SAKURA: Synthetic Cyber Knowledge Graph
LAS: James S., Felecia ML., Donita R.
Academic Collaborator: The University of North Carolina at Pembroke, Harry Lamchhine, Fahim Tanzi, Raj Shinde, Dr. Prashanth BusiReddyGari

The Evolution of Data Generation
The rapid escalation of cyber threats has transformed cybersecurity into a battlefield where data stands as both the armor and the weapon. However, obtaining high-quality datasets for training predictive models poses a challenge due to privacy concerns, biases, and limited availability. That’s where we introduce SAKURA—a Synthetic Cyber Knowledge Graph and visualizer designed to address these gaps with precision and innovation.
Background and Description
Traditional knowledge graphs often fall short due to incomplete entries, outdated relationships, or restrictions on sensitive data sharing. These limitations hinder the development of robust machine learning models for tasks like link prediction, anomaly detection, and cyber threat analysis.
SAKURA tackles these issues by generating synthetic cyber threat intelligence (CTI) knowledge graphs that mirror real-world dynamics. By embedding complex relationships among entities such as malware, threat actors, vulnerabilities, and attack campaigns, SAKURA creates a controlled environment for researchers to experiment and innovate. This synthetic approach ensures both realism and privacy compliance, opening new avenues for testing link prediction models without compromising sensitive data.
What sets SAKURA apart is its evolution from simpler data generation tools to advanced frameworks. Initially relying on libraries like Python Faker, SAKURA has since incorporated sophisticated technologies to become a fully interactive and dynamic platform powered by LangChain and GPT-4 Turbo.
The Models and Datasets
Link Prediction Models
Link prediction is a fundamental task in knowledge graph research, where the objective is to predict missing links or relationships between entities. This task is crucial for completing knowledge graphs, uncovering hidden relationships, and enabling applications such as recommendation systems and cyber threat detection.
The primary objective of this research is to evaluate the utility of synthetic datasets like SAKURA in link prediction tasks compared to well-established benchmarks such as FB15k and WN18. We aim to demonstrate that synthetic datasets can produce results comparable to or better than traditional datasets while preserving data privacy.
To evaluate the effectiveness of synthetic datasets generated by SAKURA, we employed two state-of-the-art link prediction models:
- SimplE:
- Captures complex relational patterns using two embeddings for each entity and relation.
- Efficient and flexible, making it ideal for robust link prediction tasks.
- RotatE:
- Models relationships as rotations in complex space, capturing symmetry, inversion, and composition.
- Suitable for datasets with intricate relational structures.
Datasets Used
To benchmark the performance of the link prediction models, we utilized the following datasets:
- FB15k:
- A widely used benchmark dataset, containing dense relational structures derived from Freebase.
- Known for its high relational diversity, making it an essential dataset for evaluating the robustness of link prediction models.
- WN18:
- A subset of WordNet, focusing on semantic relationships and hierarchical structures.
- Useful for testing the ability of models to understand and predict semantic hierarchies effectively.
- SAKURA:
- A synthetic knowledge graph generated using the STIX 2.1 standard, designed to mimic real-world cyber threat intelligence scenarios.
- Created in JSON bundles, the data was converted to a format compatible with the SimplE and RotatE models.
- SAKURA balances the need for realism and control, ensuring that synthetic data maintains essential relational properties without exposing sensitive information.
Key Experimentation Steps
- Data Preparation:
- Converted SAKURA’s JSON bundles into FB15k-style format.
- Standardized entity and relation identifiers across all datasets.
- Model Training:
- Trained SimplE and RotatE on FB15k, WN18, and SAKURA datasets.
- Recorded loss and accuracy metrics over 1000 iterations.
- Evaluation Metrics:
- Loss: To assess convergence rates and optimization quality.
- Accuracy:
- Hits@K: Correct predictions within the top K results.
- Mean Reciprocal Rank (MRR): Emphasizes higher-ranked correct predictions.
- Mean Rank (MR): Average rank of correct predictions; lower is better.
Results and Observations
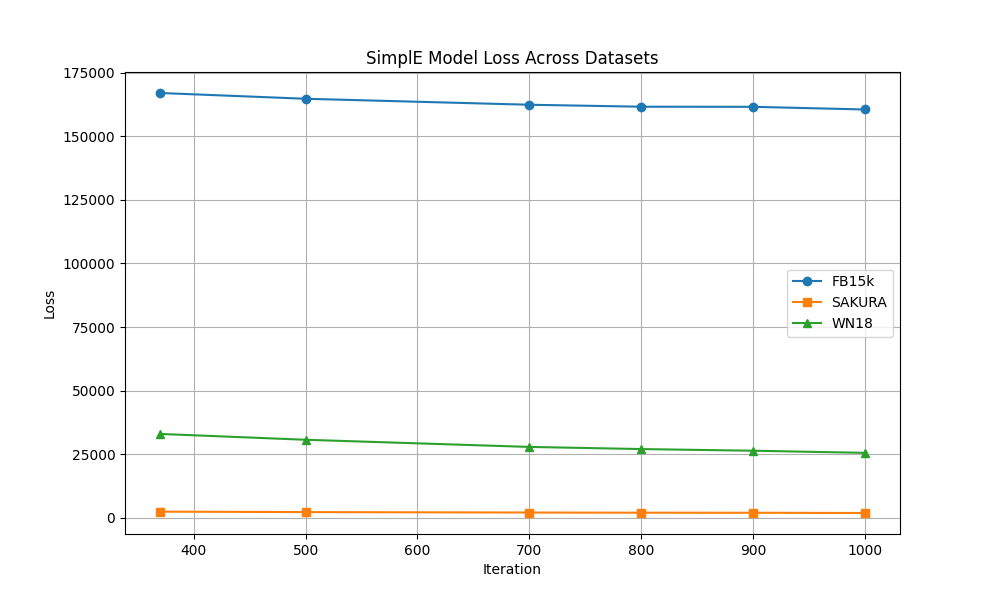
- Loss Comparison:
- The SAKURA dataset consistently resulted in lower loss values compared to FB15k and WN18, demonstrating faster convergence and better model optimization.
- Accuracy Metrics:
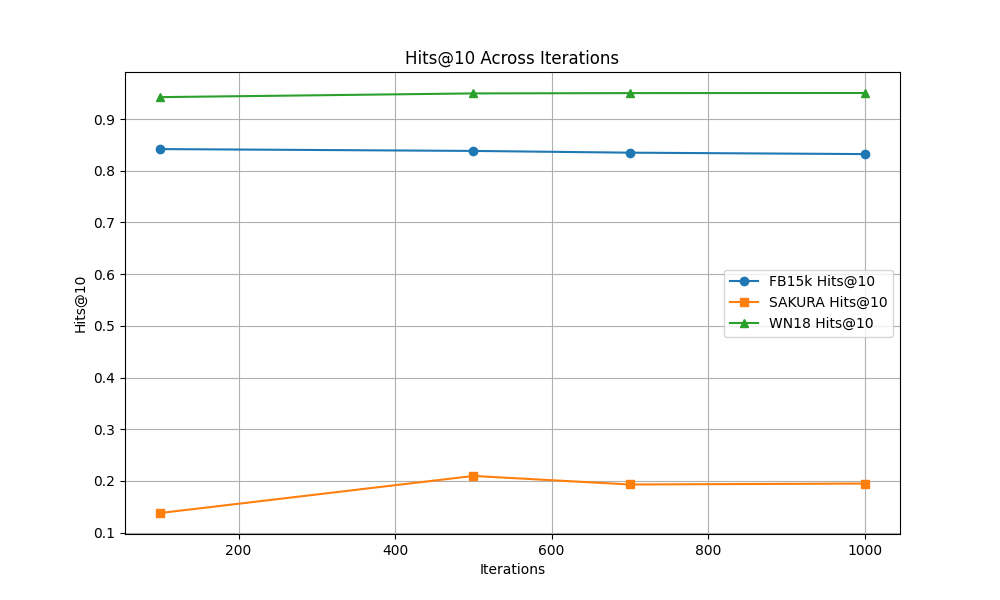
- Hits@10:
- FB15k: ~60%
- WN18: ~55%
- SAKURA: ~70%
- MRR:
- FB15k: 0.45
- WN18: 0.40
- SAKURA: 0.55
- MR:
- FB15k: 100 (lower is better)
- WN18: 110
- SAKURA: 80
- Hits@10:
Synthetic Data Quality:
- Despite being synthetic, SAKURA produced meaningful and high-quality data that outperformed traditional benchmarks in both loss reduction and accuracy metrics.
- Its ability to replicate realistic relational patterns validates the utility of synthetic datasets for knowledge graph research.
Technical Overview
SAKURA’s architecture focuses on interactivity and real-world usability which sets it apart from traditional knowledge graph systems. The platform’s key components include:
- LangChain and GPT-4 Turbo Integration: SAKURA employs LangChain to structure domain-specific prompts that guide GPT-4 Turbo in generating semantically rich and contextually coherent cyber threat data. This dynamic approach ensures that each entity and relationship is generated with precision and realism, mimicking real-world cyber intelligence scenarios.
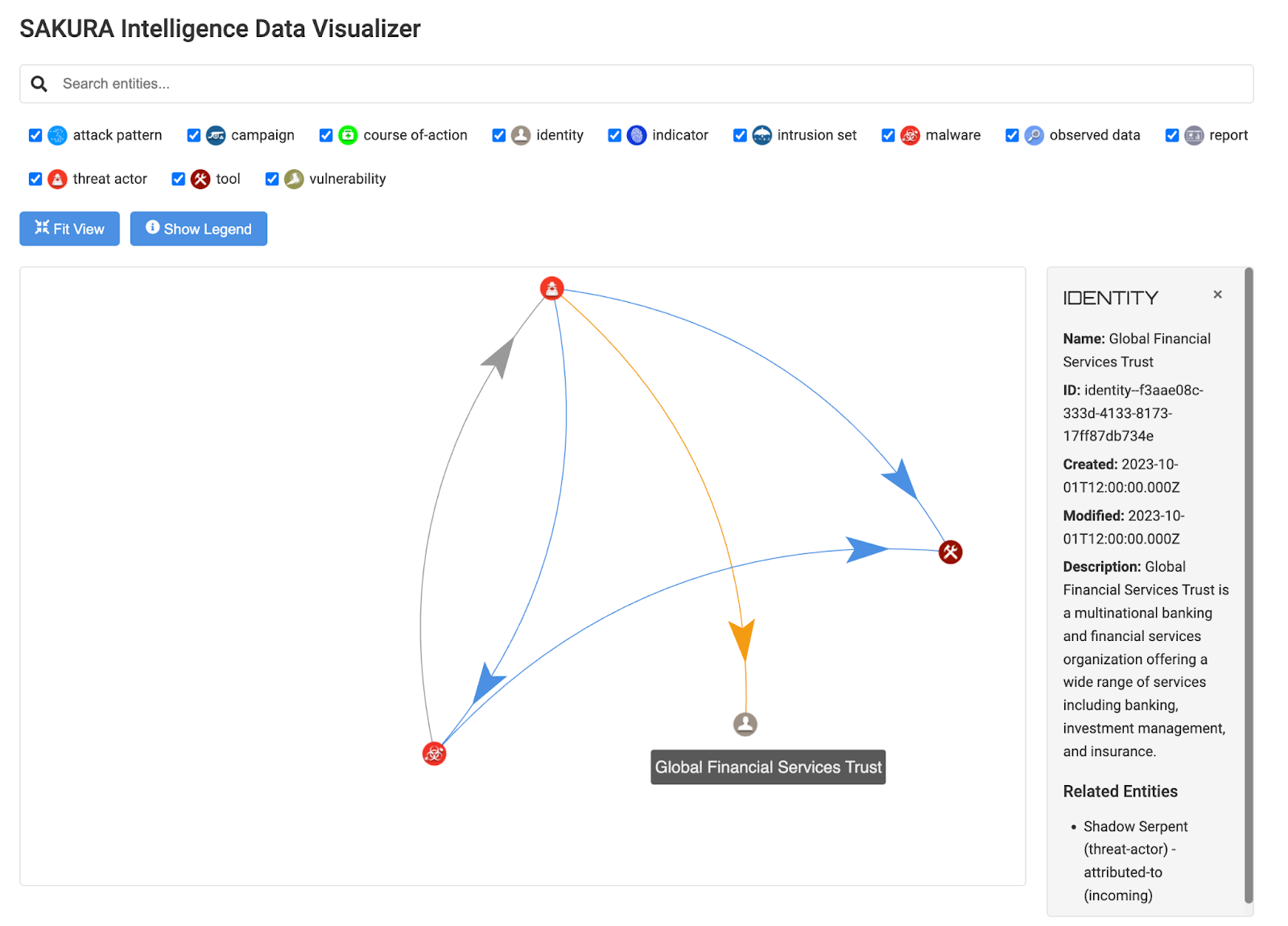
- Interactive Graph Visualization: Leveraging advanced visualization tools like ForceGraph2D which is a force-directed iterative layout to represent graph data structure in a 2-dimensional canvas, SAKURA provides an intuitive and interactive interface for exploring the knowledge graph. Users can navigate entities, and analyze threat patterns dynamically, making the platform both user-friendly and highly effective for research.
- Dynamic Relationship Mapping: The platform’s natural language-driven approach ensures that relationships between entities are logical and contextually aligned. For example, a threat actor might be linked to a malware instance under a “deploys” relationship, offering clear and actionable insights.
- Customizability for Research Needs: SAKURA is designed to adapt to diverse research requirements. Its modular architecture allows users to define new entity types, relationships, or attributes, ensuring the platform remains relevant as cyber threats evolve.
- Automation and Scalability: The use of LangChain enables automated generation of large-scale datasets, while GPT-4 Turbo ensures that these datasets maintain high quality and contextual accuracy. This combination allows SAKURA to scale seamlessly, accommodating both small-scale research and large-scale operational needs.
SAKURA is more than just a tool; it is a dynamic ecosystem designed to push the boundaries of cybersecurity research and practice. By integrating cutting-edge technologies and focusing on user-centric design, it empowers researchers and practitioners to tackle cyber threats with unprecedented efficiency and insight.
Applications in Cybersecurity
SAKURA’s capabilities extend beyond academic research, offering real-world applications in:
- Threat Detection: Simulating diverse attack scenarios helps organizations test and refine detection systems against evolving cyber threats.
- Incident Response Training: SAKURA’s realistic data enables cybersecurity teams to conduct drills and simulations, preparing them for real-life incidents.
- Vulnerability Analysis: By generating data that mirrors complex cyber ecosystems, SAKURA aids in identifying potential weak points in security infrastructures.
- AI Model Development: The dataset provides a robust foundation for training machine learning models to predict and mitigate threats effectively.
Future Directions
SAKURA’s journey is just beginning, with several exciting enhancements planned for the future:
- User-Customizable Entities:
- Enable users to define their own entity names and descriptions.
- Tailor datasets to specific needs, reducing reliance on OpenAI’s API-generated randomness.
- Knowledge Graph Embeddings:
- Use machine learning to generate low-dimensional representations of SAKURA’s STIX entities and relationships.
- Preserve semantic meaning while enabling efficient computation and analysis.
- Publication of Research Findings:
- Publish a comprehensive research paper detailing SAKURA’s performance against benchmark datasets.
- Collaborative Expansion:
- Partner with industry leaders to refine SAKURA’s utility and explore its applications in operational settings.
About The University of North Carolina at Pembroke
The University of North Carolina at Pembroke (UNCP) is a Native American Non-Tribal Serving Institution located in Pembroke, NC, and was designated a Center of Academic Excellence in Cyber Defense for 2023–2028.In 2023, the LAS assisted with establishing a Minority Serving Institution (MSI) Cooperative Research and Development Agreement (CRADA) with the UNCP, which provides additional partnership opportunities with the Department of Defense (DoD) in the field of cybersecurity. Through the MSI CRADA, the LAS has partnered with Dr. Prashanth BusiReddyGari (UNCP Director of Cyber Defense Education Center) on two senior design projects, Synthetic Cyber Knowledge Graphs (Fall 2023/Spring 2024) and Internet Routing Integrity (Spring/Fall 2024). These projects continue the LAS’s focus on expanding its academic outreach to MSIs in North Carolina and giving students the opportunity to work on real-world projects that will have an impact on the DoD mission.
This material is based upon work done, in whole or in part, in coordination with the Department of Defense (DoD). Any opinions, findings, conclusions, or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the DoD and/or any agency or entity of the United States Government.
- Categories: