Improving Text-Guided Image Search
A blog post written by Robert Pless, on behalf of the project team:
Robert Pless, Manal Sultan, George Washington University
Abby Stylianou, Pranavi Koluju, St. Louis University
Nathan Jacobs, Eric Xing, Washington University in St. Louis
Stephen W., Felecia ML, James S., Nicole F., Victor C., Lori Wachter, LAS
Sometimes you have an image and are looking for similar images. Sometimes that search doesn’t work perfectly. Maybe you don’t have exactly the right image to start with, or maybe the search is focusing on the wrong thing in your image. If you have the idea “Maybe I can add some text to guide the search,” you are thinking about the Text-Guided Image Search problem.
We think about this problem in the specific context of image search to help sex-trafficking investigations. Our team has worked to provide the National Center for Missing and Exploited Children (NCMEC) with a search tool that helps them figure out which hotel a picture was taken in. Our search tool works a little bit like Google Image Search — you can drag an image into the search tool, and it searches a database of 10 million hotel room images to find the ones that are most likely to be from the same hotel. This helps NCMEC analysts understand where old images were taken, and sometimes from where live streams are currently being broadcast, and helps support prosecutions of sex-traffickers and rescues of sex-trafficking victims.
In this domain, Text-Guided Image Search comes up because searching an index of 10 million hotel room images is hard. Lots of hotel rooms look alike. Also, the picture that you are searching with might be dark, or taken from a strange angle. It might not even show very much of the room. However, you might look at your image and think, “that is a very unique carpet.” Text-Guided Image Search would let you say, “Find me images like this one, especially the carpet.”
Our team worked on this problem this year, from both a theoretical direction and tools that we deployed with an initial implementation of text-guided image search to NCMEC. The way this works is that the query is an image combined with a description of how the image should be changed as it is used to search the database. The picture below shows an example query that combines an image and text of the change, and examples of errors encountered by previous methods. Our approach gives the correct image retrieval answer on this.

What is going on? Why do previous methods fail? Our key hypothesis was that Text-Guided-Image-Retrieval was especially sensitive to the “attribute binding” problem. This is the name for the problem that CLIP features sometimes get confused about which adjective applies to which noun in a sentence. This is visible in Figure 14 from the original OpenAI Dall-E paper:

Here you can see that the text “red cube on top of a blue cube” can be used to generate images with the idea of red cube and blue cube, but doesn’t capture which is where or even the idea that there are two cubes. It isn’t entirely clear why the original CLIP paper has this failure mode. The loss function used in the original CLIP paper drove the model to make sure that an image and it’s caption got embeddings that were closer than the image and any other caption. Perhaps their training didn’t didn’t have a lot of examples where it was important to distinguish a red box on top of a blue box from a blue Rubik’s cube with a red corner.
Whatever the reason, this kind of inaccuracy in the CLIP representation is especially problematic for Text-Guided Image Retrieval, which needs to represent an image and understand a modification or emphasis to that image given in text. Therefore we worked to fine-tune CLIP to better relate words in a text description and the corresponding image region.
To do this, we started with the standard CLIP model that trains an image encoder and a text encoder to give an image and its caption a similar embedding. In particular, we take advantage of the cross-attention features possible in the transformer models that we use for the encoders. Consider the following image, and instruction for how to change it:

We can visualize how much attention each phrase in the sentence is giving to different image features. We find that the attention is often misplaced or unfocused. The three pictures below show where attention from different phrases in the above sentence is focused. We see that it mistakes the bathroom towels, is less focused on the toilet than it could be, and seems very confused by the concept of the black waste basket.

We found that this confusion is much worse when seeing a phrase in the context of a longer sentence (like those that come in describing changes in images), but the attention is much more focused if you just have the phrase. Therefore we created a new version of CLIP whose loss function says, “the attention from a noun phrase by itself should be matched in the attention for that noun phrase in a longer sentence”. We hoped that adding this to CLIP training would help build representations that better understand objects in complex sentences.
To perform this training, we created the following training infrastructure. When given an image and corresponding text, the network analyzes the entire text and also analyzes each noun phrase individually. Then it penalizes the CLIP model if the attention of the noun-phrase in the context of the sentence is different from the attention of the noun-phrase by itself. The overall network diagram is shown below.
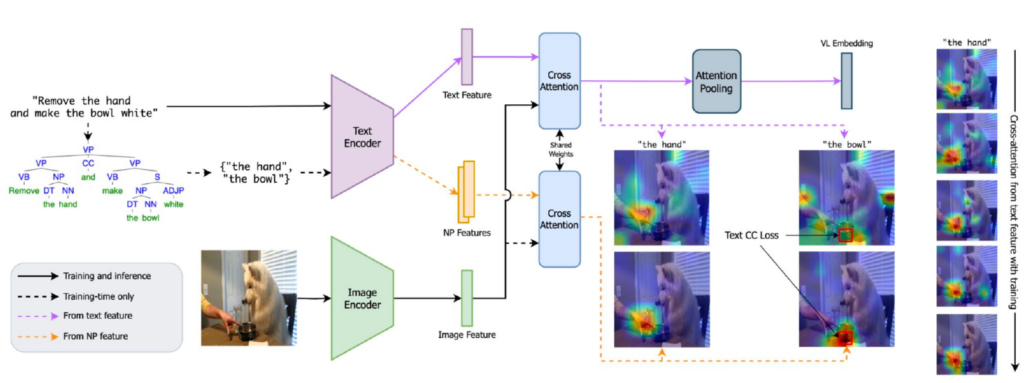
If you aren’t used to looking at big network architecture diagrams like this, the right series of images down the right side might be most compelling. It shows the attention for the noun phrase “the hand” in the context of whole sentence when we start training (with default CLIP), and you can see that as training progresses, the attention becomes more and more focused on the correct part of the image.
/

Because the new CLIP model is able to keep track of object identity in the context of longer sentences, we could also train the model with longer, more specific sentences. We worked to translate captions in classic Composed Image Retrieval Datasets to be more accurate and precise:

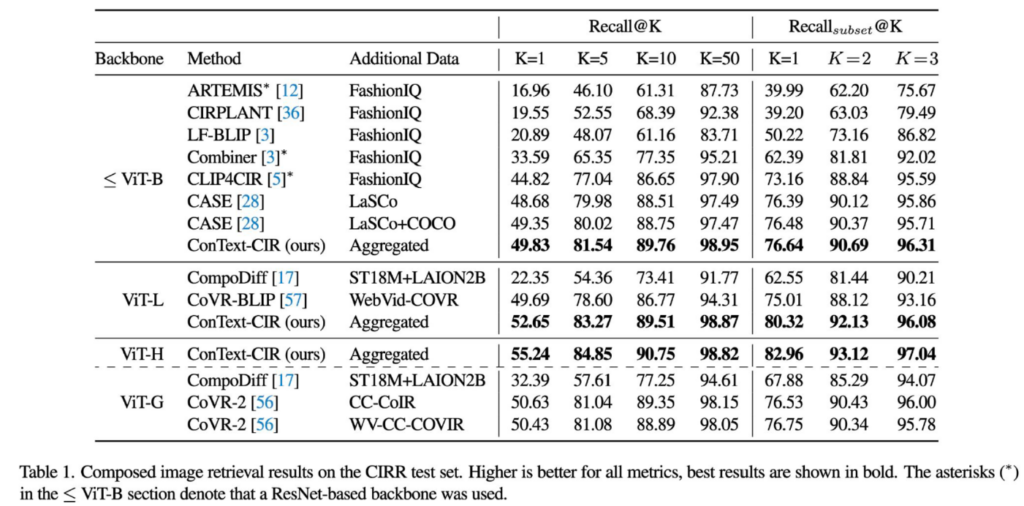
So did it work? Composed image retrieval is a popular research topic today in Computer Vision research. There are a number of datasets and a large number of recent approaches. In a comparison with these, our approach gives the best results reported for all architecture/backbone sizes:
We are working on several approaches to best integrate this new capability with our collaborator at NCMEC, and working with LAS again in 2025 to improve the ability to use CLIP like models to find small objects.
This material is based upon work done, in whole or in part, in coordination with the Department of Defense (DoD). Any opinions, findings, conclusions, or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the DoD and/or any agency or entity of the United States Government.
- Categories: