Enhancing Technical Document Triage: Large Vision Language Models for Image-Text Information Extraction
Contributors: Donita R., Edward S., Jacque J., John Nolan, Liz Richerson, Nicole F., Pauline M.

Technical intelligence analysts are responsible for the collection, evaluation, analysis, and interpretation of foreign scientific and technical information. This work often involves scouring massive volumes of documents for crucial details, which may be buried within a complex web of technical jargon, diagrams, multilingual text, and various formats. Moreover, analysts must not only draw well-supported conclusions but also cite precise sources and pinpoint specific evidence that forms the foundation of their assessments.
Through discussions with technical intelligence analysts about their workflows and obstacles, we identified several key challenges they face. Among these, a notable issue is that images embedded within technical content often carry essential information. In many cases, these images provide details that are either inadequately covered by the accompanying text or, in some instances, entirely lack corresponding explanations. This places an additional burden on analysts, who must synthesize insights from complex technical diagrams, multilingual text, and specialized terminology, all while working with incomplete or ambiguous information. Furthermore, current search and triage tools typically focus on a single modality, such as text or images alone, limiting their effectiveness given the diverse and intricate nature of the data analysts must navigate. This makes it critical to integrate insights across multiple modalities to ensure key details are neither overlooked nor misinterpreted.
By leveraging the interplay between different modalities, we aim to provide a more context-rich, integrated approach that enhances analytical outcomes. Specifically, we hypothesize that incorporating Large Vision Language Models (LVLMs) can streamline the image triage process, reduce analyst workload, and improve both the efficiency and accuracy of technical intelligence analysis. This project seeks to explore AI-assisted workflows, utilizing technologies like LVLMs, to achieve these objectives and optimize the overall triage process.
Technical Approach
To specifically address the challenge of image triage across a vast collection of technical documents, our technical approach focuses on developing a solution that leverages the contextual interaction between graphical and textual information. Based on discussions with analysts and a comprehensive review of existing triage workflows, it became evident that current tools – which typically isolate textual and graphical content – are insufficient for handling complex technical documents. These documents frequently integrate intricate diagrams, multilingual content, and domain-specific terminology, features that cannot be effectively captured by tools operating in single modalities. We believe that one of the keys to improving these analytic workflows lies in integrating insights across multiple modalities.
Our exploration centers on the use of LVLMs due to their unique capability to process both visual and textual data simultaneously. LVLMs offer significant advantages in this context by enabling the extraction of information across both modalities in tandem, ensuring that contextual clues within one modality are interpreted in relation to the other. This capability is particularly beneficial for contextual summarization of images as embedded within technical documents, generating accurate and explainable summaries. Additionally, LVLMs can be leveraged to identify contextually-linked textual information associated with images. This linkage provides an attributable and citable reference for technical intelligence analysts to utilize when producing analytic products.
Crucially, we aim to leverage LVLMs to enhance search precision, surface crucial details more effectively, and reduce the cognitive burden on analysts tasked with triaging and synthesizing large volumes of technical data. By utilizing contextualized image-text pairs, LVLM-enabled semantic search creates opportunities to disambiguate information that may be unclear when analyzed through just one modality. This capability is further enhanced by contextually-relevant summarizations that can be used to re-rank candidate query results based on their relevance to the search criteria.
A practical consideration guiding our approach is the acknowledgment that applying LVLMs at scale across expansive data volumes poses significant challenges, both in computational resources and efficiency. To address this, our workflow integrates pre-filtering mechanisms such as metadata filtering, keyword-based search, and existing semantic image search methods – specifically CLIP – to provide coarse filtering functions prior to invoking LVLMs for true multimodal analysis. This layered approach ensures that the application of LVLMs is computationally feasible while still providing the depth of insight required for complex technical triage tasks.
Finally, we anticipate leveraging natural language in converged search processes to guide and refine multimodal triage workflows. To this end, we are exploring the use of Large Language Models (LLMs) to enhance CLIP and semantic search query generation, thereby improving the initial coarse filtering and re-ranking of results. This integrated framework of traditional filtering, CLIP-based semantic search, and LVLMs seeks to strike a balance between scalability and analytical precision, ultimately providing technical intelligence analysts with more efficient and insightful tools for image triage across complex technical documents.
Core Functions
Document Retrieval and Content Extraction
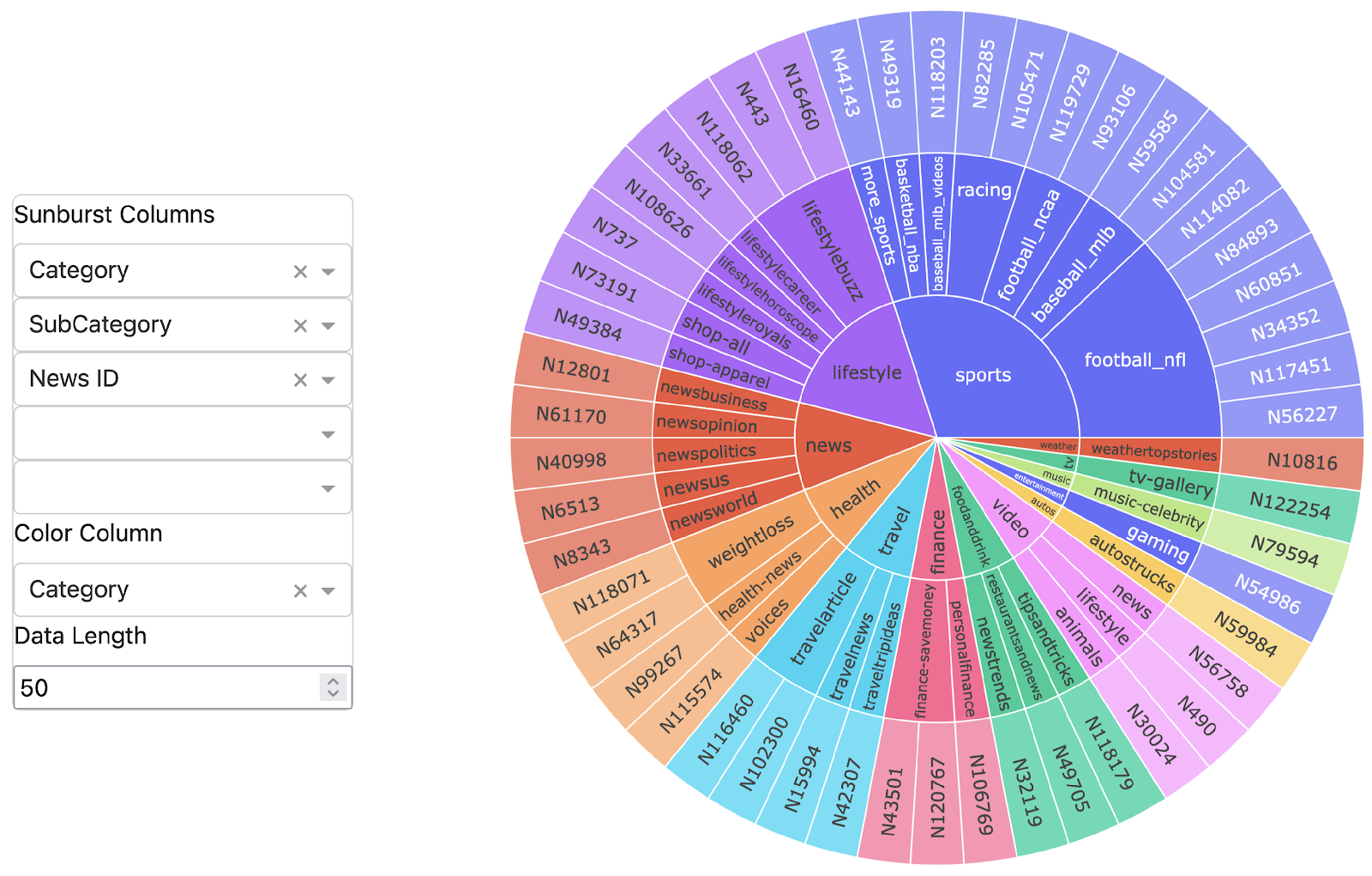
Analysts initiate document ingestion by defining specific metadata filters and keyword search criteria allowing retrieval of a subset of potentially relevant documents directly from arXiv. Metadata filtering helps narrow down large datasets without analyzing the content, while keyword search locates exact or near-exact text matches for specific terms or phrases. Once selected, open-source libraries automatically extract textual and visual content from the documents. This extracted information is stored in a content repository for future reference, enabling the integration of both text and images for deeper analysis in subsequent stages.
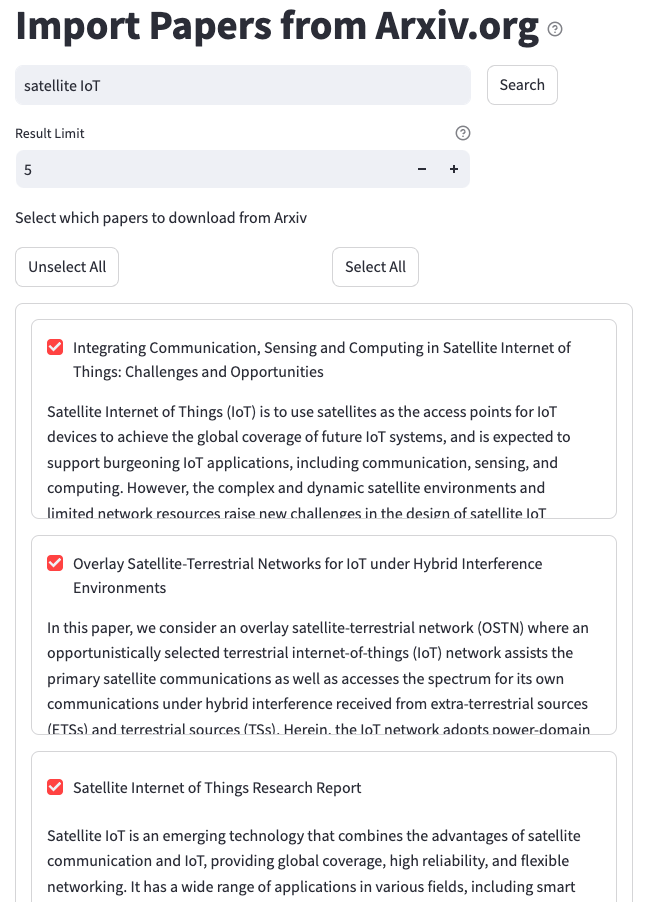
CLIP Search as a Coarse Filter
CLIP performs semantic search by quickly identifying image candidates in the content repository that align with the meaning and intent of a user query. Although CLIP lacks the ability to fully contextualize images within a broader document, it provides an efficient coarse filtering mechanism by surfacing the most relevant images for subsequent analysis. In our workflow, CLIP enables a first-pass filter that reduces data volume, allowing more computationally intensive tools like LVLMs to focus on refining results through deeper multimodal integration.
Contextual Image Summarization and Enrichment
LVLMs enhance image processing by providing contextual enrichment based on related textual data. For each image processed, the model generates contextual summaries derived from relevant sections of the document. These summaries link the visual content to text, helping analysts better understand the data being presented. Often, technical documents contain images that are complex, such as diagrams or graphs, and require supporting text to fully comprehend their significance. Contextual enrichment ensures that the information is not presented in isolation, making it easier for analysts to interpret images effectively and understand their relevance within the broader document.

Contextual Summary Search
Performing semantic search against the LVLM-generated contextual image summaries enhances the relevance and accuracy of search results by focusing on the combined meaning of text and images. These summaries are ranked based on their semantic similarity to the analyst’s query ensuring that the most contextually relevant information is surfaced during the content triage process. Images and contextual summaries are returned to the user and can be further investigated to support technical intelligence analysis.

Information Extraction for Explainability
Analysts can review selected images within the original technical document along with the contextually linked source text for each image. This facilitates more thorough verification of information relevance and accuracy as well as enables analysts to efficiently cite specific data required for intelligence reporting. The combination of image, summarized content, and citation of source text provides analysts with an explainable output, where both visual and textual components are tied together meaningfully.
Query Optimization with LLMs
Analysts are encouraged to write long-form natural language queries to describe the content they are seeking. LLMs are utilized to optimize queries used for both coarse filtering with CLIP and for semantic search of contextual summaries by transforming natural language input from analysts into semantically-expanded rich queries. LLMs rephrase queries to capture the analyst’s intent while avoiding pitfalls such as the use of negatives, which can hinder some similarity-based models, or exceeding the search token limits.
Workflow
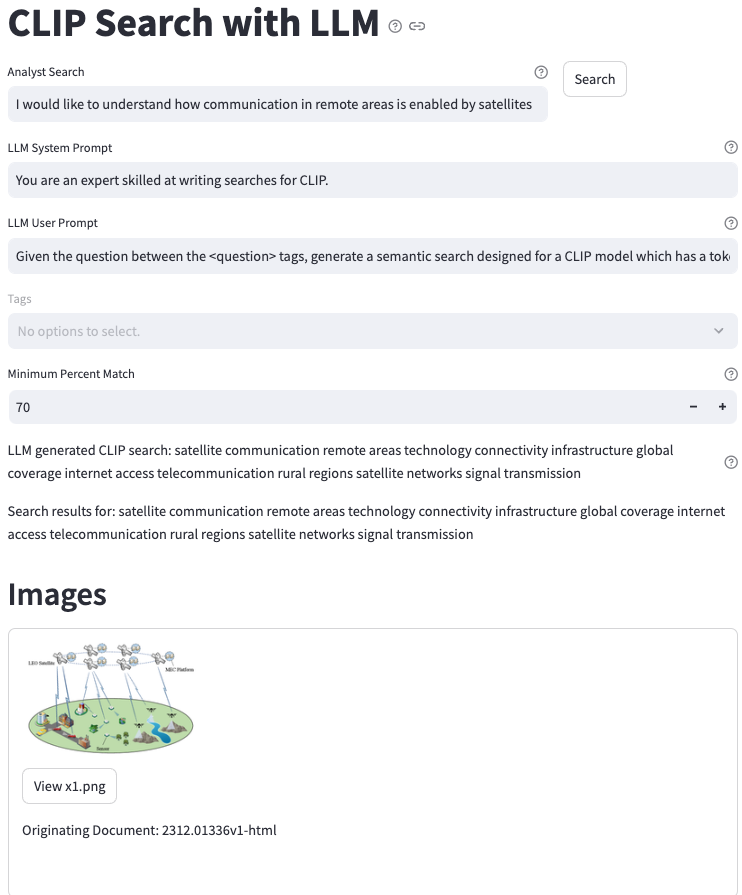
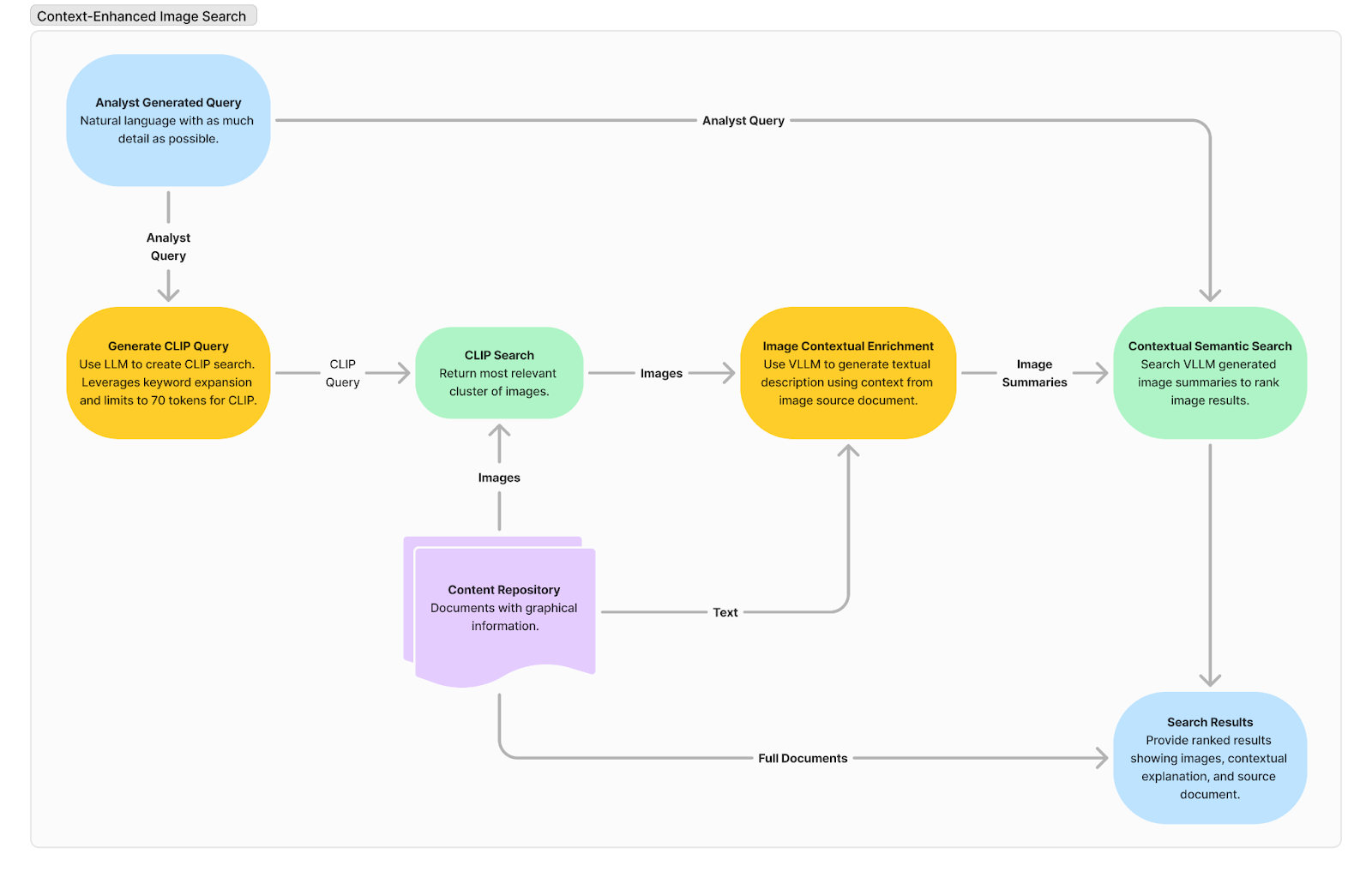
While we have already developed the core functions described above in a prototype tool, we continue to refine and integrate them into a complete workflow (figure 6). This process begins with an analyst generating a detailed natural language query, which is optimized by an LLM to expand keywords and fit within CLIP’s token limits. The resulting CLIP query is used for an initial semantic search that retrieves a relevant cluster of images from a content repository. These images are then processed through LVLMs, which generate a multimodal contextual summary for each image based on its associated document. This enriched information feeds into a contextual semantic search which ranks the images by their semantic similarity to the original query, taking into account both visual and textual relevance. The final output presents ranked results, including images, contextual summaries, and source references, ensuring analysts have access to explainable, comprehensive data. We intend for the workflow to enhance search precision, reduce cognitive load, and streamline the image triage process – improving efficiency and accuracy for technical intelligence analysts.
Findings
Our exploration into AI-assisted technical intelligence workflows highlights several promising findings despite the evolving nature of these insights. First, effective text-image alignment enabled by LVLMs has shown significant potential for improving analysts’ ability to quickly locate and understand crucial content embedded in complex technical documents. Typically, images and diagrams in these materials contain vital information that is often not fully explained or covered by the accompanying text. By integrating LVLMs, we observed an enhanced ability to identify relevant sections of text that align with corresponding images, reducing the time required for analysts to triage and comprehend these complex representations.
Second, improved understanding of technical material has emerged as a notable benefit of LVLM-assisted workflows, particularly in documents where images play a pivotal role in conveying information. Our prototype tool generated LVLM-driven contextual summaries, linking the textual content to visual representations, which appeared to improve overall interpretation of technical content. This contextual enrichment allows analysts to derive insights faster and with greater confidence, potentially addressing one of the most time-consuming hurdles in collecting technical intelligence: synthesizing critical information from fragmented or incomplete data sources.
Finally, our initial findings suggest that enhanced contextual semantic search enabled by LVLMs has the potential to improve the accuracy and relevance of search results. By enriching images with contextual information from associated document text, these models seem to not only disambiguate complex materials but also facilitate more precise identification of critical information. When combined with the CLIP-based image searches, LVLMs contribute toward a multifaceted search process that enhances retrieval and relevance ranking, likely supporting more insightful and efficient technical intelligence analysis.
Our investigation has underscored the potential of LVLMs to significantly streamline technical intelligence workflows. By offering explainable, image-based information and improving multimodal search precision, LVLMs contribute to faster and more accurate insight generation. Their ability to enhance text-image alignment, enrich contextual understanding, and increase the relevance of search results suggests they hold considerable promise for supporting analysts in managing the complexities of technical documents. However, continued refinement and testing are needed to ensure these AI-driven techniques can be effectively integrated into real-world analysis environments.
This material is based upon work done, in whole or in part, in coordination with the Department of Defense (DoD). Any opinions, findings, conclusions, or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the DoD and/or any agency or entity of the United States Government.
- Categories: