Operationalization of Audio Analytics for Triage: Approach, Results, and Challenges
Introduction
The aim of this research is to equip analysts with tools to efficiently locate areas of interest in large audio datasets, enabling the identification of valuable patterns and insights. By developing algorithms to detect mission-relevant sounds and high-arousal speech, we intend to provide a systematic approach to explore and understand audio data. Building on prior research, we are now focused on transitioning these capabilities into operational environments, emphasizing secure deployment and system compatibility.
Background
This year’s work builds on our 2023 research, which introduced foundational algorithms for voice characterization (VC) and sound event detection (SED). These algorithms performed well on unclassified, “in-the-wild” data, providing a strong basis for further adaptation. In 2024, our focus has shifted to integrating these algorithms into secure mission settings, which involves overcoming challenges related to compatibility, modularity, and security compliance.
Goals
The objectives for this year are:
- Transition VC and SED pipelines into mission environments, ensuring adaptability and security.
- Evaluate algorithm performance on mission-specific data to validate operational effectiveness.
- Develop inference prototypes to facilitate seamless integration into existing speech and sound analytic platforms.
Achieving these goals requires designing flexible model architectures that can process mission data efficiently, providing low-latency results while meeting the stringent security standards necessary in sensitive settings.
University of Texas Dallas: The Multimodal Signal Processing Lab
We have been collaborating with LAS performer University of Texas at Dallas (UTD), led by Dr. Carlos Busso, director of the Multimodal Signal Processing (MSP) Lab, for the past few years to expand our capabilities in voice characterization, particularly in speech emotion recognition (SER).
- 2023 Contributions: Last year, UTD developed innovative approaches in speech emotion recognition (SER) using self-supervised learning (SSL) with domain-specific tasks. This method leverages audio data to generate meaningful representations for emotional characterization, while reducing the need for extensively labeled data. Through domain-specific training, the models learned to adapt their understanding of emotion for mission-relevant contexts, enhancing their utility in real-world applications.
- 2024 Research: This year, the UTD is exploring language-specific adaptations for cross-lingual speech emotion recognition, allowing our models to maintain accuracy across languages and dialects. With this feature, the SER pipeline is expected to provide deeper insights into the emotional context of multilingual datasets, improving the relevance of analytic results for a broader range of data.
Methods
The project’s methods are designed to translate academic models into secure, high-performance mission tools. Key efforts include optimizing models for secure environments, creating flexible inference prototypes, and developing modular integration techniques.
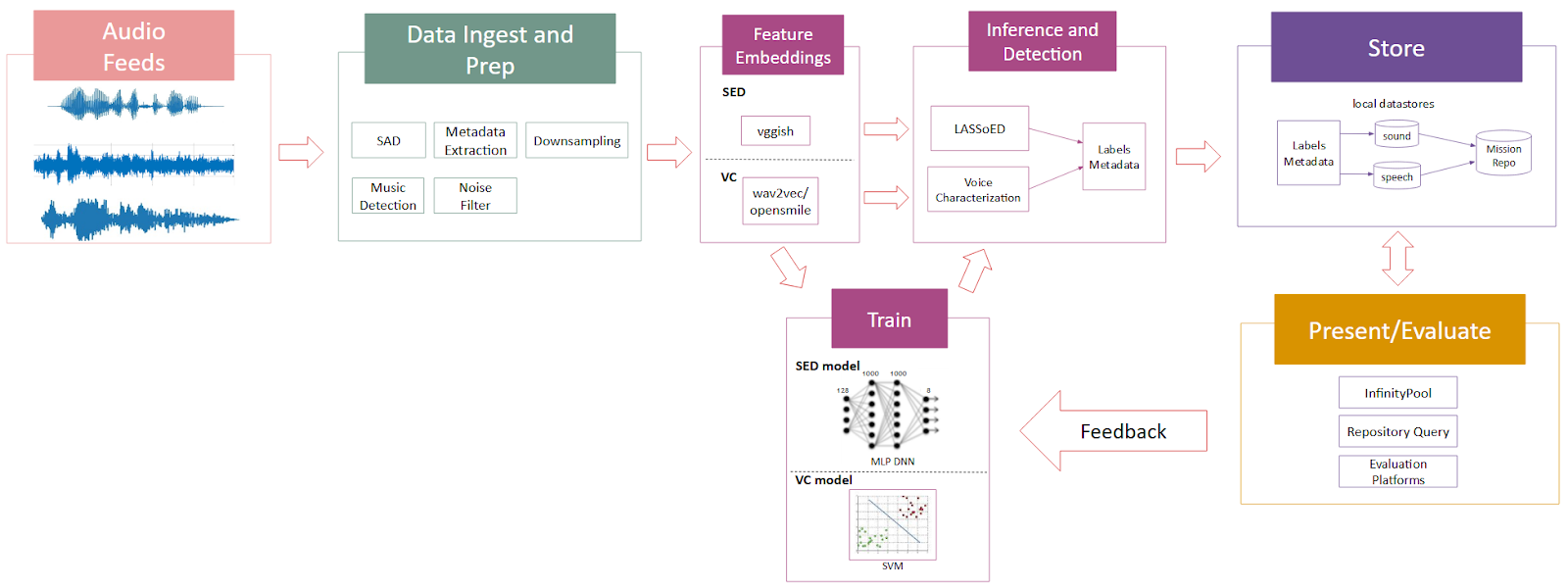
Porting and Optimization of VC and SED Algorithms
The VC and SED algorithms were originally developed and trained on open datasets. However, to meet the mission environment’s specific demands, they required significant adjustments:
- Code Optimization: To adapt the research algorithm for resource-constrained environments, we optimized and refactored the code for scalability and performance and to reduce computational load. These optimizations were essential for enabling batch and near real-time processing while preserving algorithm reliability.
- Inference Prototyping: Prototype inference modules were developed to facilitate integration into mission environments. These modules are designed for easier deployment within secure systems, emphasizing flexibility and low-latency processing.
Integration Techniques
The project emphasized creating modular audio pipelines that enable scalable deployment across various environments. Key components such as data preprocessing, feature extraction, model inference, and post-processing were developed to be used as standalone modules, allowing for integration into existing analytic frameworks.
Techniques such as reducing latency and improving resource utilization were essential to achieving performance benchmarks, especially for applications requiring near-instantaneous feedback.
Results
Sound Event Detection (SED) on Mission Data
The SED model demonstrated its capacity to accurately identify sound classes within a representative audio dataset from a mission context. The model successfully recognized sounds, distinguishing between various segments. This confirms the model’s potential for detecting relevant sounds in mission environments, where the ability to discern multiple sound sources in complex audio data is vital.
Evaluation Challenges
Although these algorithms showed promise, several challenges emerged during evaluation. Key among these were data availability, security compliance, and the unique requirements of mission environments.
- Dataset Acquisition and Annotation: Relevant mission audio datasets with labeled data are scarce, complicating the evaluation process. The limited availability of labeled mission datasets is a significant challenge as it hampers the ability to evaluate and benchmark algorithms using real-world data. Additionally, annotating existing data can be both complex and time-consuming in accurately labeling sound and high-arousal speech events. This complexity is further exacerbated by the need for high-quality, consistent annotations to ensure reliable performance evaluations.
- Required compliance and policy review: All models intended for mission environments must pass newly implemented security, compliance and policy review processes. Due to this requirement, evaluations are currently on hold and will resume once compliance checks are complete.
Future Work
With initial evaluations showing encouraging results, future work will focus on refining these algorithms and addressing challenges specific to mission environments. Our primary objectives moving forward include:
- Completing Evaluations with Mission Approved Models: Once the models pass the policy reviews, we will continue evaluations to validate their suitability in mission settings.
- Integrating Feedback Loops: To continually improve model accuracy and relevance, we will investigate incorporating feedback loops that allow analysts to provide input on model performance. This feedback will support ongoing model adjustments and inform labeling efforts.
- Transitioning to Speech and Sound Analytic Platforms: Our goal is to fully integrate these audio models into existing mission analytic platforms. By bringing sound event, high-arousal and multilingual emotional detection capabilities into these platforms, analysts will have access to enhanced audio analytics for triaging complex audio data to discover unknown unknowns.
Results Summary and Next Steps
In summary, the VC and SED algorithms have been ported for mission requirements, with early evaluations highlighting their utility in real-world conditions. With ongoing efforts to meet security standards, access and use of relevant datasets for evaluation, and integration of these analytics into mission settings, our team is dedicated to creating a sustainable, feedback-driven approach to audio analysis. As we advance, we look forward to transitioning these algorithms, providing analysts with cutting-edge tools to interpret and understand mission-relevant audio data effectively.
Conclusion
The operationalization of audio analytics for triage has made significant strides. The project’s progress reflects the potential of advanced audio analytics to provide analysts with actionable insights from complex audio datasets. Through continued refinement and deployment, we aim to create flexible, high-performance models that meet the mission needs for reliable audio analysis, supporting analysts as they navigate increasingly complex data environments.
This material is based upon work done, in whole or in part, in coordination with the Department of Defense (DoD). Any opinions, findings, conclusions, or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the DoD and/or any agency or entity of the United States Government.
- Categories: