Structured Annotation of Audio Data
Rob Capra, Jaime Arguello, Bogeum Choi, Mengtian Guo, Jiaming Qu, Jaycee Sansom
School of Information and Library Science, University of North Carolina at Chapel Hill

Overview
Analysis of audio data is an important activity in the intelligence community. Typically, operators transcribe audio data into a text file. While they transcribe, they may make annotations called operator comments (OCs) to help downstream analysts make sense of the audio (e.g., clarifications, entity identifications). These OCs are often typed directly into the transcript as unstructured text. The main goals of this project are:
- to understand the types of OCs that analysts make
- to understand challenges operators face when making OCs
- to develop systems to support analysts in making structured OCs, and
- to incorporate human-AI teaming to improve the process of making OCs.
Prior Work
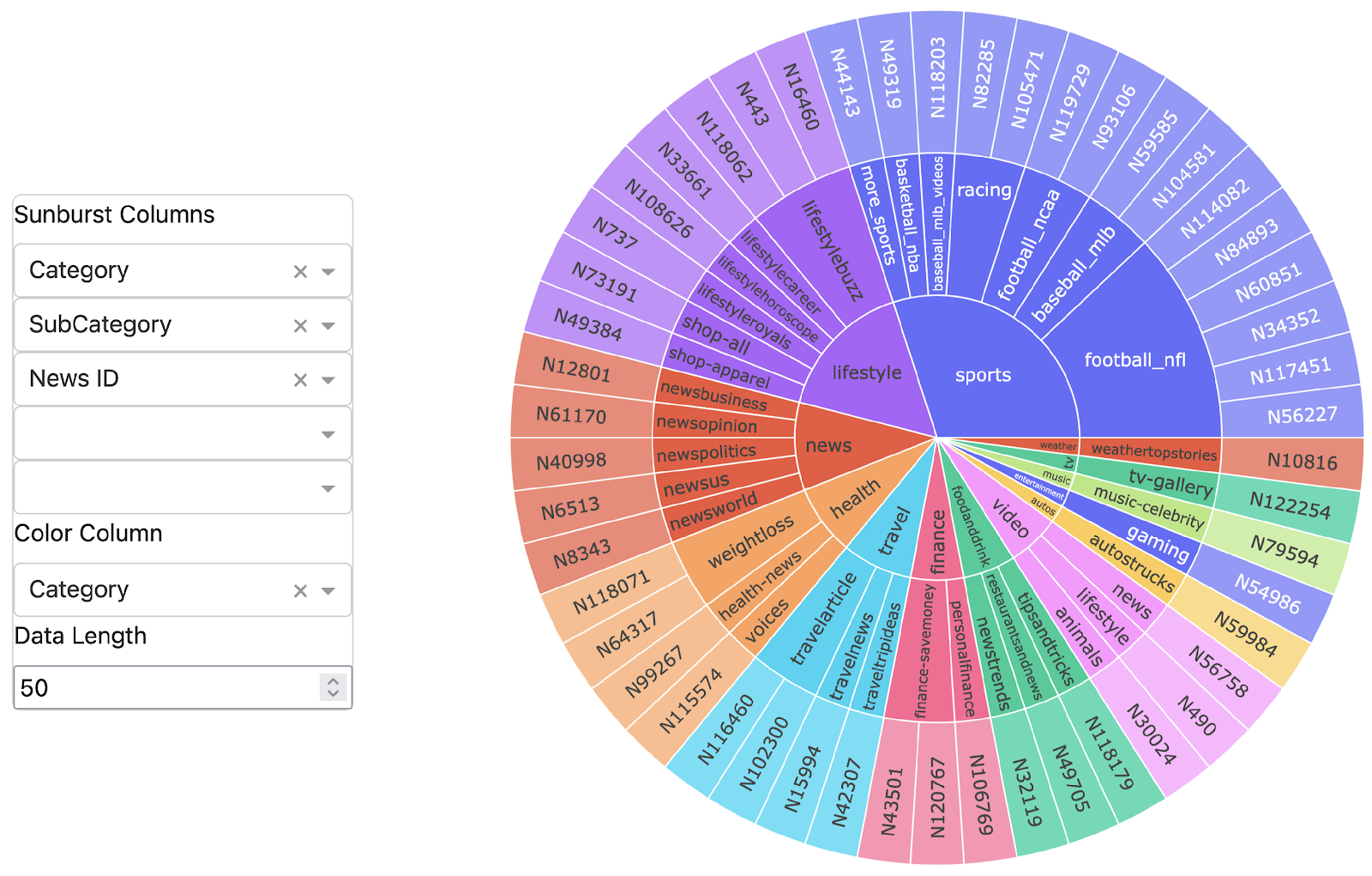
In previous work, we conducted a study with 30 language analysts to investigate the first three research questions outlined above. We provided participants with transcripts from the Nixon Whitehouse Tapes in MS Word format and asked them to make OCs at places in the text they normally would make OCs. We asked participants to indicate what information they would include with the OC and to describe why they were making the OC. Based on the data collected and analyzed in the study, we developed a taxonomy of types of operator comments. Figure 1 shows the taxonomy of operator comments along with counts of how often each type occurred.
Prototype
Based on results from the previous study, we developed a prototype tool to support analysts in making structured OCs. Figures 2 and 3 show screenshots of our prototype. In Figure 2, an analyst has selected a section of the transcript to make an OC about (“Barker”) and used a sequence of hotkeys (alt-e, alt-p) to indicate that this is an Entity-Person type of OC. The system then presents a structured form with fields relevant to the Entity-Person OC type.

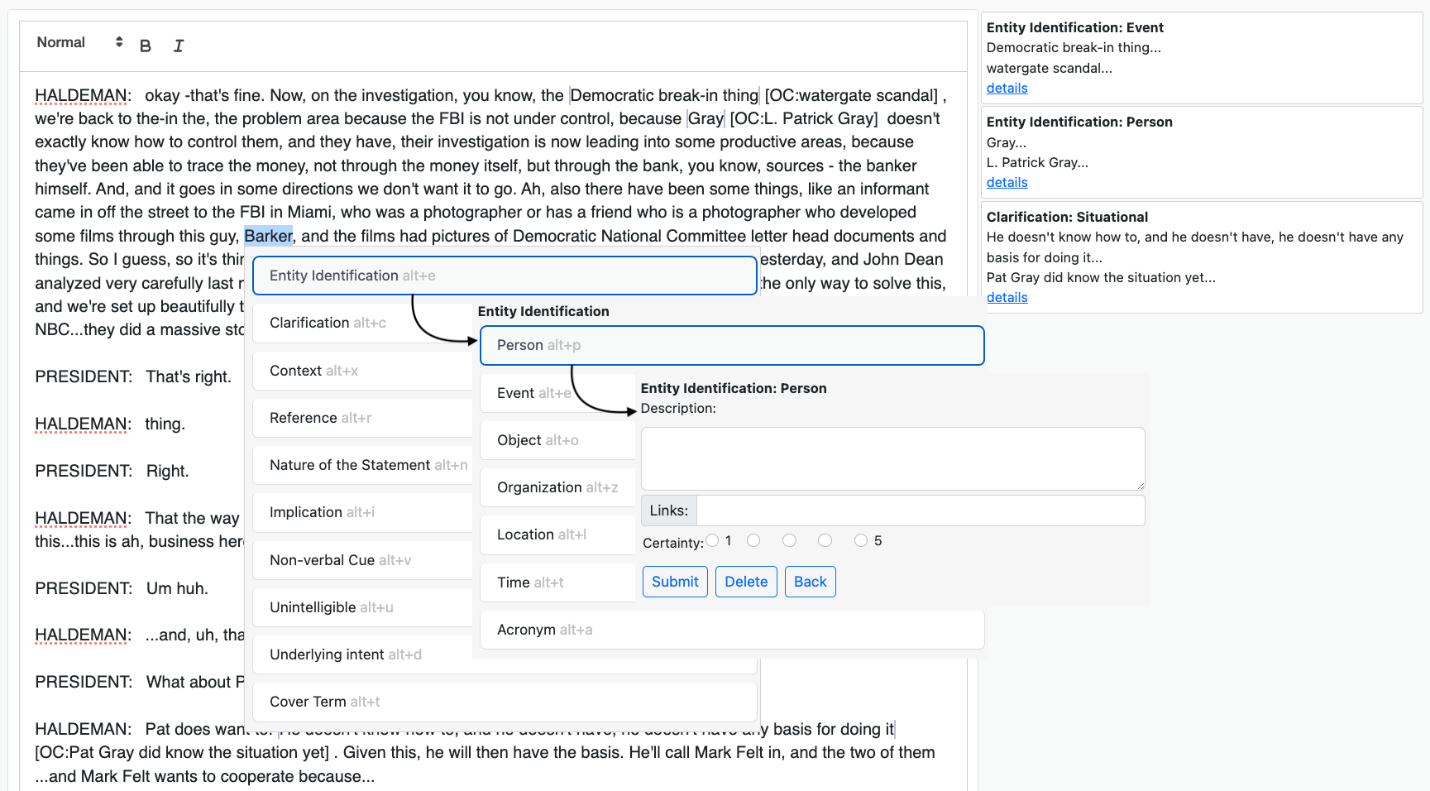
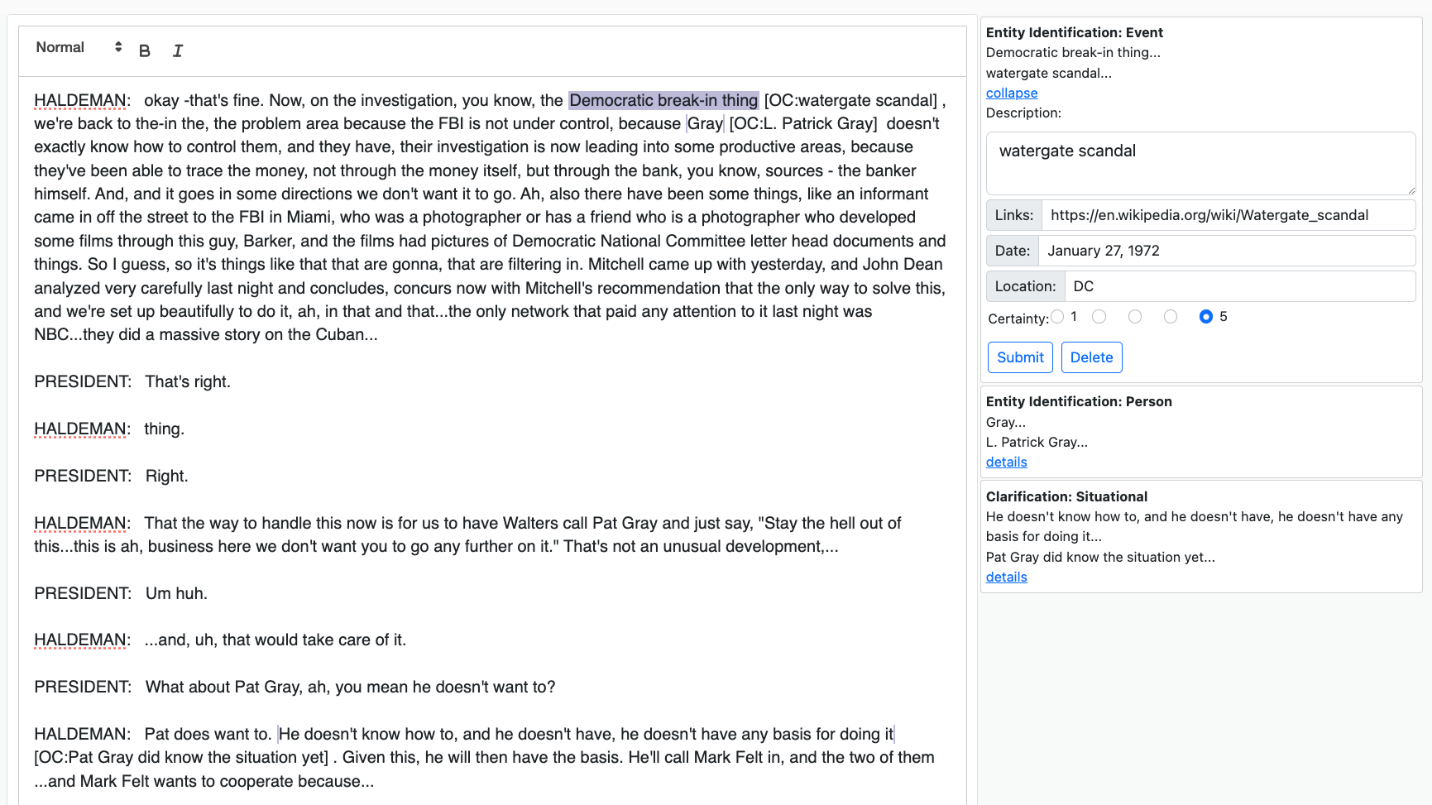
Figure 3 shows a transcript with several OCs already entered. In this situation, the analyst has selected an existing OC for the text “Democratic break-in thing”. This expands the OC in the right-hand column and allows the analyst to make edits. In addition to displaying a summary of each OC in the right-hand column, OCs can (optionally) be shown in-line with the transcript (e.g., [OC: watergate scandal]). This is to help facilitate use of the OCs by downstream analysts.
Study Design
We conducted a study with 16 language analysts to compare our structured prototype annotation tool against the baseline of entering OCs manually in the text. We used a within-subject design in which each participant conducted two tasks – one using the baseline method of entering OCs manually in the text (e.g., [OC:]), and one using our structured annotation tool. The tasks asked participants to make hypothetical OCs on two transcripts from the LBJ White House tapes. After using both the baseline and the structured prototype tool, we asked participants to complete a survey to compare the two approaches. The survey asked participants to rate each system on a scale from 0 (low) to 100 (high) along the following dimensions:
- Workload – Rate each system in terms of how much work it took to make the OCs
- Difficulty – Rate each system in terms of how difficult it was to make the OCs
- Satisfaction – Rate each system in terms of your level of satisfaction with the OCs you made
- Usefulness – Rate each system in terms of how helpful your OCs would be for other analysts
- Diversity of OCs – For each system, rate the extent to which your OCs were… of the same type… of different types
- Conveying confidence – Rate each system in terms of how easy it was to convey your confidence in the OCs
- Consistency – For each system, rate the extent to which your OCs were… inconsistent in terms of the types of information they included… consistent in terms of the types of information they included
Results
Based on the survey results, we found:
- No significant differences between the two systems for workload, difficulty, satisfaction, or number of OCs made (see Figure 4). We view this as a generally positive result – even though our prototype was new and unfamiliar, participants did not rate it as being more difficult to use or resulting in a higher workload compared to the baseline.
- Participants reported several advantages of the prototype (see Figure 5):
- Usefulness – participants thought the OCs created using the prototype would be more helpful to other analysts
- Diversity – participants thought that their OCs created using the prototype were more diverse in terms of the types of OC
- Conveying confidence – participants though that the prototype made it easier for them to convey their level of confidence in the OCs they made
- Consistency – participants thought that the prototype helped them be more consistent in terms of the types of information they included in their OCs
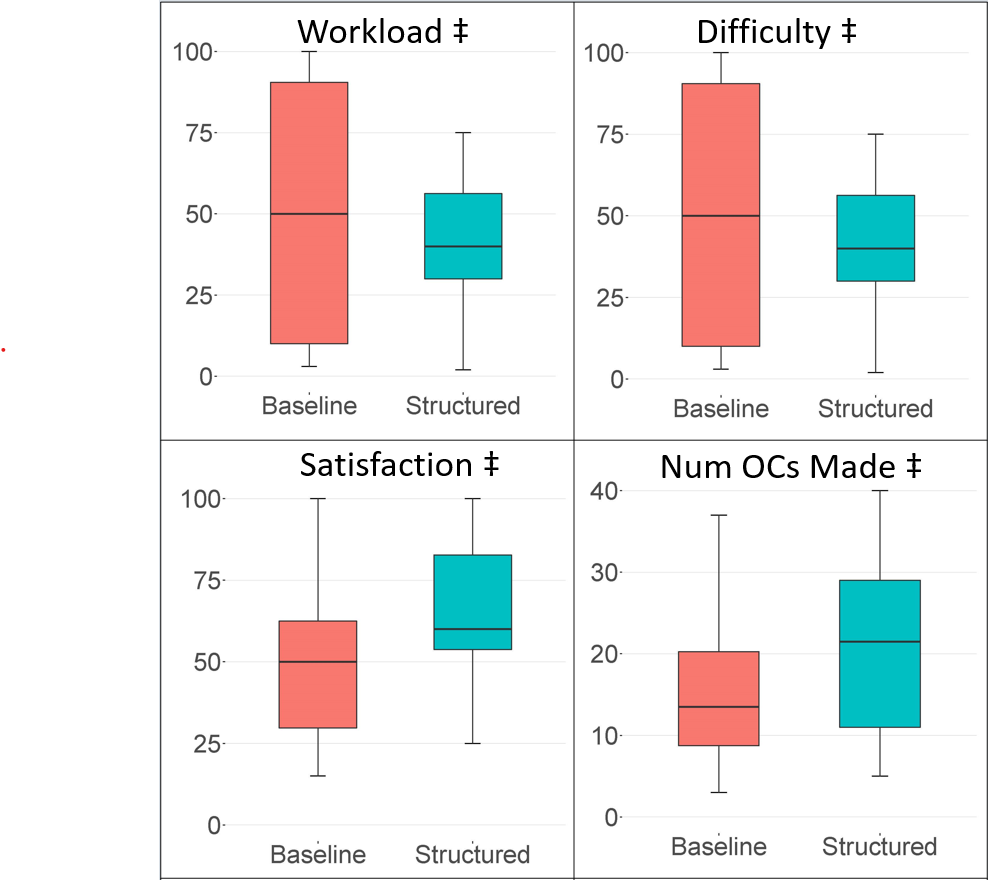
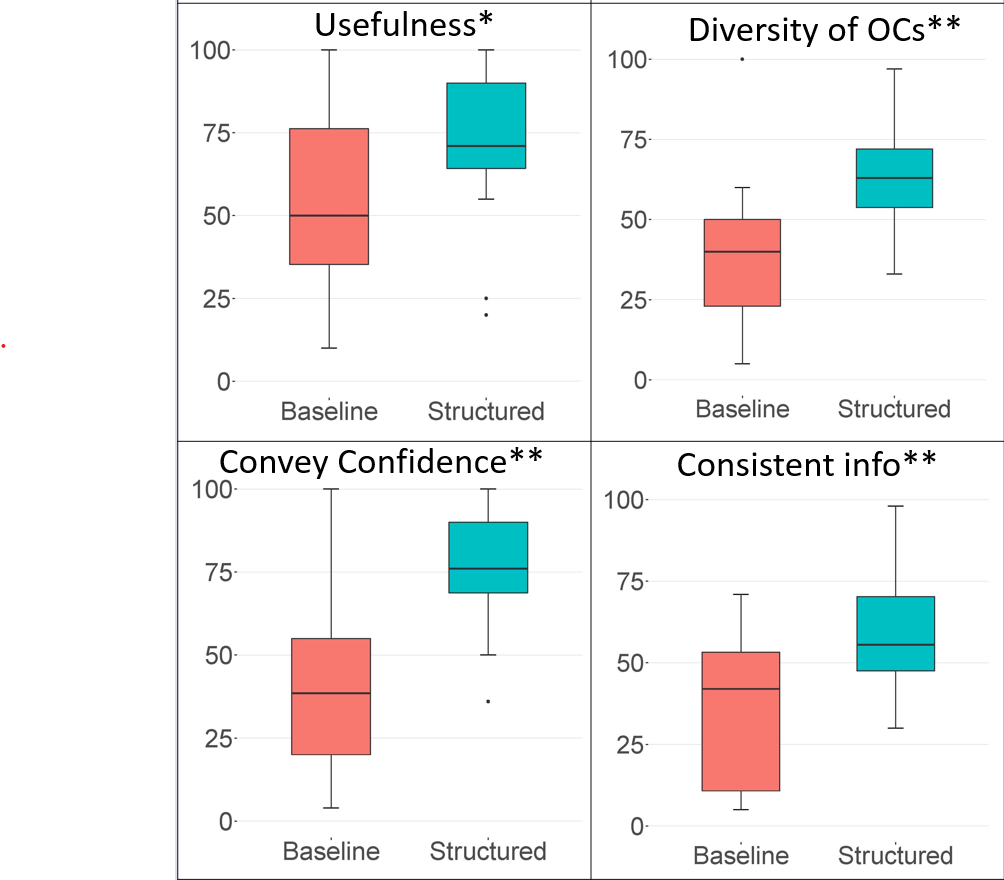
Our results illustrate the potential for a structured annotation tool to help analysts make more useful, diverse, and consistent OCs.
Current and Future Work
In our current and future work, we are developing AI-based tools that will integrate with our annotation tool. These AI tools will
- predict places where OCs are needed
- predict the types of OCs based on the taxonomy of OC types
- predict the content needed for OCs, and
- provide confidence scores that analysts can use to filter the AI predictions.
We are also exploring ways to incorporate these AI predictions into the analyst workflow in order to give them control and flexibility in how they utilize the AI teaming features.
This material is based upon work done, in whole or in part, in coordination with the Department of Defense (DoD). Any opinions, findings, conclusions, or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the DoD and/or any agency or entity of the United States Government.
- Categories: