Automated Workflows to Triage Technical Intelligence
Kirk Swilley, Logan Perry, Patrick D., Kristina Chong, Agata Bogacki (SAS Institute)

Introduction
In today’s rapidly evolving technological landscape, analysts face the daunting task of sifting through large volumes of unstructured data to identify critical trends and insights. Our team recently undertook a project, in collaboration with LAS, to develop a semi-automated, repeatable analytic workflow. This workflow is designed to assist analysts in efficiently triaging and analyzing technical information, such as patent applications and research papers, by leveraging advanced machine learning (ML) techniques and interactive visualizations.
Data Sources
- Research Papers / arXiv
- arXiv is a free distribution service and an open-access archive for nearly 2.4 million scholarly articles in the fields of physics, mathematics, computer science, quantitative biology, quantitative finance, statistics, electrical engineering and systems science, and economics. Materials on this site are not peer-reviewed by arXiv.
- https://info.arxiv.org/help/bulk_data/index.html
- Metadata available on Kaggle (Title, Abstract, authors, date, ID, etc) for over 2 million articles – manual download (https://www.kaggle.com/datasets/Cornell-University/arxiv)
- Patent Documents / USPTO
- The U.S. Patent and Trademark Office (USPTO) is the agency responsible for granting U.S. patents and registering trademarks. The USPTO provides public access to PDFs of patents. These documents have unstructured descriptions of the intellectual property, along with formulas, diagrams, and other non-textual elements.
- https://ppubs.uspto.gov/pubwebapp/static/pages/landing.html
- https://developer.uspto.gov/ibd-api/swagger-ui/index.html#/bulkdata/searchPublicationData (depreciated API access to abstract and full USPTO publication documents)
Semi-Automated Content Triaging Workflow
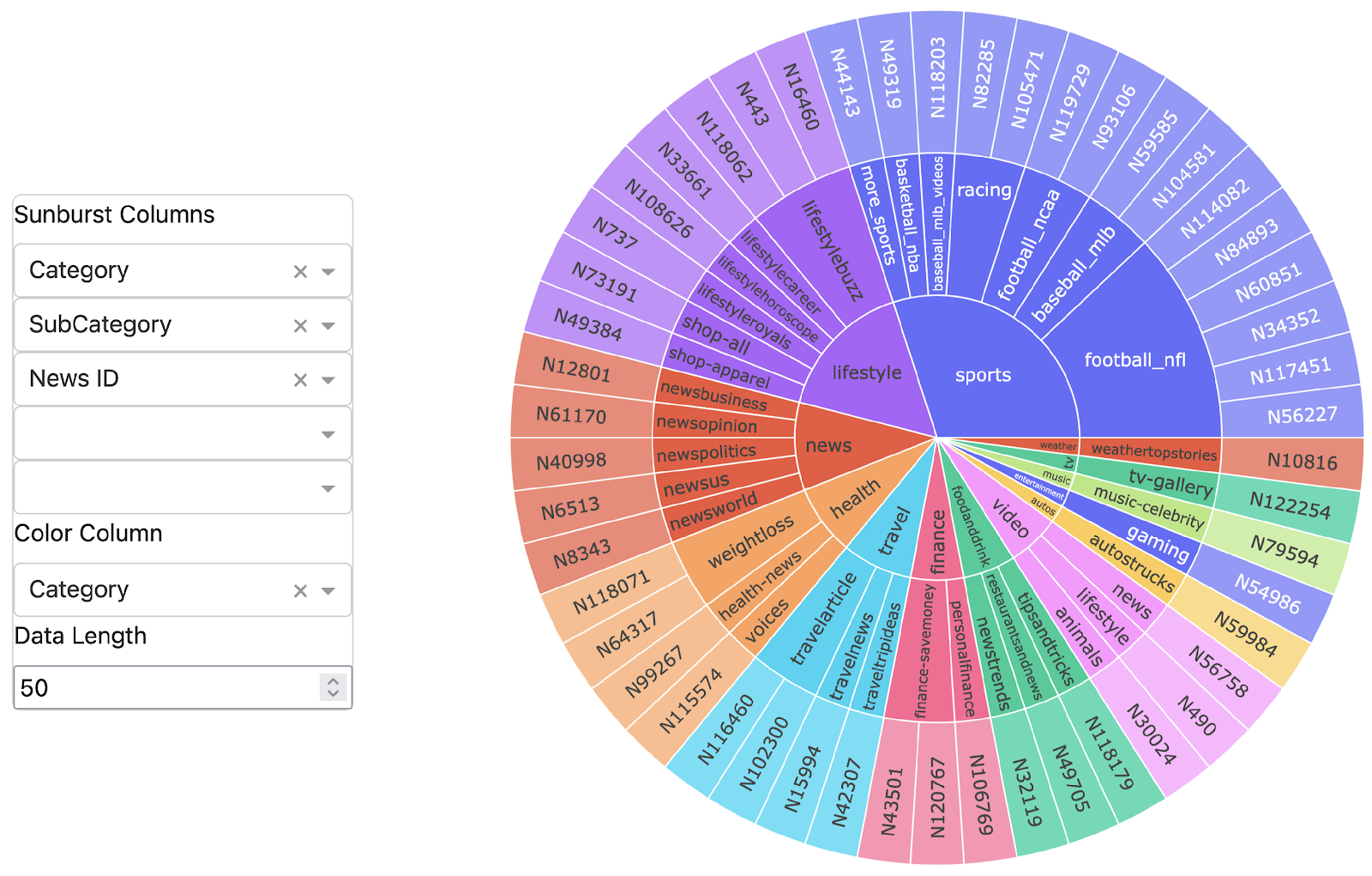
Reducing the number of documents in a tiered approach allows for flexibility in refining data, ultimately shortening the time between identifying data and generating insights. Our team partitioned the triaging workflow into three sections, visualized in Figure 1:
- Define Data, starts with all documents available (millions) and utilizes APIs and data connections to filter for relevant topics/date ranges/key words;
- Refine Data, where abstract-level information (thousands) from the subset identified previously is processed into a Data Insights Dashboard in SAS Visual Analytics (VA) utilizing automated SAS Natural Language Processing (NLP) methods to allow a user to quickly sift through thousands of documents and identify relevant source documents or groups of documents to triage into the final processing cohort;
- Generate Insights, leverages the previously identified PDF documents (dozens) and processes them into a structured data format. This enables a more computationally intensive analysis of the textual and non-textual elements using large language models (LLMs). This approach provides analysts with summaries and deeper insights into the triaged cohort of documents, allowing for easier consumption and action against complex technical information.
The Project: Creating an Offline LLM Application for Analysts
At the core of this project, we set up an offline LLM application, hosted on an Azure virtual machine (VM) equipped with GPUs. Using Flask and Python, we developed the application around the Mistral 7b quantized model, allowing it to handle document summarization, query tasks, and interactive exploration of documents. This offline setup was essential to ensure performance and data security while providing powerful LLM capabilities to triage documents and provide analysts with useful information contained in the source documents.
Our application features several key endpoints:
- Batch Summarization: Analysts submit multiple documents to generate summaries for each document in batch.
- Standard Queries: Analysts submit predefined sets of queries against any document collection, allowing for the generation of answers to common or preconceived questions.
- Single Query Submission: Analysts submit individual queries for dynamic, ad-hoc interrogation of the source documents.
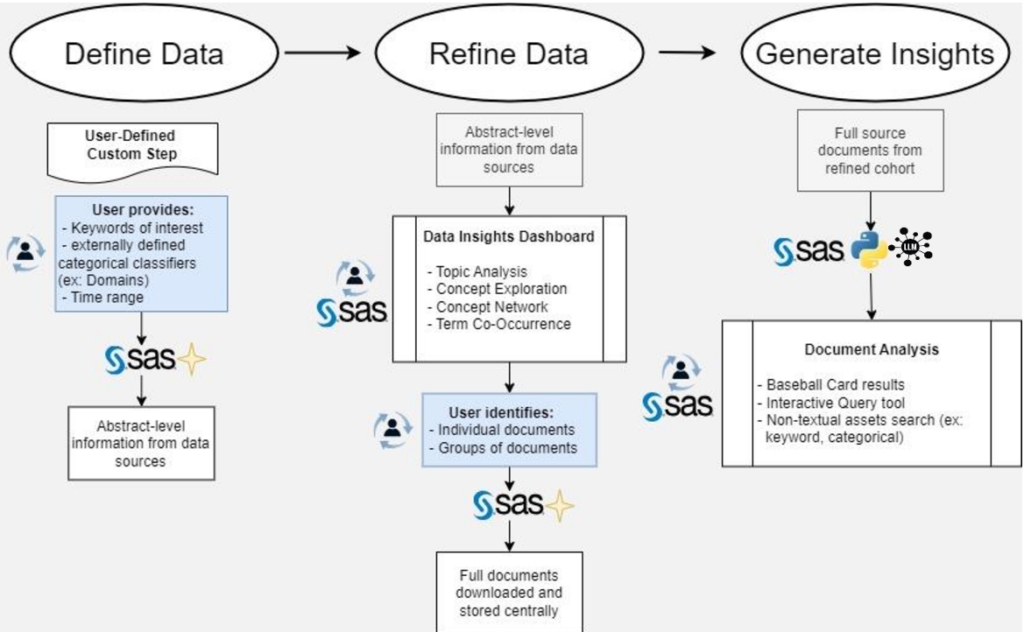
Additionally, we implemented a Retrieval-Augmented Generation (RAG) approach, enabling document retrieval and information generation in an integrated process. Through this, we created a “baseball card” view for each document (Figure 2.), where document summaries and answers to batch queries are available at a glance and can be quickly filtered/searched based on analyst criteria.
Processing Patent Documents: From PDFs to Structured Data
One of the key challenges we faced during this project was processing the U.S. Patent and Trademark Office (USPTO) documents, which were originally in non-searchable PDF format. These PDFs often contained multi-column text, complex formatting, with embedded images, making it difficult to extract information uniformly in a usable format. To address this, we employed a combination of image processing and optical character recognition (OCR) techniques to convert the PDFs into structured text data and isolate the non-textual assets of interest.
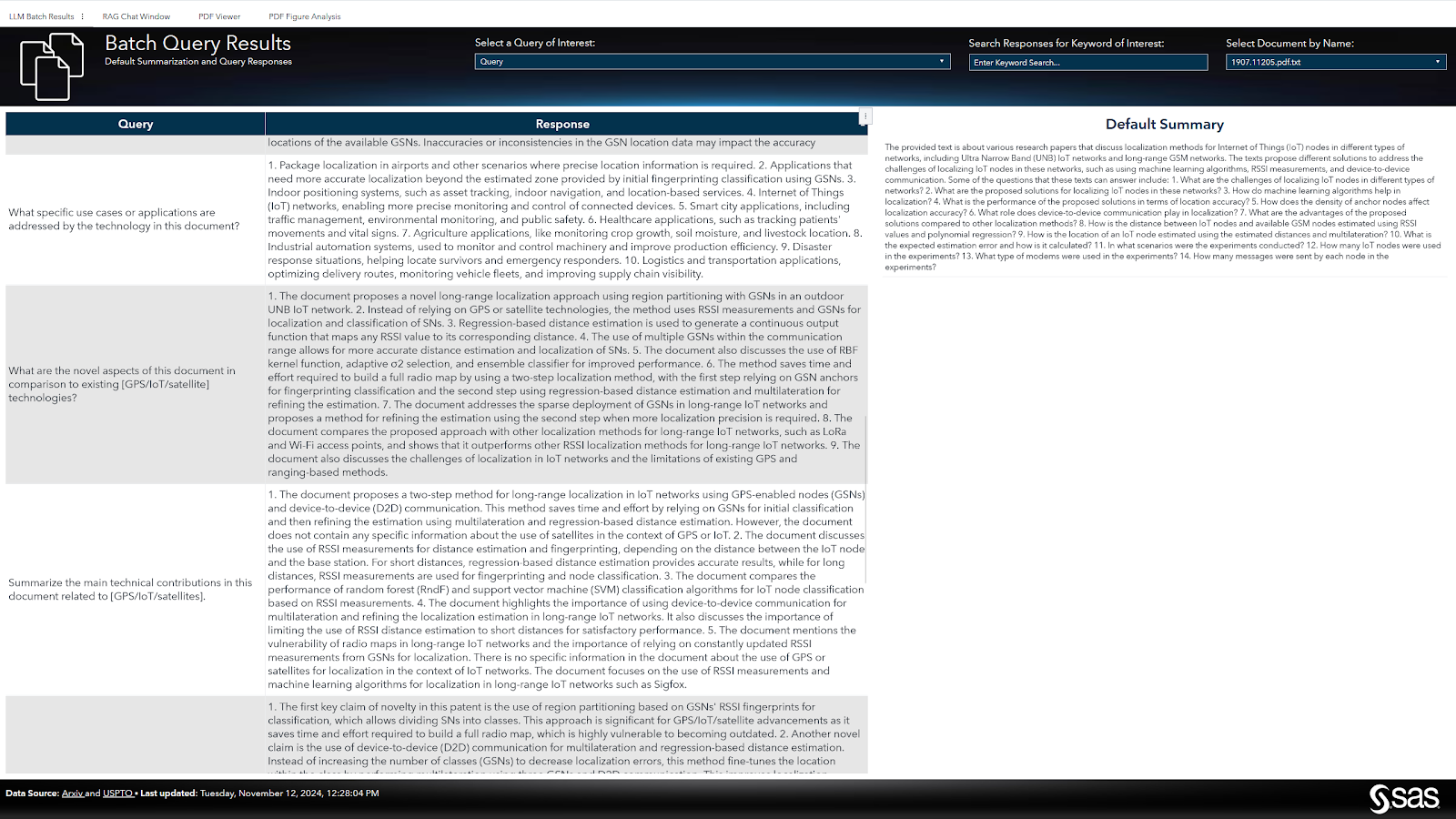
- Converting Multi-Column PDFs to Text – Since the patent documents followed a multi-column layout, extracting the text was more complex than standard single-column PDFs. We had to carefully manage the text extraction process to preserve the correct reading order and avoid jumbled outputs. Using image processing tools, we broke the pages into separate regions, isolating the columns and processing each one individually. Once the text was extracted, we reassembled the document in the correct sequence for further analysis, shown in Figure 3.

- Isolating Images for Analysis- In addition to text, many patent documents contain diagrams, technical drawings, and other visuals that provide crucial technical information. To incorporate these visuals into our analysis, we developed a Python-based process to identify and extract images from the PDFs automatically.
- Initial Page Analysis: Our process starts by checking each page to determine if it contains primarily text or images. We assumed that text pages in the patent documents consistently used a multi-column format, typically separated by blank space between columns. By scanning for white space between columns, the code identifies text-heavy pages for text extraction.
- Identifying Image-Only Pages: If a page does not match the multi-column text layout, it is flagged as an image-only page. These pages are extracted for separate image analysis, allowing us to focus on the visual content without interference from unrelated text.
- Handling Pages with Both Text and Images: During testing, we found some pages contained both images and text, which required adjustments. For these mixed-content pages, which often consisted of figures in-line with the columns of text, we ran the whole page through the both the OCR and image analysis processes.
- Leveraging ChatGPT’s Multimodal LLM – Once the images were isolated, we leveraged ChatGPT’s multimodal LLM to process and analyze these visuals. By passing the images through the model, we were able to generate descriptions and insights that complemented the text analysis, offering a more comprehensive view of each patent. This multimodal approach added another layer of depth to our workflow, enabling us to extract information from both text and images, which was especially valuable for technical patents where visual content plays a crucial role. An example processing of isolating non-textual asset and the resulting Multimodal LLM output is depicted in Figure 4, below.
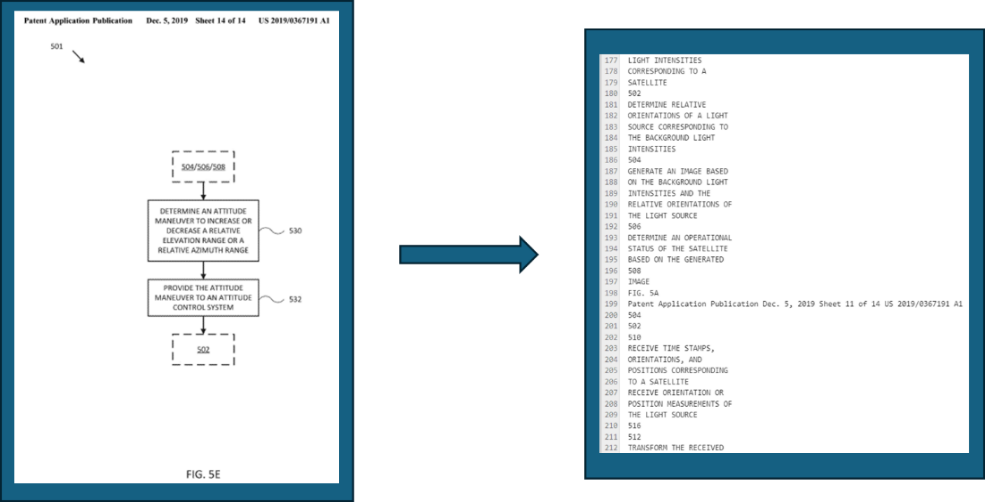
Through this process, we were able to convert a complex mix of textual and visual data into structured outputs, allowing the analysts to gain insights from all aspects of the patent documents.
GUI-Based Interaction: Integrating the Offline LLM with SAS
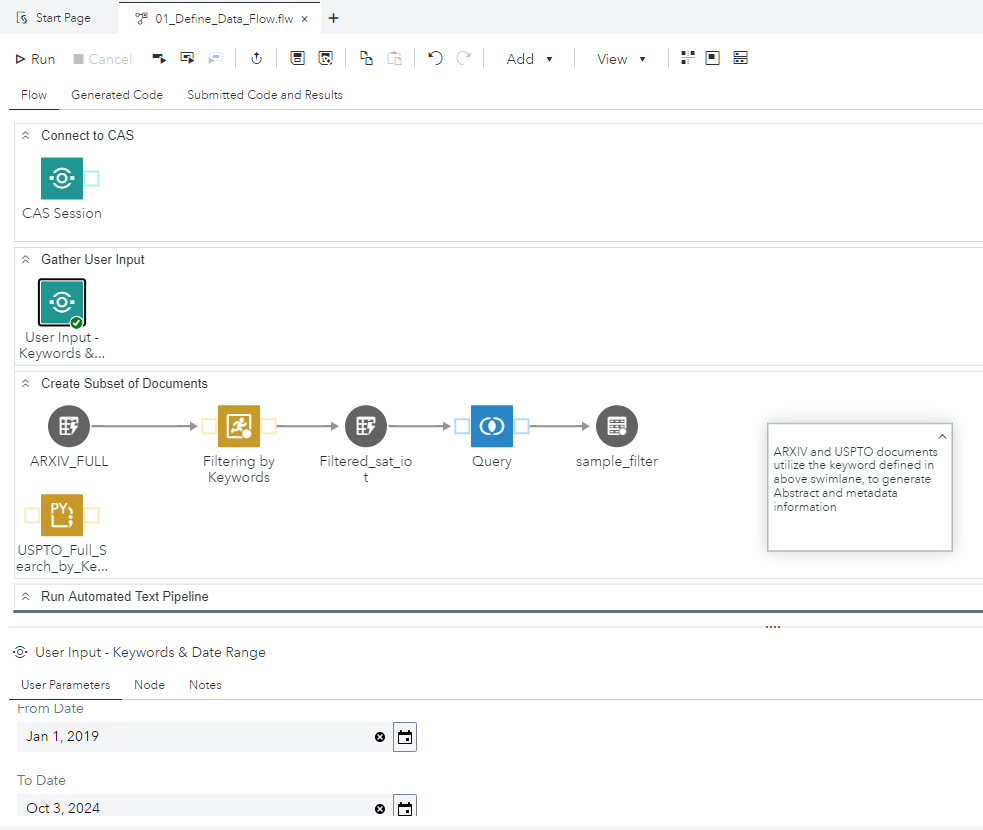
To make the application even more user-friendly, especially for analysts without a programming background, we integrated the Flask application’s API endpoints into SAS Studio flow steps. This allowed us to wrap the API functionality into a graphical user interface (GUI) based submission process. Analysts can now interact with the LLM and submit tasks through drag-and-drop workflows in SAS Studio.
This combination of SAS Studio flow and the LLM capabilities provided a seamless, sequential processing experience where SAS NLP features and our LLM model worked together. The resulting workflow enables analysts to process large datasets in a user-friendly environment, simplifying the steps of text analysis, querying, and document exploration (Figure 5).
Enhancing Interaction with the Data: Visualization of Analytic Output
Beyond batch processing, the project features an interactive chat window powered by RAG (retrieval-augmented generation), enabling real-time, conversation-based querying of the document set of interest. This chat function empowers analysts to explore data dynamically, asking follow-up questions, refining their search criteria, and instantly accessing tailored insights from the documents. This real-time interaction brings responsiveness and flexibility to the research process, helping analysts uncover new information pathways or confirm findings without the need to restart or batch-process new queries.
To extend the analytical depth of the application, we integrated LLM output, text analytics, and advanced NLP capabilities into SAS dashboards that elevate the insights gleaned from document sets. These visual tools offer analysts an intuitive interface to drill down into document specifics, discover themes, or search keywords interactively. This makes it easier to discover and connect critical information that might otherwise remain siloed. Here are some of those key analytics capabilities that were applied to the documents:
- Concept Analysis: This feature automatically detects and categorizes key entities, such as organizations, technologies, and individuals, which are essential for mapping networks or tracing the evolution of specific innovations.
- Topic Modeling: Documents are clustered into thematic groups, making it easier to identify common subjects and trends across large document sets, facilitating trend analysis and quicker data navigation.
- Sentiment Analysis: We gauge the overall tone or sentiment of documents, which is particularly valuable in understanding public reception, stakeholder concerns, or the general outlook within a field.
- Multi-Modal Figure Descriptions: By isolating pages within PDFs containing figures, we employed a multi-modal LLM to generate detailed descriptions of each figure. This capability allows analysts to filter and examine figures of interest, deepening their understanding of the visual elements within each document, which is particularly valuable for patents where figures and diagrams provide critical technical insights.
These features, seen in Figure 6, combined with the LLM’s capabilities for summarization and classification, provide analysts with a powerful toolset for handling unstructured data. The suite of tools enhances the technical triage process by enabling quicker, more precise identification of relevant information, helping analysts prioritize data efficiently, and equipping them with the flexibility to adapt their investigative approaches in real-time. By unifying search, analysis, and interaction, this application maximizes the efficiency and depth of data exploration, empowering analysts to draw actionable insights from complex data sets with greater accuracy and speed.
Key Takeaways and Future Directions
Key Takeaways
This project yielded several insights that transformed how analysts engage with dense, technical patent data. One major takeaway was the enhanced accessibility of this data: by converting complex patent PDFs into structured text and visual information, we made technical content more digestible and actionable. Additionally, the integration of multi-modal insights allowed analysts to explore both narrative descriptions and technical diagrams in tandem, providing a more comprehensive understanding of each document. These advancements, paired with the efficiency gained from automated text extraction and image isolation, streamlined the technical information triage process, enabling analysts to allocate more time to high-priority findings.
Another takeaway was the flexible research experience the application now offers. With GUI-driven workflows and real-time RAG-based querying, analysts can quickly refine and iterate search parameters based on preliminary results, tailoring their inquiries as they learn more. This gives analysts the freedom to adjust their focus in real-time, ensuring their research stays adaptable and effective.
Future Directions
Moving forward, several enhancements could further enrich the application’s capabilities. One area of improvement is image analysis refinement. Enhancing the accuracy of pages with mixed content could yield even more precise image extractions, especially for documents where diagrams overlap with text. Leveraging advanced machine learning models to distinguish between text and image content could elevate this feature to the next level of accuracy.
Another future consideration for this data could be the generation of knowledge graphs, which would visualize connections between entities like technologies, organizations, and patents, making it easier to identify interdependencies. Lastly, implementing a feedback loop where analysts can rate extracted information would enable continuous improvement in model accuracy, refining search and summarization functions based on real user input. Each of these future enhancements could deepen the application’s analytical power, creating a more robust platform for complex patent analysis.
Conclusion
This project highlights the power of human-machine collaboration in triaging large amounts of unstructured data. By combining large language models, machine learning, and user-friendly interfaces, we have created a tool that empowers analysts to make faster, more informed decisions. As we continue to iterate on this platform, we are excited to see how it will help analysts stay ahead of emerging technological trends.
This material is based upon work done, in whole or in part, in coordination with the Department of Defense (DoD). Any opinions, findings, conclusions, or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the DoD and/or any agency or entity of the United States Government.
- Categories: