SANDGLOW
Paul N., Nhat N.
Laboratory For Analytic Sciences

Challenge: Can open source multimodal LLMs be helpful for automated intelligence analysis of video?
Advances in multimodal language models have revolutionized the field of video summarization, enabling AI systems to automatically condense complex visual content into concise and meaningful summaries. Our research from the SCADS conference capitalizes on the capabilities of these models to demonstrate unprecedented performance in video summarization tasks, surpassing previous state-of-the-art results. By building upon the power of multimodal LLMs, we have successfully applied these models to a range of diverse challenges, from news broadcasting to movie trailers, demonstrating their potential for real-world impact and reinforcing their reputation as a leading approach in computer vision.
Building on the recent advancements in video summarization made possible by GPT-4o, our research aims to explore the feasibility of adapting open-source models to operate effectively within air-gapped network environments. By leveraging models like Phi3.5-vision, we investigated the potential benefits and challenges of incorporating multimodal learning techniques in video summarization applications, laying the groundwork for future work in this rapidly evolving field.
Methodology
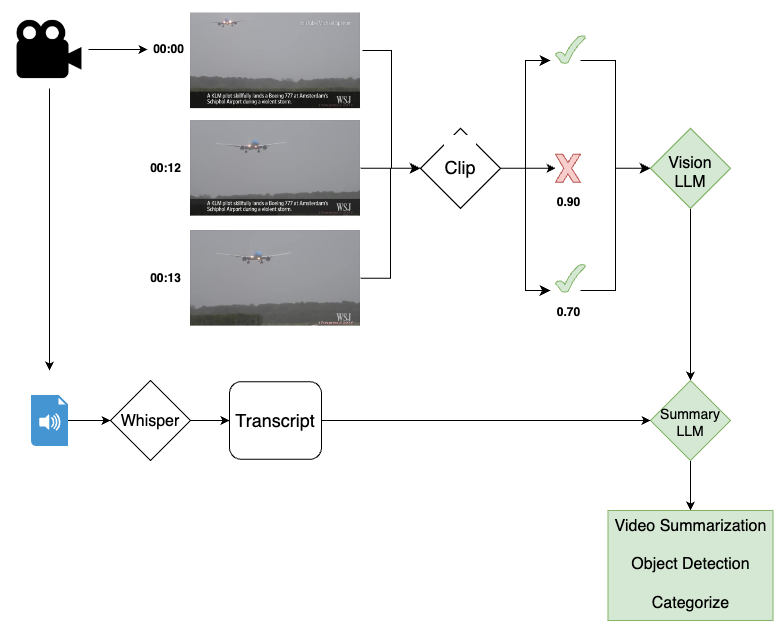
Our approach leveraged a multi-step pipeline to condense complex videos into concise summaries. First, each video was divided into one-second interval images, which were then embedded with relevant metadata using OpenAI’s clip embeddings. The cosine similarity between these image-embedding pairs was calculated to identify visually dissimilar frames that could be discarded. Frames with similarities below a predetermined threshold were retained, while those above the threshold were eliminated. The remaining frames were subsequently fed through Phi3.5-vision, which utilized their spatial and semantic information to generate video summaries. To further refine these summaries, we aggregated the output of Phi3.5-vision using Mistral-Nemo, a state-of-the-art summarization model. If an audio transcript was present for a given video, our system transcribed the audio into text using OpenAI’s Whisper model and also fed this text into Mistral-Nemo to create a final, multimodal summary of the video content. By combining visual and textual summaries, we were able to produce more comprehensive and informative video summaries that captured the essence of the original footage.
Our experiment yielded groundbreaking results, demonstrating a previously unknown level of performance in capturing complex temporal relationships within videos. Notably, even simple tasks such as detecting an aircraft taking off or landing, which have long been considered challenging for traditional video models, were successfully accomplished with ease. This is particularly significant given the longstanding difficulties in developing video machine learning models that can effectively represent and understand dynamic events over time. The ability of our system to summarize a one-minute long video, a task notoriously difficult for traditional video models, represents a major breakthrough. Moreover, this initial success offers a promising glimpse into the vast capabilities of multimodal LLMs, which are just beginning to be explored. As we continue to refine and expand upon our approach, it is clear that these models hold immense potential for tackling some of the most difficult problems in computer vision and video analysis.
Summarization
Our multimodal LLM achieved a thrilling application in summarizing a video trailer for the iconic Fast and Furious film. The algorithm effortlessly navigated the rapid-fire cuts, high-octane action sequences, and witty dialogue that peppered the trailer, distilling its essence into a concise summary of the movie’s key moments. What struck us as particularly remarkable was the model’s ability to grasp the nuances of different camera angles, from sweeping drone shots to intimate close-ups capturing characters’ emotional expressions, and how these visual cues contributed to building tension and excitement in the narrative. The algorithm also effectively captured the ebb and flow of the dialogue, distilling the movie’s central themes into a compelling narrative summary.
We deployed our multimodal summarization pipeline on NVIDIA GPUs using Ollama and Python3, achieving remarkable efficiency and scalability. However, despite its effectiveness, we found that our system was limited by hardware constraints, ultimately yielding best performance with a 50k context window on a single GPU. Notably, scaling to four GPUs enabled us to achieve a much larger 128k context window, demonstrating the significant improvement on model accuracy.
Our multimodal LLM successfully showcased its capabilities by summarizing an 8-minute Call of Duty map walkthrough video for Terminal. The algorithm extracted key strategies, objectives, and player movements from the video, producing a concise summary that provided a high-level overview of the gameplay experience. This condensed summary was not only informative but also actionable, enabling fully automated analysis and evaluation of the game’s mechanics without requiring manual review or interpretation. This capability is particularly valuable for automated intelligence activities, where rapid and accurate analysis can inform decision-making and support strategic operations.
Finally, our prototype has demonstrated exceptional scalability in summarizing long-form video content. Most recently, we successfully condensed an 1-hour PBS News video on a critical global development issue into just a handful of paragraphs. This achievement is notable, as the input video was approximately 8 times longer than our previous longest test case. The model’s ability to scale up without sacrificing accuracy or comprehension has significant implications for high-stakes environments where timely and accurate information is crucial for informed decision-making.
Object Detection
In a follow-up experiment, our team leveraged the multimodal capabilities of our LLM to tackle basic object detection in video. By modifying the prompt used for the Phi3.5-Vision model, we discovered that incorporating specific object detection parameters allowed the model to output a rich array of information about each detected object within a video. This breakthrough resulted in impressive outputs from Mistral-Nemo, including the make and model of every vehicle identified, its color, passenger presence, and even license plate numbers when visible. The model’s accuracy was remarkable, identifying everything from high-performance sports cars to basic minivans with unprecedented precision. This achievement marks a crucial step towards building the foundational elements of video-based search, where users can seamlessly query large video datasets by specifying criteria such as vehicle make to receive a time range the object is seen in the video.
Categorization
Building on our previous successes in video summarization and object detection, we next explored the application of our multimodal LLM to video categorization using summarization tasks. By feeding the summaries generated by Phi3.5-Vision into Mistral-Nemo, we achieved remarkable results in classifying a 1-hour long PBS News video on a critical global development issue into a concise one-to-five word category. Our system accurately categorized the PBS news video as ‘Politics/Government’, demonstrating the effectiveness of our multimodal LLM in capturing key concepts from videos. This achievement not only opens up significant opportunities for efficient video analysis and triage but also enables us to quickly identify the relevance of a video. This avoids wasting unnecessary GPU resources and improves overall system performance. By doing so, we can reduce computational costs while maintaining accuracy.
Results
One Minute Video



Summary with Transcript Mistral-Nemo, Phi3.5-Vision:
Here is a concise summary of the video and audio content:
‘The video opens with a Boeing 777 aircraft navigating through violent storm conditions over Amsterdam’s Schiphol Airport. Despite the challenging weather, the pilot demonstrates remarkable skill in steering the plane and safely touching down on the runway during the storm. The audio initially plays ‘Norske Lundsjö, followed by an acknowledgment of viewers at the halfway point: ‘Thanks for watching!”
Object Detection with Mistral-Nemo, Phi-3.5-Vision:
{
"name": "Aircraft",
"description": "A commercial airplane with the registration number '777' and the logo 'KLM' on the tail.",
"count": 5,
"start_end": [
{"start": 0, "end": 48}
]
}
Video Category with Mistral-nemo, Phi3.5-Vision: “Airplane Landing in Storm”
Eight Minute Video
Summary with Transcript Mistral-Nemo, Phi3.5-Vision:
The video is a promotional content for NextGenTactics.com, targeting serious gamers interested in Modern Warfare 2 tactics and strategies. It features gameplay assessments on maps like Terminal, Crossroads, and others, with the player ‘Guns4Hire’ (real name: Alex) emphasizing the importance of avoiding teammates to get kills and using handguns effectively. Throughout the video, Alex demonstrates his skills with weapons like the M9 and Uzi, while also discussing proper camping techniques and the use of Claymores. He showcases his expertise in first-person shooter gameplay, navigating various indoor and outdoor environments, and engaging in combat with enemies.
Video Category: First-Person Shooter Gameplay
One Hour Video



Video Category with Mistral-nemo: “News/Politics”
Summary with Transcript Mistral-Nemo, Phi3.5-Vision:
**Final Summary:**’
The video compilation covers a wide range of topics, including political news, natural disasters, community resilience, and cultural events. Here’s a concise summary:
**Political News:**
- The segment focuses on the U.S. midterm elections, featuring interviews with candidates discussing their campaigns and strategies.
- International politics are also covered, with discussions on the French election results and their global implications.
**Natural Disasters and Community Resilience:**
- The compilation includes footage of wildfires in Maui, Hawaii, highlighting the destruction caused by the fires and the ongoing recovery efforts. It also features interviews with residents affected by the disaster.
- There is a focus on the health impacts of the wildfires, including mental health challenges faced by survivors.
‘**Cultural Events:**
- The video compilation includes scenes from a Cunard cruise, showcasing luxurious amenities and scenic views available on their cruises. It also features a promotional piece for PBS News Hour West, highlighting the availability of the program on the PBS Video app.
- Additionally, there is a segment showcasing the art of cooking, with close-ups of gourmet dishes and culinary techniques.
Time Range Search



Mistral-Nemo, Phi-3.5-Vision:
black car
```json
[
{
"count": 3,
"start_end": [
{
"start": 29,
"end": 59
}
],
"description": "A black sports car with a sleek design, possibly a Ferrari"
}
]
```
orange car
```json
[
{
"name": "Car",
"description": "A bright orange sports car with a distinctive green and black design on the rear, with license plate 'KMJ1366'.",
"count": 5,
"start_end": [
{
"start": 59,
"end": 74
}
],
"driver": "A person with a bald head and sunglasses",
"passenger": "A person with blonde hair and sunglasses"
}, …
]
```
Summary with Transcript Mistral-Nemo, Phi3.5-Vision:
The video opens with a detailed showcase of a modified Nissan 350Z sports car, featuring maintenance work and high-speed driving scenes [0:00-23s]. A brief conversation about the car’s retail price and brand (‘Ferrari’) occurs during this segment. The scene then shifts to a coastal road twilight drive [23-30s], followed by an interaction between two individuals in a car at dawn or dusk [30-46s]. Later, high-performance sports cars are shown racing on the road, accompanied by lyrics from songs playing in the background [62-92s]. The video concludes with promotional materials for the Fast & Furious film series [92-117s].
Video Category with Mistral-Nemo: ‘High-Speed Sports Car Showcase’
Future Work
Our future work will focus on rigorously testing our prototype on internal datasets to further refine its performance and expand its capabilities. We plan to develop a publicly available API for integrating our multimodal LLM into various applications, enabling developers to seamlessly leverage its summarization and object detection abilities in their own projects.
We are also excited to explore the potential of LLaMA3.2-Vision, a recently released variant of the Phi3.5-Vision model, which has demonstrated improved performance on certain tasks. Additionally, we intend to investigate the application of Pixtral, another state-of-the-art object detection model, in conjunction with our multimodal LLM to further enhance its capabilities.
By combining the strengths of these models and APIs, we aim to create a more comprehensive and robust video analysis platform that can tackle even the most complex tasks. Furthermore, we plan to continue pushing the boundaries of what is possible with multimodal LLMs, exploring new applications and use cases.
However, our current prototype’s reliance on reflection with Mistral-Nemo due to GPU memory constraints poses significant limitations. To overcome these challenges, future work will focus on developing new architectures that can efficiently utilize GPU memory. One promising avenue of research is the integration of Ollama’s efficient inference capabilities with LLaMA3.2-Vision.
Furthermore, we plan to leverage Ollama’s advanced GPU resource allocation capabilities to explore its potential in integrating with agent workflows, enabling the efficient management of computational resources across multiple tasks and models. This will ultimately pave the way for the widespread adoption of automatic video analysis in intelligence community projects.
This material is based upon work done, in whole or in part, in coordination with the Department of Defense (DoD). Any opinions, findings, conclusions, or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the DoD and/or any agency or entity of the United States Government.
- Categories: