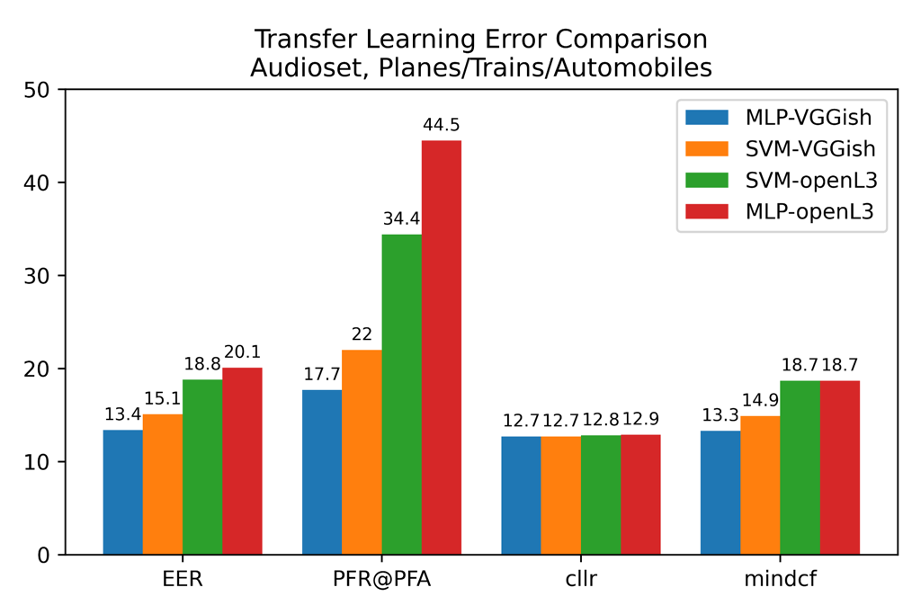
As one can see from the chart, using VGGish embeddings as features to a multi-layer perceptronprovides the lowest error in each of these four metrics. Notably, our research shows that the VGGIsh embeddings and other algorithms are (potentially) sufficiently accurate to identify sound event detection and thus aid mission analysts with content triage.
What’s On the Docket for 2023?
In the coming year our SED team plans to test the promising algorithms and embeddings mentioned above, against mission data. Crucially, we also plan to use language analyst input as a benchmark in determining the utility of said solutions. From there the team will have a better sense of how well said capabilities perform in an operational setting and can reorient as needed. We will also be working with students from North Carolina State University’s College of Design to create user interface prototypes showing how a capability leveraging this technology could be incorporated into language analyst tools. Ultimately, the team’s hope is to provide analysts with a corporate capability that provides something akin to the following: 1) A language analyst finds a non-speech sound of interest and tags that sound → 2) after a reasonable number of samples are collected, the system trains and applies a detection model to promote recordings containing that sound for further review by the analyst.
- Categories:


