Maturing the LAS Model Deployment Service
Troy West - LAS Government Researcher/Software Engineer
Ethan D. - Software Engineer
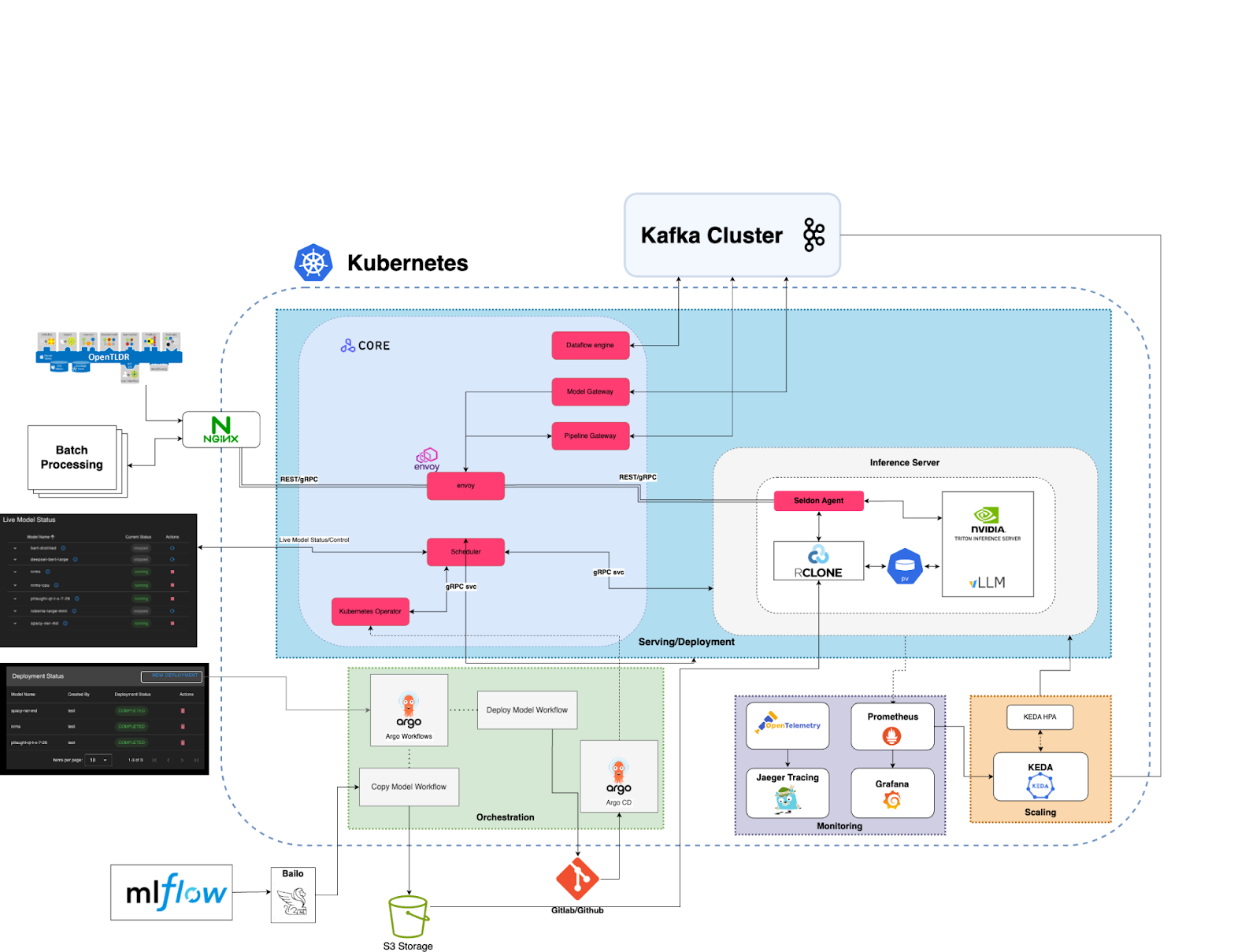
A machine learning (ML) model deployment architecture is a foundational component which is essential to effective use of ML in an enterprise. Establishing a set of consistent, repeatable and iterable methodologies forms a foundation supporting all ML applications and reduces the burden of individual teams to reinvent the wheel each time they seek to use ML. The LAS Model Deployment Service (MDS) is a prototype system creating a cloud provider independent environment for deploying, scaling and monitoring ML models. The MDS intends to serve two core purposes, support LAS research efforts and evaluate solutions for scaling ML models in order to better inform the development of new production environments.
An Elephant in the Room
Why is it more important than ever to invest in infrastructure and methodologies for serving and scaling smaller ML models in a world full of Large Language Models (LLM) and generative AI? I would like to offer 2 reasons why investing in a consistent model serving solution is an essential building block to make the most of the power that LLMs can offer.
First, LLM’s require a lot of infrastructure behind the scenes to support their most useful applications. Retrieval augmented generation (RAG) requires that embeddings of data be created, stored and retrieved in order to be used as context to a prompt to an LLM. We need methods for hosting embedding and other supporting models.
Second, depending on the size of the LLM it can be costly to run at an enterprise level. LLMs are overkill for some tasks, specialized ML models can be smaller and cheaper. Just because you can drive a racecar to the grocery store, doesn’t mean it’s the best method for going shopping.
Team Focus for 2024
Among MDS’s original research goals was to assist users in consistently making model inference available via API, especially users without a technical background in software development. Kubernetes’s flexibility as a platform is amazing for deployment and scaling of ML models, however it is daunting for even experienced users. Without work to abstract some of these complexities we risk simply trading one set of challenges for another.
Building on last year’s successful prototype, the MDS team chose to focus on improving user experience and increasing system stability. This blog will focus more heavily on user experience as it’s an enabling function to test and improve system stability.
Let’s start with some of the challenges we were looking to address:
- How do we get more users to deploy models into the MDS without bogging them down with needing to understand Kubernetes?
- How do we increase system security by limiting user access and still be useful?
- How do we support multiple levels of technical skill? If we oversimplify the system it’s annoying for the more technical users.
- Which parts of the model preparation and deployment process can be automated and how?
- How do we add in some automated testing for uploaded models?
- What are the most challenging tasks for new users when preparing to deploy a model?
To attempt at answering some of these questions we created MDS Commander, a simplified user interface (UI) that targeted the needs of researchers and data scientists. We just needed a wider range of user interaction and identified SCADS 2024 as a prime opportunity. With this target in mind the team chose a set of features that would attempt to answer some of the aforementioned challenges.
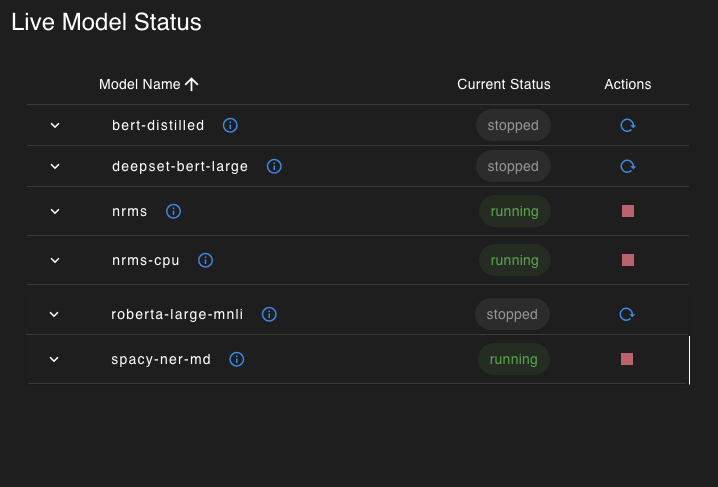
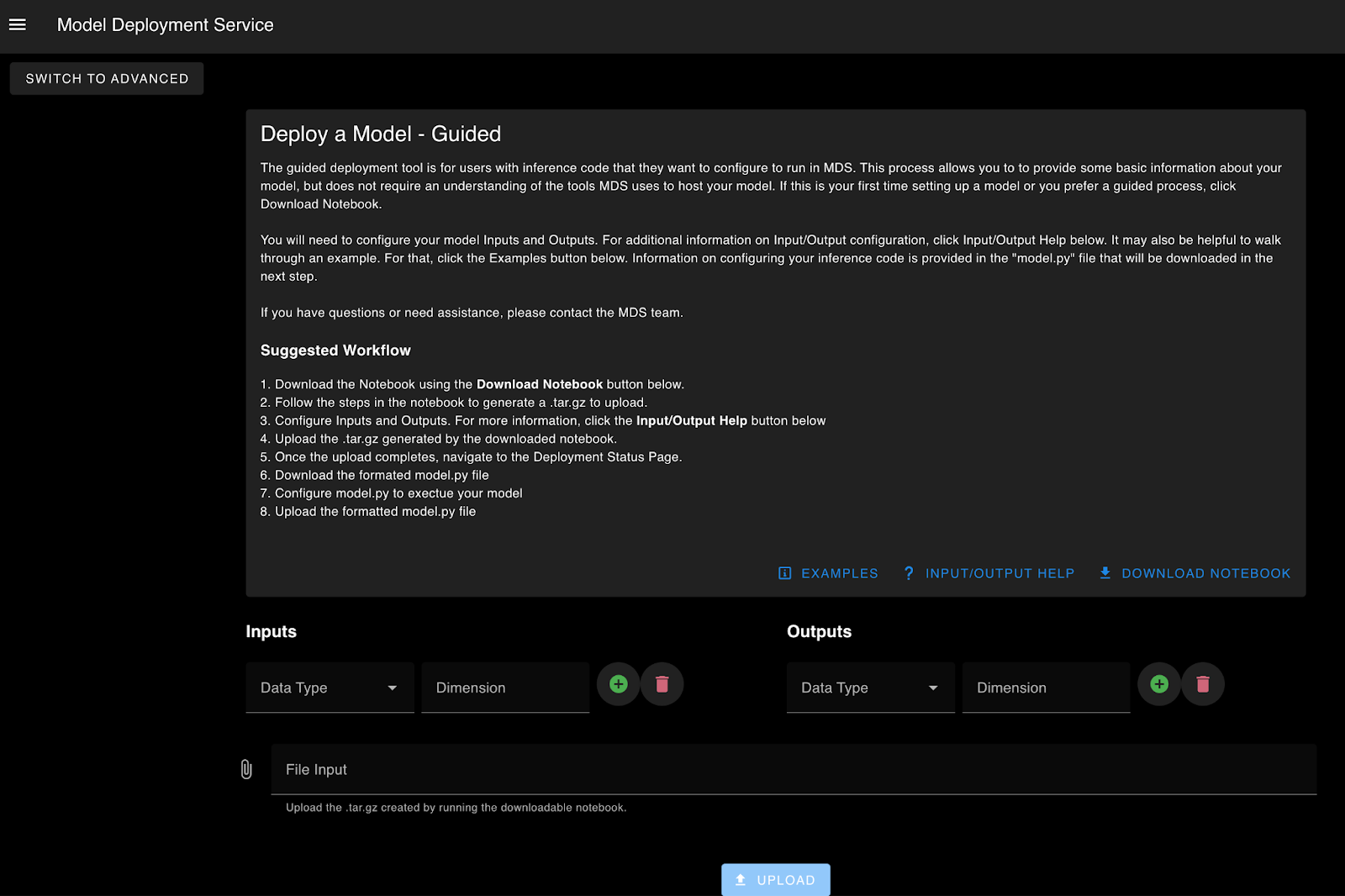
Core MDS Commander UI Features:
- View models available for deployment in MDS
- View models running live in MDS and ready for inference
- Start/Stop models
- Test model inference live in the UI
- Deploy new or updated models
- Guide the upload/deployment process to assist users in deploying new models into MDS
- Automate basic testing of uploaded model artifacts to ensure system compatibility
- Provide advanced modes and API access for automation and more technical users
Underlying techstack and design patterns
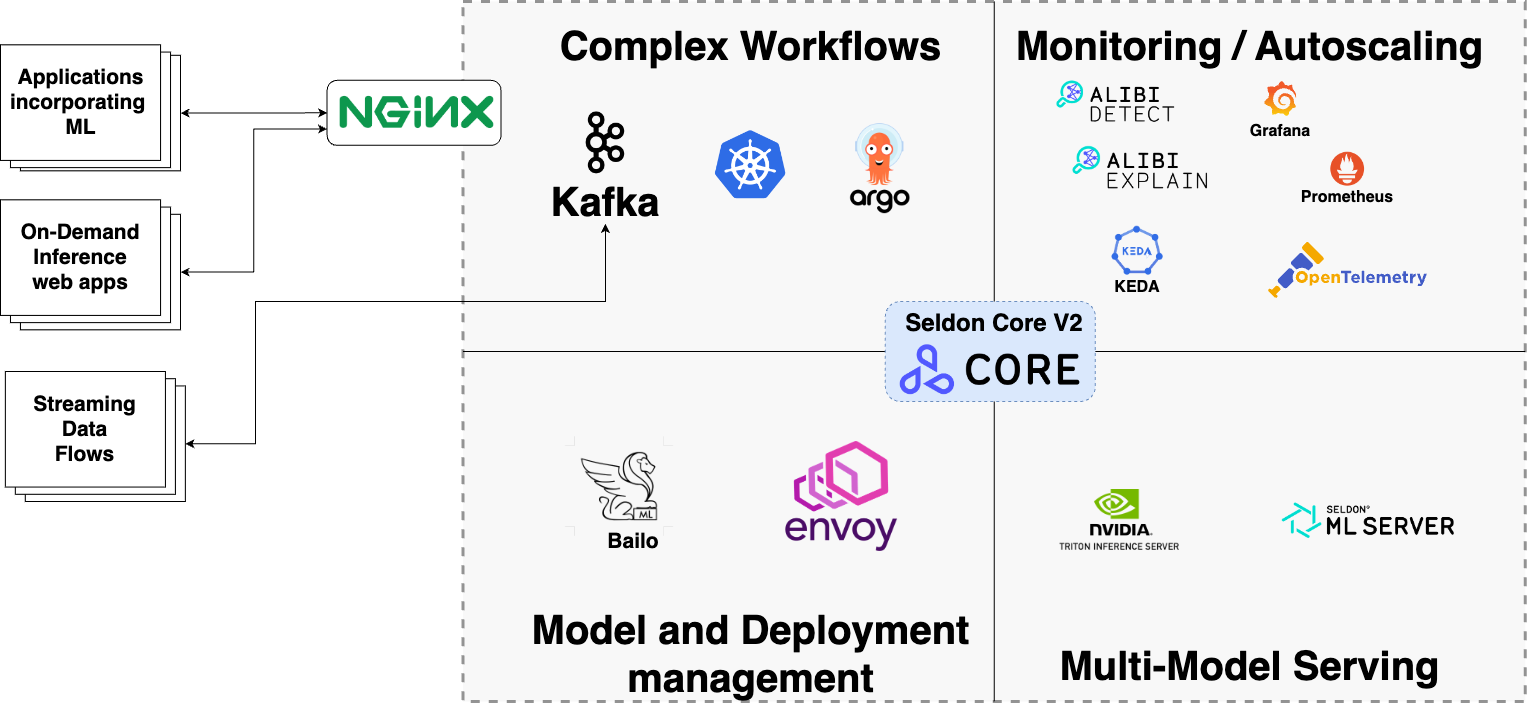
All deployments into Kubernetes are managed via a continuous deployment (CD) service called Argo CD. Argo CD reads from a repository residing in Gitlab or Github treating the repo as a definitive system state and attempts to create this state in a target Kubernetes environment.
Benefits:
- Preserves the MDS’s state allowing it to recover from a failure state and is a common tool already familiar with many teams.
- Greatly reduces the security footprint of MDS, mostly eliminating the need for the average user to access the Kubernetes cluster.
To support automated testing we chose Argo Workflows to create a workflow to ensure the user upload model artifacts and code will successfully load into an Nvidia Triton inference server.
Benefits:
- This will catch many initial issues at least ensuring the user’s upload is minimally compatible with MDS.
We quickly identified one of the most challenging tasks when migrating a model into Nvidia Triton was creating the Triton’s expected project structure, model configuration and bundling python dependencies for deployment. To alleviate some of the burden the MDS team created a guided model deployment process which generated the Triton model configuration and packed all required python dependencies. Once complete these were stored with other relevant model artifacts for immediate deployment.
Benefits:
- The guided process was split into a set of steps that allowed us to prepopulate code templates. Users no longer needed to manually create Triton model configurations or figure out how to correctly package python dependencies or model artifacts.
SCADS Testing
LAS’s Summer Conference on Applied Data Science was a core focus this year as an opportunity to to have a wide number of users from various backgrounds give feedback on the MDS UI.
MDS Commander was successful in lowering the barrier to entry by guiding users through some of the more technically confusing aspects of loading the model of their choice into an Nvidia Triton server. The process for generating initial code and artifacts in the guided deployment process proved useful for the initial creation of the code and artifacts but presented us with a new set of challenges. Users lacked an understanding of how the code could be tested locally and existing logging was insufficient. Users found it frustrating testing changes required uploading a new version and waiting for the deployment to fail.
Suggestions:
- Export a standard template development environment populated with the user’s code similar to the MDS Triton cookiecutter that would allow users to load and test their model in a simpler setting.
- Allow a user to provide a function containing the model’s inference logic and the types of inputs the function expects. The MDS will wrap the function in one of a set of predefined model deployment templates. This represents the most heavily abstracted version of a model deployment removing the user’s need to generate any code outside of the logic needed to run inference.
The testing workflow was successful in evaluating if the model loads into an Nvidia Triton inference server, however this will only catch issues if there are code errors or errors loading the model. This leaves the model inference logic untested and will show that the deployment test passes. If there are errors in the inference logic the user will be unable to receive detailed logs of why their model is failing. The deployment automation also left the users unable to determine how to troubleshoot errors since the system is mostly a black box.
Suggestions:
- Having users upload a sample of an inference request on model upload to ensure the minimal functionality of inference logic.
- Include more robust methods for streaming logs back to a model info page on user request. This should enable the user to perform additional self debugging.
MDS is designed for deployment in secure enterprise environments, this within itself adds to system complexity. Many ML practitioners utilize python libraries which are in turn optimized to abstract as much of the code and configuration as possible. This is excellent for the testing and development workflows but it presents some annoying challenges when transitioning that code to an airgapped inference server.
Libraries for using models often fail to load from a local source. In this case (and in many others) the python library being used by the participant took care of downloading/loading tokenizer weights in the background. There wasn’t a simple way of overwriting where the application would search for the downloaded weights. Eventually it was found that you could manually override a hard coded value to point towards the manually downloaded tokenizer artifacts. Additionally the python library in question would only attempt to load model artifacts on first use. This meant that the deployment tests would pass and the user would not see the failure until they attempted to test the inference API.
Suggestions:
- Load as many artifacts as possible in the Triton initialization function so that the failure happens sooner and can be more easily found in automated testing.
A model deployed in MDS was giving radically different results from the same model running in a Jupyter notebook. This proved a tad more complicated to solve, basically the user was sending raw articles as inference input and the process of converting them to/from JSON requests and sending them over REST dropped some of the article’s unprintable characters. This caused the tokenizer to split the articles differently. This shows at a simple level how important keeping training and production data consistent.
Suggestions:
- Encourage users to encode text to base64 to preserve input when sending raw data to a remote inference API. This ensured that the raw article input stayed nearly identical.
Final Thoughts
It’s a challenging system design problem to determine how much automation and abstraction is needed in order to simplify the complexities of MDS deployments. MDS Commander was an excellent start and made it possible for any of our SCADS users regardless of skillset to test the system. Ultimately the outcome of our SCADS testing gave us a glimpse into just how much more work could be done to improve the user experience.
This material is based upon work done, in whole or in part, in coordination with the Department of Defense (DoD). Any opinions, findings, conclusions, or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the DoD and/or any agency or entity of the United States Government.
- Categories: