Large Language Models for Intelligence Analysis
Mike G, Pauline M, Paul N
Laboratory For Analytic Sciences

The Challenge: Can we show that LLMs can be useful for intelligence analysts?
This post describes observations made at the Laboratory for Analytic Sciences under an umbrella of connected efforts intended to identify trends and establish competencies that will help us build the foundations for AI assisted workflows.
The most immediate utility of LLMs is to aid analysts in translation, summarization, and question answering tasks. Other functions include assistance in drafting and editing communications, composing analytic results, and helping to ensure adherence to analytic tradecraft standards. In the future, useful applications could emerge as tutoring and training partners, critical thinking aids, and planning and orchestrating assistants. And while we now think of this technology as Large Language Models, they are really becoming Large Multimodal Models, and offer the opportunity to consider information not only represented as text, but also by audio, video, image, and graphics. Multimodal solutions will also allow us to consider moving interactions with an AI teammate away from the confines of a screen and keyboard.
The opportunity space is thus enormous. On the downside, deep neural networks, the fundamental technology modern AI is built from, are notoriously opaque. We simply do not understand the non-linearities that produce inferences. This results in a misalignment of what models are doing and what users expect. The most well-known of these misalignments with regards to LLMs is hallucination, which simply boils down to when the next word predicted by the model is not the appropriate next word expected by the user.
So how do we get LLMs to do what we want and how do we know how well they are doing? Fortunately we are not the only ones trying to solve these problems.
Yet, identifying best practices for the control and evaluation of Large Language Models is more difficult than hitting a moving target. Global investments are enormous, and the hype is overwhelming. We can see where the target has been, but we don’t know for certain where it is heading or what shape it will take. Nevertheless, we make an effort to remain informed of trends, gain insight into important concepts, and remain relevant in the face of this disruptive technology. Ultimately, there will be benefits as we learn to apply AI to augment analyst sense making abilities and improve analytic workflows.
The Methodology
This year we have endeavored to experiment with LLMs as much as possible: to not only read about emerging trends, but explore, interact, and experience technology in a hands-on manner, and share information broadly among collaborators from multiple disciplines. We have experimented with open-source AI sandboxes that allow us to download and interact with current models, and we have used emerging frameworks to prototype applications and provide non-technical users experience with the technology. These experiences allowed us to contribute significantly to LAS efforts such as SCADS, be active participants in larger enterprise discussions, and shape future work.
The trends we have focused on this year and the concepts we wish to build on for the future encompass applications of Retrieval Augmented Generation (RAG), agentic systems, and the use of multimodal models. After a discussion of these systems, we will conclude with lessons learned about evaluating the utility of models, systems, and workflows we wish to create.
Results
The primary insight in these methods is that we can shape the behavior of the LLM through the instructions and context provided in the prompt. Prior training of foundation models provides fluency and flexibility, but may not be enough to ensure task relevance and consistency. As the ‘context window’ or length of an allowable input increases with successive generations of models, we are provided an increasingly useful alternative to additional model training or fine tuning. The patterns that we demonstrate in more complex instructions, such as telling a model to think step by step, or as we provide additional background information that may not have been available to a model in training, and provide examples of appropriate responses, all help the model pick the next word that better aligns with our expectations.
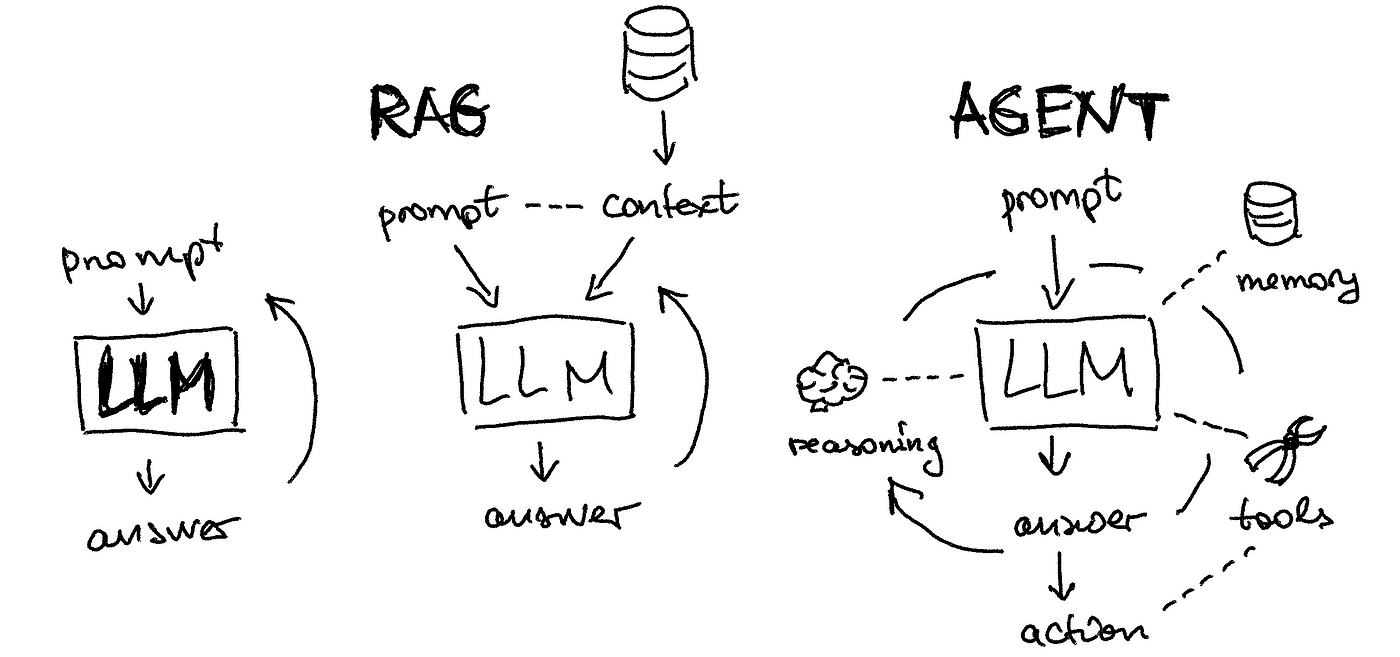
Image Source: https://towardsdatascience.com/intro-to-llm-agents-with-langchain-when-rag-is-not-enough-7d8c08145834
Retrieval Augmented Generation
Retrieval Augmented Generation (RAG) refers to the combination of a retrieval system that finds context relevant for answering a user’s question and a generation system that takes the original question and the context and creates a fluent answer. This system accomplishes three things that are important to effective use of LLMs for analytic functions.
- First, it grounds the output of the system to the provided context, preventing hallucinations and supplying provenance to reference documents.
- Second, the system ensures access to the most recent and most relevant information regardless of model training.
- Third, it allows us to separate and control access to more sensitive data and does not require us to use our most sensitive data for model training.
Simple RAG is the first approach to implementing RAG. The common practice is to identify a corpus of documents, split those documents into chunks that adequately represent key information but are small enough that multiple chunks fit into the generative model’s context window. Then the chunks are embedded into a high dimensional semantic space and represented as a vector. The vectors are indexed into a vector store or database that allows retrieval based on semantic similarity, or actually just a distance function that identifies nearest neighbors in the high dimensional space. The retrieval system embeds a user query, and finds a set number of nearest neighbors (usually 3 to 20) from the data store. The text for the nearest chunk embeddings and the original question are then fed to an LLM to answer the question.
Document chunking, embedding technique, indexing, and retrieval methodology give a few choices that can be tuned to improve the retrieval of relevant context, but we are seeing instances where multiple retrieval steps from multiple databases or indices are combined. Complex RAG combines semantic search, text search, knowledge graphs and even simple web searches. It also considers rephrasing the user’s original question or decomposing it into multiple questions. Various techniques can also be applied to ensure retrieved context is actually relevant to the question and that there is sufficient diversity in the retrieved results to answer complex questions. The figure below refers to an approach to RAG published by the AI company Anthropic, who show that adding context to document chunks, fusing both vector and keyword retrieval results, and then using a specially trained reranking model improves RAG results. We are finding the best RAG techniques are highly use case dependent, but we hope to gain intuition on what to use when.
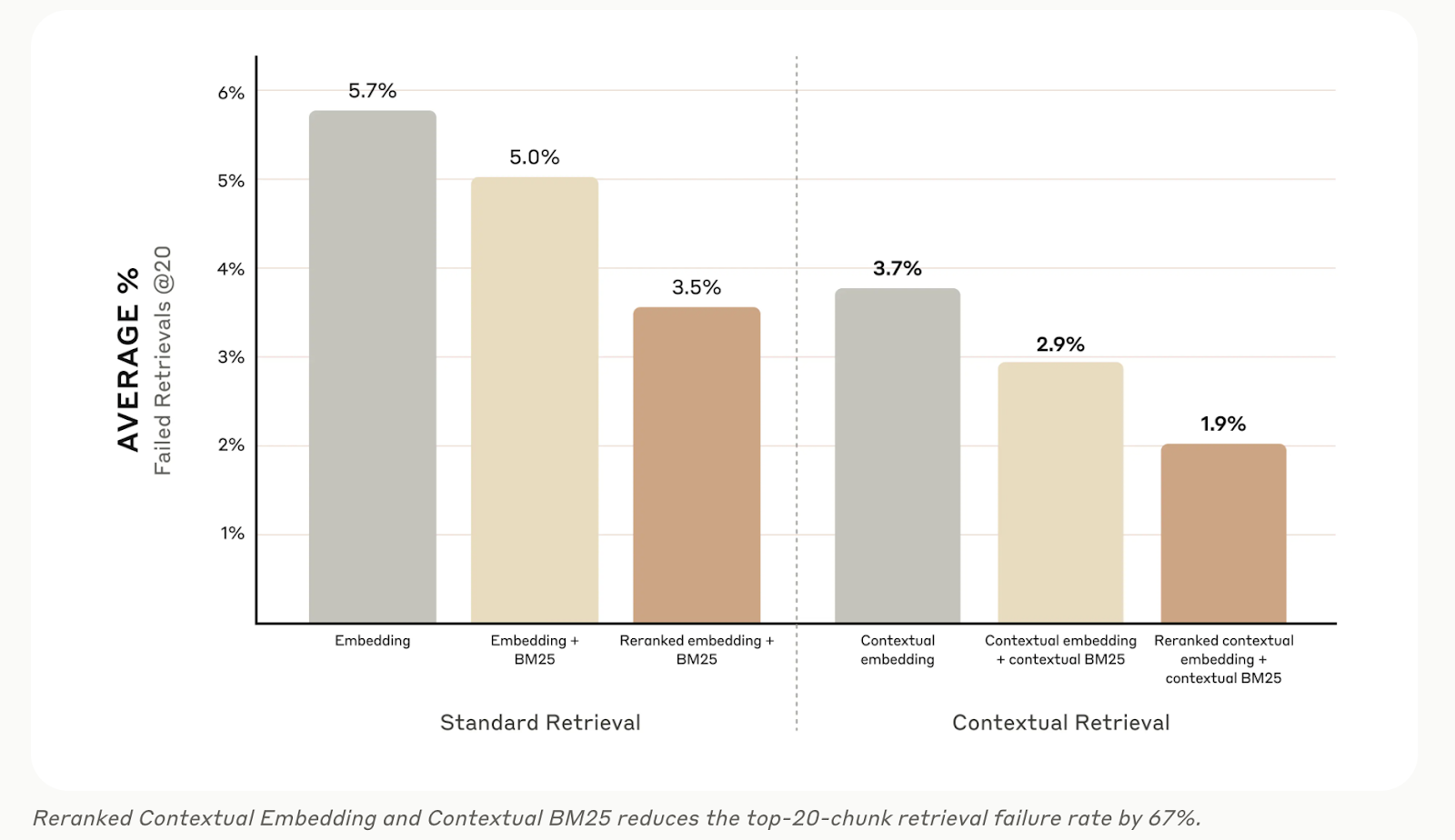
Image Source: https://www.anthropic.com/news/contextual-retrieval
Agentic Systems
Another way to improve RAG is to use an LLM to evaluate the answer produced by the system and if found insufficient, automatically task the system to generate a new answer that corrects any problems found in the first iteration. This is a basic example of an agentic system, where we introduce a critic agent to help improve AI generated outcomes.
An agentic system, as illustrated in Figure 1 above, combines memory, reasoning, tools, and an ability to act on user’s behalf with the language fluency of the LLM. According to Andrew Ng, a leading figure in AI research, common agent functions are reflection, tool use, planning, and multi-agent collaboration. Agentic systems are currently at the forefront of research in applying AI, and new frameworks and concepts are being developed constantly.
The critic agent above is an implementation of a reflection capability. Other reflection agents could also be used as guardrails to classify whether a user’s query complies with intended use of the AI system and the results generated meet fairness and safety criteria. These are good examples of where to start with developing agentic systems, as reflected in our own experiences experimenting with using LLMs to help evaluate and improve responses for question answering and video summarization pipelines.
The classic example of tool use in conjunction with an LLM is to not require an LLM to do arithmetic, but let it evaluate when arithmetic is necessary to answer a user’s question and then delegate the arithmetic function to a calculator application. Web search is another common example of tool use where an LLM may formulate a web query when it needs information to respond to a user’s prompt, and then incorporate the results of the query into its response.
Planning agents require reasoning to decompose complex problems into simpler tasks, delegate tasks to other tools or agents as appropriate, and coordinate the responses.
Finally, multi-agent collaboration provides a construct where different LLMs are given different roles and prompted to work together from different perspectives to produce an optimal solution. An example may be a project manager, a software engineer, and a tester working together to automatically generate a software application.
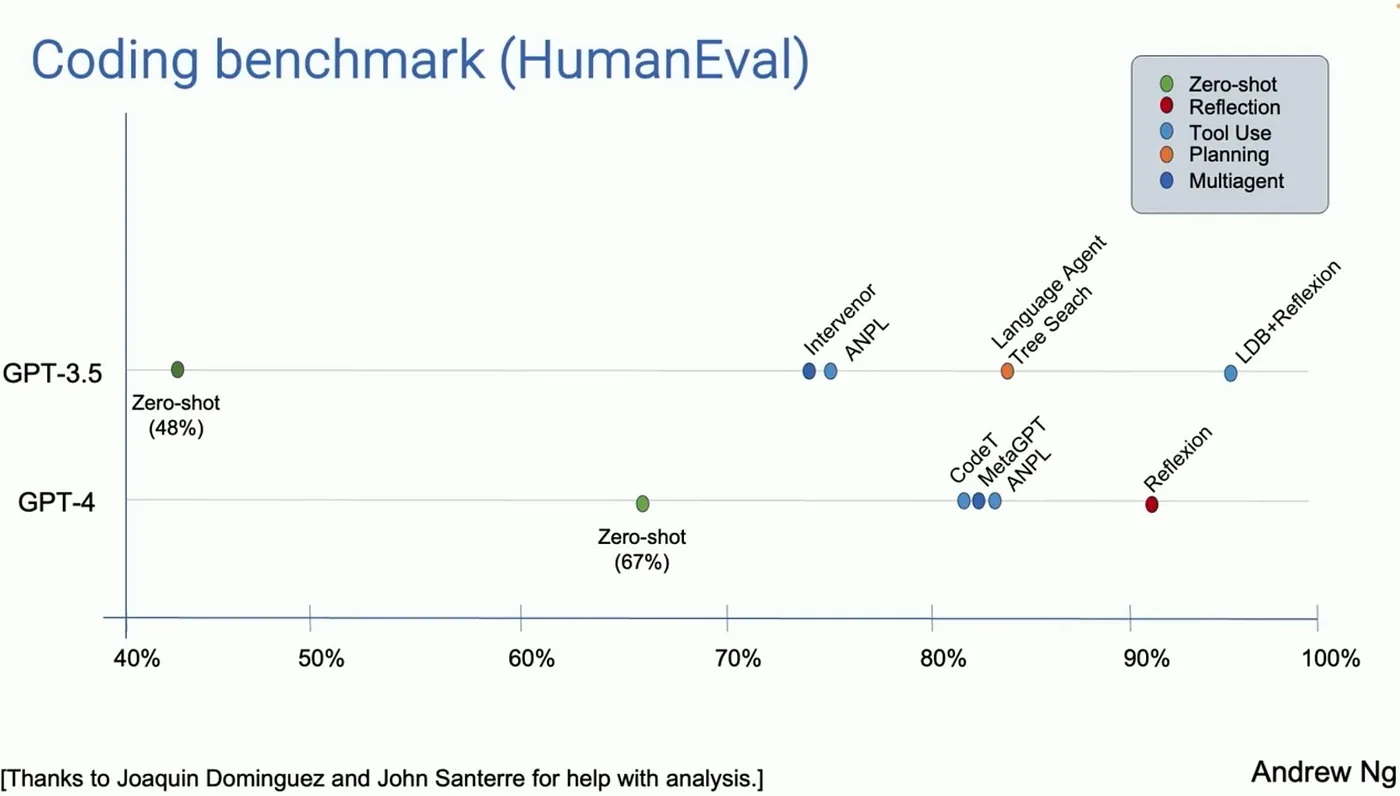
Figure 3 below shows how agentic principles can greatly improve baseline performance of LLMs. In this case, zero-shot refers to the baseline performance and reflection, tool use, planning, and multi-agent systems on top of the base model show remarkable performance gains for code generation.
For all their promise, agentic systems do not come without a price. Multiple additional inference steps increase system latency and financial burden if paying per token costs. Furthermore, granting autonomy to an AI agent is not without risk and can have unintended consequences.
Multimodal Models
It is a cliche to say that ‘a picture is worth a thousand words’, but audio and image information can directly inform the context from which model inferences are made, and LMMs can help users make sense more quickly of information dense and cognitively demanding constructs such as videos, technical illustrations, and computer network diagrams.
Large Multimodal Models such as vision-language models are providing the capability to turn any modality into a text description. These descriptions can improve retrieval as well as provide simple orientation, exploration, and gisting utility. We can create pipelines that aggregate various text representations into a common summarization or improved answer generation. But these models are also advancing rapidly in capability such that image and audio information can be directly represented in model inputs and outputs without the intermediate conversion to text. When we remove the text abstraction dependencies, the full value and nuances of these contexts are less restricted and may provide even greater enrichment value.
Our experiments with multi-modal models have helped inform related work for technical intelligence, video summarization, and network analysis.
Additional possible uses of multimodal models we have yet to explore concern not only the input to the models but the output. When a model can produce audio, image, or video output, it redefines the space for human-computer interaction as well as provides interesting alternatives for team interactions beyond the single user.
Evaluation
Image source: https://arxiv.org/pdf/2401.025
To this point we have discussed methods and concepts we are observing to control the behavior of LLMs in order to improve their utility for application to analytic tasks. But we still need to be able to judge how well our models or systems are doing at these tasks.
Evaluation is important for several reasons. First a user needs to know how much to trust the output of the LLM or the AI system in order to use the results appropriately. We need to understand where we might encounter errors and mitigate them in higher risk scenarios. Conversely, we also need to recognize where, despite potential for mistakes, LLMs and AI are very useful and we may not require perfection.
Also, we need to evaluate this technology in order to make business decisions. AI is expensive, and there will be tradeoffs concerning the number and size of models we can realistically support in our enterprise. We also want to understand performance and cost tradeoffs relative to older, existing technical solutions.
Evaluating LLMs exposes several difficulties, among which are prompt sensitivity, construct validity, and contamination, that make traditional model testing and benchmarking procedures problematic.
The output of an LLM is non-deterministic. This means that a response from an LLM will vary even repeating the same input. Also, as we have explored in other parts of this post, the output will change as prompts are augmented to provide more explicit instruction, more context, or more specific role descriptions. The best performance from one model may be elicited in a different manner than the best performance of another model, and there is not yet a good way to ensure we can systematically generate and compare best performances. This situation is categorized as prompt sensitivity, and makes instances where we wish to compare performance with exactly the same inputs and exactly the same expected outputs, as with common benchmarks, problematic.
Construct validity is another problem with testing and evaluating LLMs. Construct validity refers to whether a test we perform to evaluate a model actually assesses ability on the same tasks that a user will expect the model to accomplish. The generalizability of LLMs compounds the historic problem of whether test data accurately represents the population of data from which inferences are to be made. Because of the generalizability, we can expect that users will be using models for something different than the test. Therefore the construction of the test is likely to never be completely valid. AI benchmarks illustrate this dilemma in many ways, one of which is that it is common for these benchmarks to measure performance against multiple choice questions. Users to AI systems almost never ask multiple choice questions.
Finally the contamination problem occurs when test data is present in model training data. Because today’s LLMs are trained from almost everything on the internet, most benchmark sets are likely to have been seen previously by a model. Several researchers have shown that models have memorized test data and that accuracy results diminish considerably when new data is considered.
To mitigate these difficulties, many researchers are encouraging task-specific application evaluations in addition to common model benchmarks. They are exploring methods to evaluate performance for what the user is actually doing and evaluating as they are doing it.
Two methods that have emerged actually incorporate an LLM into the evaluation process. This may be problematic, and many researchers are skeptical of the validity of these approaches, but in a world of infinite task variability, and in a world where curating accurately labeled test data is tedious and expensive, it is likely better than nothing.
‘LLM as a judge’ is similar to the critic or reflection agent we discussed in agentic systems. Here an LLM evaluates how well a model is performing. In RAG systems, LLMs are being used to assess groundedness, faithfulness, and answer relevance. Groundedness refers to whether a question can be answered by the retrieved context. Faithfulness considers how well an answer represents that context. Finally, answer relevance determines if the result actually answers the user question.
LLMs can also be used to generate test data and the labels necessary to perform evaluations. Again, in RAG systems, techniques have been established and employed in common frameworks such as Langchain to create question and answer pairs from the actual document corpus. These generated pairs can then be used to test the system and compute precision and recall based metrics where ground truth is needed.
Future Work
In conclusion, we believe that LLMs will be useful to augment intelligence analysis workflows and assist analysts to perform multiple tasks. These tasks include translation, summarization, and question answering to aid in exploration and sensemaking. LLMs can also be useful for drafting and editing analytic products, and will demonstrate values as tutoring and training partners, critical thinking aids, and planning and orchestrating assistants.
We have observed several trends in the application of AI, experimented as extensively as possible, and attempted to share insights broadly.
We can maximize the utility of LLMs through implementation of constructs such as RAG and agentic systems, consider the richness of information from audio, video, and image sources, and understand risks and tradeoffs via effective evaluation.
The work we have done in 2024 has established a foundation in which we will pursue additional work in the future regarding building and evaluating RAG systems, exploring multimodal applications in intelligence analysis, and benchmarking and evaluating LLMs, AI systems, and AI enhanced workflows.
This material is based upon work done, in whole or in part, in coordination with the Department of Defense (DoD). Any opinions, findings, conclusions, or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the DoD and/or any agency or entity of the United States Government.
- Categories: