ECHOLAB: Leveraging LLMs to Boost Speech-to-Text Accuracy in Challenging Audio Environments
Sean L., Patti K., Ed S., Kanv Khare

Speech-to-text (STT) transcriptions are crucial to audio analysis, forming a foundation for retrieval, prioritization, and sensemaking activities within the analyst workflow. The accuracy of STT output is essential; without it, analysts may struggle to access relevant information efficiently or derive meaningful insights from audio data. Our research demonstrates that under specific conditions, Large Language Models (LLMs) can enhance the quality of STT transcriptions across diverse analytic tasks.
A key finding of this work demonstrates that LLMs can utilize supplementary information to enhance STT quality. In particular, when provided ground truth translations of the audio in a separate language (a use-case particularly important for truthmarking STT) the LLM can remove more than half of the errors present in the STT. This finding opens the door to many more possibilities regarding what types of supplementary information an LLM may be able to utilize, which will be a focus of Echolab going forward. An additional finding is that classic machine learning models can be used for selection purposes, deciding which STT utterances may or may not be enhanced by the LLM. This increases overall system efficacy, optimizing resource allocation and ensuring that improvement efforts are focused where they will have the highest impact. Together, these findings indicate significant potential for improvements to analyst workflows, particularly for truthmarking STT, but also for information retrieval and sensemaking tasks.
Methods
To explore how LLMs can boost STT accuracy, we developed multiple approaches for integrating these models into analyst workflows. While our 2024 work did not focus on every approach, defining a comprehensive set of techniques helps frame our findings and showcase their potential impact.
We identified five distinct approaches, each defined by the type of input provided to the LLM:
- Blind improvement: STT for single utterance
- Blind-plus improvement: An STT utterance for correction plus any additional STT utterances available from the same audio content.
- Context-enriched improvement: An STT utterance for correction with additional STT utterances and any available external contextual knowledge (ex. named entities, domain-specific knowledge graphs, historic reports, etc.)
- Translation-aided improvement: An STT utterance with a human-created translation or gist of that specific utterance.
- Hybrid improvement: An STT utterance along with a human-created translation or gist, additional STT utterances, and external contextual knowledge.
Regardless of the approach, we propose three methods for determining how much data to provide to the LLM.
- Complete: Always attempt correction of an STT utterance.
- Cloze: Select STT utterances for correction based on individual word confidence thresholds.
- Model: Select STT utterances for correction via a supervised ML model trained using confidence levels and semantic embeddings (when available).
This framework allows us to evaluate various combinations, giving us insights into which approaches and data selection methods offer the greatest improvements in STT accuracy for different analytic use cases. To test these methods, we leveraged the Tatoeba (German and Spanish) and Multilingual TEDX (Spanish) datasets which included foreign language audio, foreign language STT output, human-generated foreign-language transcriptions, and human-generated English translations. We assessed STT improvement using several metrics including Levenshtein distance, WER, and semantic similarity, and applied these metrics at an utterance level (small portions of speech audio, sometimes called “segments” or “chunks”). We also experimented to some extent with prompt engineering, and found in general that concise, directive, and iterative instructions worked best, although prompt effectiveness did vary depending on the LLM used.
Use Case 1: Truthmarking Task
Truthmarking STT aids audio analysis in the long-term by providing human-verified data in the specific context needed, which can then be used to train and fine-tune STT models to improve their future output. However, analysts are often overwhelmed by the sheer volume of data they need to process and usually do not spend much, if any, time on this task since it is not immediately relevant to their analysis. Crucially, truthmarking can be performed in parallel with or after evaluation of the foreign-language audio. This means the analyst’s English-language translation or gist of the foreign language audio can be used as input for the LLM correcting the STT.
Based on Levenshtein distance, our translation-aided process improved most utterances. Using a selection model significantly improved the precision of the corrected utterances.
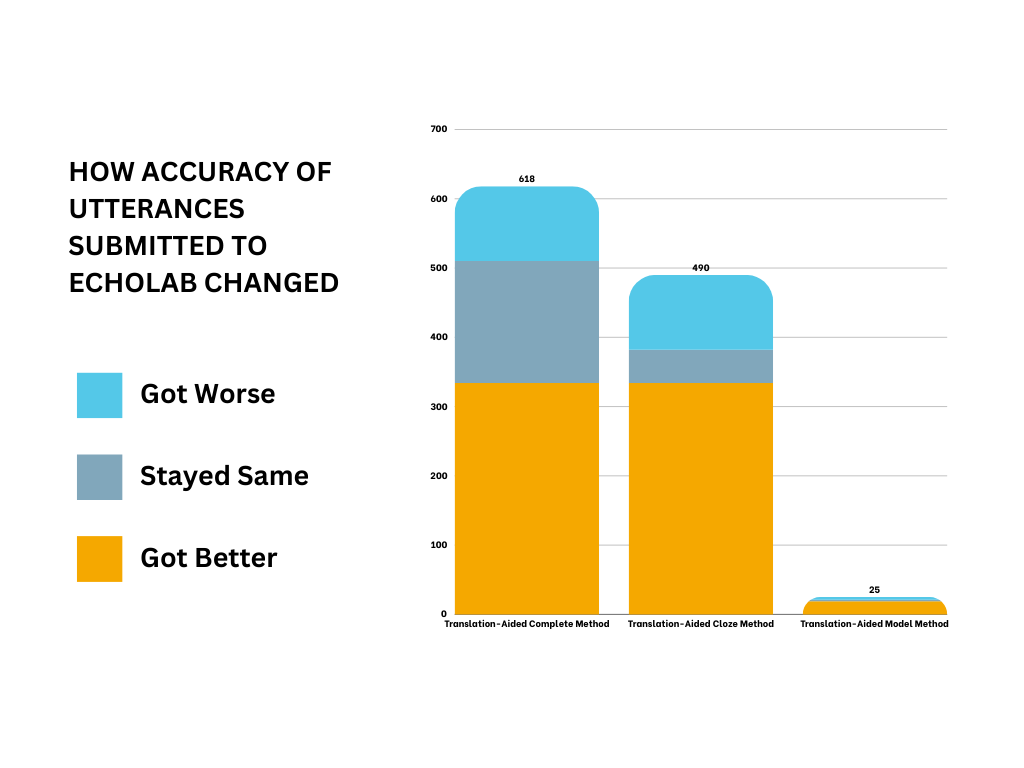
By incorporating human-generated translations into our LLM prompt, we observed an improvement in STT regardless if it is measured by Levenshtein distance (character-level changes), WER, or semantic similarity to the ground-truth utterance. Improvement was observed across different methods, whether all utterances were processed (complete method), selected based on word confidence levels (cloze method), or chosen by a selection model (model method). For the truthmarking task, we prefer the Levenshtein distance metric because it effectively reflects the human effort needed—measured in keystrokes—to truthmark a utterance.

Use Case 2: Triage and Sensemaking Tasks
While truthmarking focuses on enabling improvement of STT models to improve future analysis, the sensemaking phase is where analysts directly engage with the transcriptions to understand and prioritize audio data for further analysis. In this phase, analysts often rely on STT for tasks like keyword or semantic search to retrieve relevant data or simply to help comprehend the content. Inaccurate STT can significantly hinder these efforts, making it essential to explore ways to improve transcription usability, even without immediate access to human translations.
Although a human translation is not available at the point in the workflow when analysts are engaged in sensemaking, we hypothesize that LLMs can still improve STT quality. Our results indicate that, while the hybrid method currently lags slightly behind the translation-aided approach (the primary focus of our 2024 work), it still showed improvement when compared with our initial hybrid experiments. With continued refinement of our prompts and models, we anticipate further improvements in both the context-enhanced and hybrid approaches, enabling improved STT accuracy in this critical phase of the analyst workflow.
Implications, Future Research, & Transition
Intelligence analysts often operate in a challenging data environment where the quality of STT output can be compromised, diminishing the usefulness of transcriptions for analysis. However, our findings highlight the potential of LLMs to significantly improve STT accuracy, particularly when human-generated translations are incorporated to enhance the STT output. By leveraging LLMs in the translation-aided approach, we can effectively correct STT transcriptions, streamlining the truthmarking process within this complex environment. This, in turn, will generate more valuable, domain-specific training data, resulting in improved STT that enables analysts to navigate complex audio data more efficiently and extract meaningful insights.
While our results indicate that these methods will produce better STT results in the translation-aided case generally, we’re also seeing great potential to use selection models to hone in on those utterances which will be most effectively corrected, and not waste time and compute on others. With appropriately trained selection models in place, resource managers can essentially be offered the choice of how much LLM resources they’d like to put toward improving STT results, and it will be executed in an optimal manner.
Moving forward there are many opportunities for building on this success. First, several key areas of our current work require refinement, optimization, and further research. Prompt engineering and building larger, more varied, datasets for development, testing and evaluation are chief among them. Next, we plan to further explore the five approaches we have identified. Identifying and collecting new forms of supplementary information and creating methods of incorporating them into our prompts will be the critical step here. This will allow us to explore and assess the broader applicability of our methods for different use cases and data environments. Given the unique operational data and insights that exist in classified environments, this research may be particular applicable.
Another important focus will be integrating workflows that prioritize gisting over verbatim translation. Since analysts often deal with large volumes of foreign language audio, summarizing key points rather than providing word-for-word translations is a common practice. We will test how gists can support LLM-enhanced STT workflows, ensuring that our approach is relevant to the needs of analysts working with high-volume, time-sensitive data. If successful, this will validate the effectiveness of LLM-enhanced STT within the currently dominant analytic tradecraft. By exploring these research directions, we aim to continue improving the accuracy and utility of LLM-assisted STT, making it a more effective tool for analysts across a range of settings and tasks.
Finally, by building on the contributions of a team of North Carolina State University students, who developed a prototype user interface (UI) for this project in their 2023 capstone research course, and the insights from this year’s work, we aim to inspire the development of corporate transcription and computer-assisted translation tools to enhance analytical capabilities.
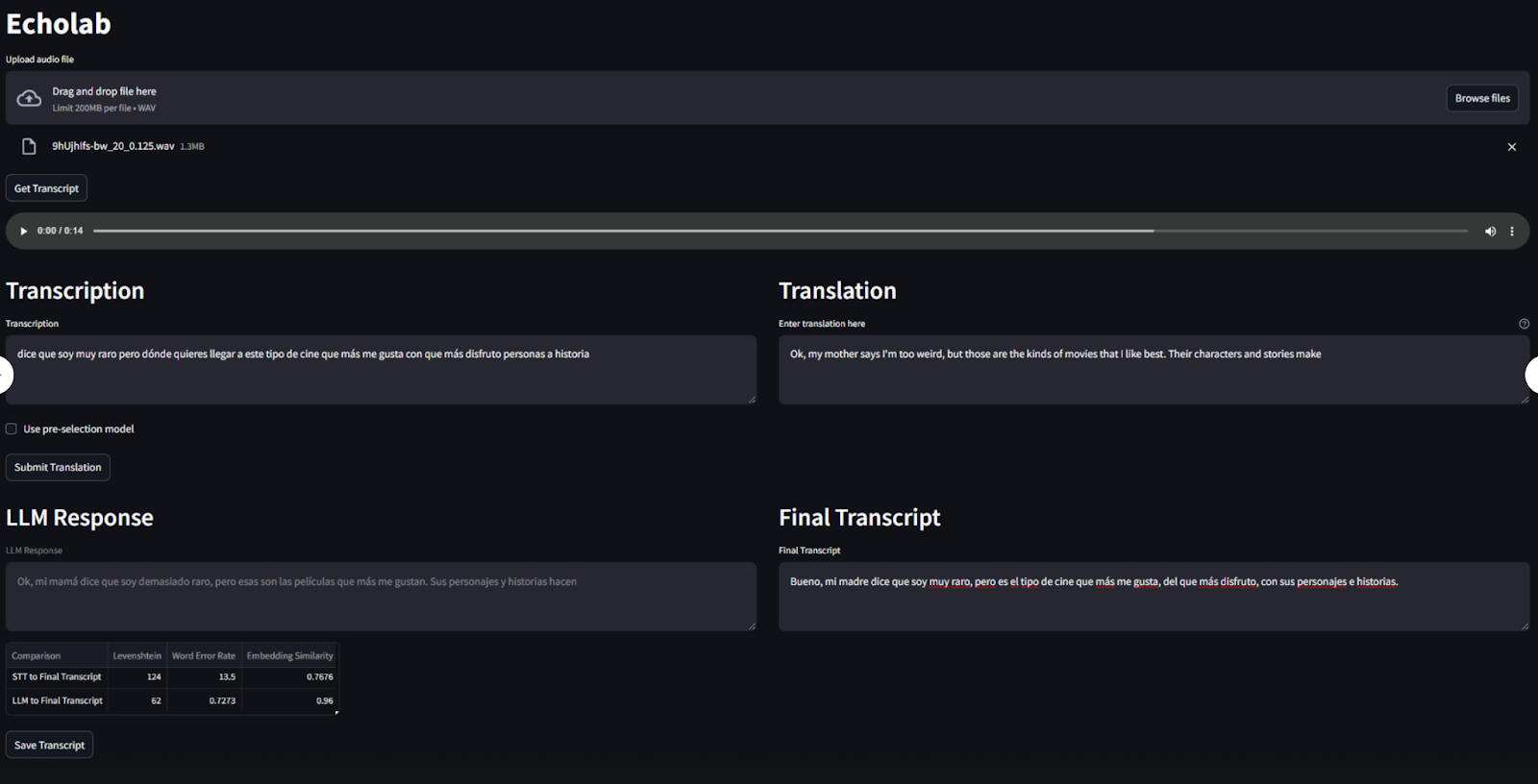
We envision a future where the methods we’ve explored are not implemented only in research settings but are also incorporated into mainstream analytic tools. By leveraging the translation-aided approach to enable LLM-assisted STT correction, for example, we will rely less on outsourcing truthmarking tasks to people hired specifically for this purpose, while still ensuring high-quality, domain-specific training data. This approach will support the scalable generation of truthmarked data, ultimately enhancing the performance of STT systems without burdening analysts with excessive manual work.
This material is based upon work done, in whole or in part, in coordination with the Department of Defense (DoD). Any opinions, findings, conclusions, or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the DoD and/or any agency or entity of the United States Government.
- Categories: