Automated Tearline Generation and Evaluation with Large Language Models
Kyle Rose, Will Gleave, Julie Hong (Amazon Web Services)
Stacie K, Mike G, Edward S, Brent Y (LAS)

Introduction
Tearlines are portions of an intelligence report that provide the content of the report at a lower classification level or with less restrictive dissemination controls. They are a powerful mechanism for enabling wider dissemination of intelligence information. However, writing tearlines is time consuming and slows an organization’s production of valuable intelligence. In this work we seek to ease the cognitive burden on analysts and accelerate the intelligence reporting workflow by investigating the use of Large Language Models (LLMs) for automated tearline generation. Using a proxy dataset of biomedical research abstracts and lay summaries, we develop techniques for generating and evaluating tearlines as well as related augmentations to the reporting workflow. Specifically, we investigate the following:
- Tearline Generation – compare various models and prompting techniques.
- Tearline Evaluation – develop an evaluation suite to assess the generated tearlines’ quality.
- Explainability – develop techniques to aid the analyst in proofreading the tearline draft.
- Rule Generation – develop a pipeline for codifying unwritten rules dictating tearline content.
Our evaluations show that LLMs have high potential for application to mission data and use in reporting tools. They largely produce well-written proxy tearlines that are faithful to the source document and follow provided rules. Explainability and rule generation techniques also show promise as features in an improved reporting workflow.
Tearline Generation
To generate a tearline, a machine learning model modifies the source document according to a set of rules that are either explicitly provided, or implicitly learned through examples. These rules dictate what content may be included in the tearline text and ensure it is at the appropriate classification level and does not reveal sensitive sources, methods or other operational information. Given the restricted nature of intelligence reporting data, we use a proxy dataset of technical biomedical research abstracts to simulate the problem [1]. The goal in this setting is to produce lay summaries of the technical abstracts that omit technical language and other details in an analogous manner to report tearlines. We write and generate proxy rules for this data to effectively assess the potential applicability of various generation techniques to mission data. An example set of rules, abstract and generated lay summary are in Figure 1.

We compare two types of models for this task, sequence to sequence (seq2seq) models such as Bart and T5v1.1 and foundation LLMs such as Claude 3 Sonnet or Mixtral 8x22b. Seq2seq models are lightweight and fast, but they must learn the rules for writing tearlines through training examples. Foundation models are more powerful and can accept the rules directly in their context making them easily adaptable to use cases in different reporting offices. We experiment with these models and various prompting techniques and develop LLM-based evaluations to compare them.
Tearline Evaluation
High quality tearlines are faithful to the source report, follow all rules that apply to their content, and are composed in a style specific to reporting offices. Existing evaluations are insufficient for evaluating all of these characteristics so we compile an LLM-based evaluation suite to assess the quality of the generations. The following dimensions of tearline quality are covered in the suite:
- Rule Following: tearlines must follow all rules that apply to their content to protect sensitive information.
- Overall Quality: tearlines should be well-written with all of their content relevant and faithful to the source report.
- Analyst Alignment: tearlines should be written with the same style and structure as experienced analysts
Rule Following
We design an LLM-as-a-judge evaluation in which a generated tearline and a rule are provided to a model to make a determination of whether or not the generation text violates the rule. This evaluation operates on the document level, requiring a single rule-break anywhere in the text to flag the text as in violation of a given rule.
Meta-evaluations of this method using Claude 3 Sonnet demonstrate that evaluating one rule at a time led to higher evaluation quality than evaluating all rules at once. Additionally, it is beneficial for evaluation quality to provide few-shot examples in the text of the rule itself. For example, the rule: “Do not include the scientific names for a cell or cell type”, should be augmented to something similar to: “Do not include the scientific name of a cell or cell type, but instead refer to the cell in layman’s terms. For example, instead of ‘alveolar macrophages’, say ‘lung cells’ …” Engineering the rules in this way helps the model properly interpret and apply them. For this evaluation we use a fixed set of nine, hand-written rules that focus on the omission or generalization of technical details.
We begin with a comparison of various prompts, starting simple and gradually layering on additional complexity. We evaluate combinations of the following prompting strategies:
- Prompting the model to rewrite the text.
- Prompting the model to follow the provided rules.
- Asking the model to explain its reasoning.
- Giving the model a role and background information (ex. “You are a senior analyst…”).
- Providing the model 1 or 2 examples of proper rewrites.
For each prompt, Claude 3 Sonnet generates lay summaries for the 96 technical abstracts in the test set. We determine the percentage of these summaries that violate each rule and report the average violations over the rules.
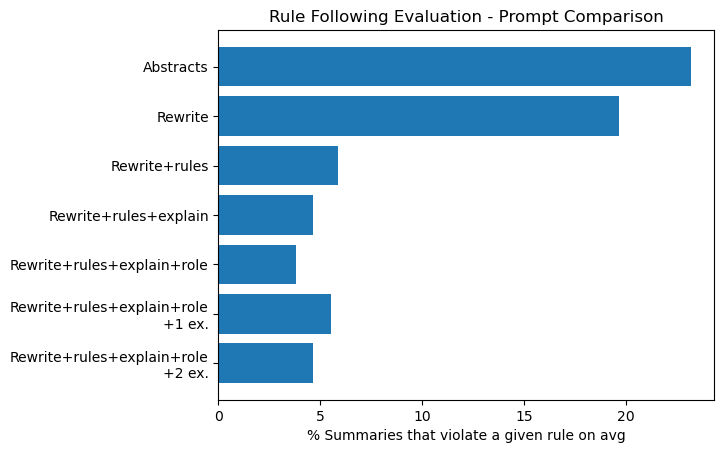
We include the results for the source abstracts for reference since many samples follow certain rules from the start. As a baseline, 23.2% of the abstracts violate a rule on average and we seek to improve that metric in our generations. As demonstrated in Figure 2, providing the model with a role and some background information and asking it to explain its reasoning before rewriting led to the best rule following performance. This prompt corrected 84% of the violations initially present in the abstracts. Most performance gains were achieved by simply asking the model to follow the rules, with more advanced prompts yielding smaller improvements. Including few-shot examples in the prompt did not further increase performance. Additional exploration is needed to understand if this is a natural plateau in model ability or if the examples were not sufficient for the task.
Next, we compare the rule following ability of various foundation LLM models. The same optimal prompt is used, adjusting it as needed to account for specific model idiosyncrasies. Results are in Figure 4.
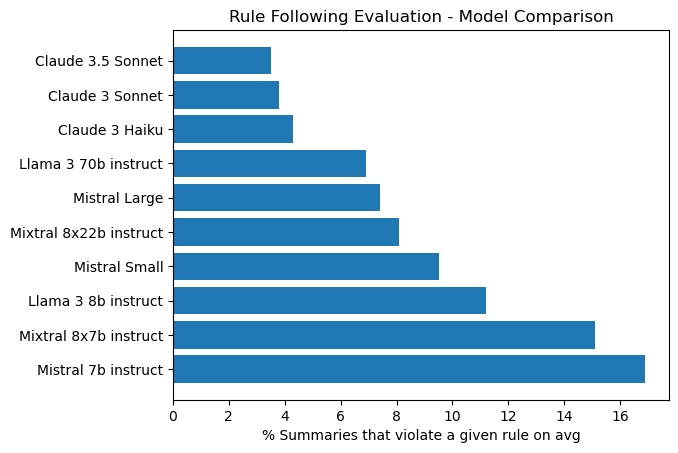
Claude 3 and 3.5 models follow rules best. While this was consistent with qualitative observations, the prompt tuning presented above was done with Claude 3 Sonnet. Other models may benefit from similar, tailored prompt tuning. The plot also shows that model size is an important factor in performance, with larger models following rules better than smaller ones (We make the assumption that proprietary models like the Claude family are larger than open-source models). Seq2seq models are not included in this evaluation because they must learn rules implicitly through examples.
Overall Quality
Similar to any generated summary or translation, tearlines should be well-written, relevant and faithful to their source. Inspired by the G-eval framework, we develop evaluations for these characteristics starting with fluency and coherence. Fluency refers to the quality of the text in terms of grammar, spelling, punctuation, etc. and coherence to the quality of the structure and organization. Both evaluations are ratings on a 1-3 scale. Results are plotted in Figure 5.
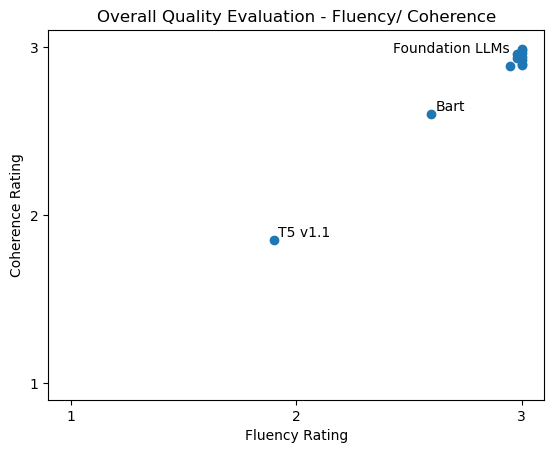
Foundation LLMs reliably produce fluent and coherent text. The Seq2seq models Bart and T5 v1.1 were rated lower in both characteristics.
The next pair of evaluations assess the factual accuracy of the generated text and its relevance to the source report. The evaluating LLM identifies irrelevant statements in the generated text and the average number of irrelevant statements per summary is recorded. In a similar manner the number of factual inconsistencies or hallucinations per summary is determined. Results for these metrics are in Figure 6.
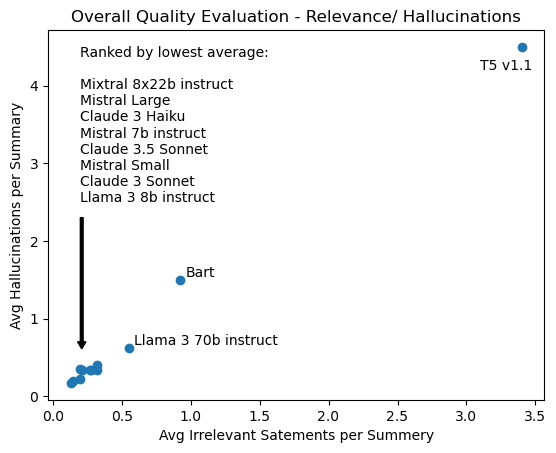
Once again, foundation models outperform seq2seq models, having the lowest rates of hallucinations and irrelevant statements. Across all four overall quality metrics Claude 3.5 Sonnet outperformed Bart by an average of 47%.
Analyst Alignment
Intelligence reporting is a unique form of writing and tearline drafts should be produced in a manner consistent with analyst expectations. To assess this alignment, we develop two final evaluations that compare generations with ground truth. The first rates from 1-3 the degree of similarity in writing style between the two, with a higher rating indicating more similarity. The second rates the similarity in the overall structure of the text, assessing how the content is organized. Results are plotted in Figure 7.
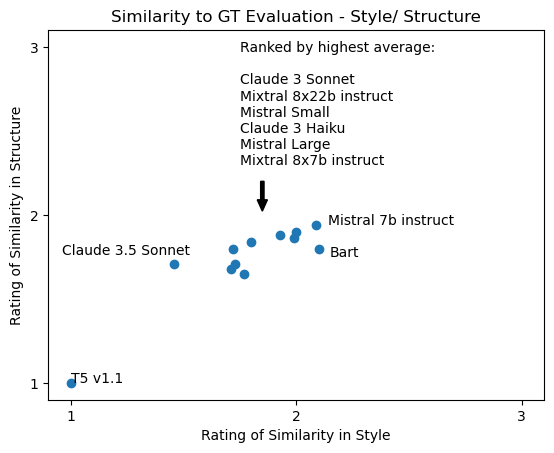
Bart is competitive with foundation models for these metrics, likely because it is exposed to many examples of proper output in its training data. Although this is also true for T5 v1.1, it continues to underperform the other models tested. Foundation models have room for improvement in this area but have shown great ability to adapt with additional information. One potential avenue for improvement is the incorporation of analyst feedback into the generation prompt. Including established guidance on writing tearline reports in the rules provided to the LLM should further increase alignment.
Explainability
Automated tearline generation has exciting potential to reduce analysts’ cognitive load, allowing them to focus on more challenging aspects of their work. However, this will only be true to the extent that an analyst is able to quickly verify and correct the generated content. To assist analysts in proofing tearline drafts we develop a prompt that produces inline citations of the rules used to modify the source document. An example is in Figure 8:

Small scale, manual evaluations suggest that larger models such as Claude 3.5 Sonnet, are capable of producing inline citations, while smaller models like Claude 3 Haiku are unable to handle this more complicated task. Additional capabilities for building analyst trust such as identifying hallucinations and rule violations in the tearline drafts should be explored in future work.
Rule Generation
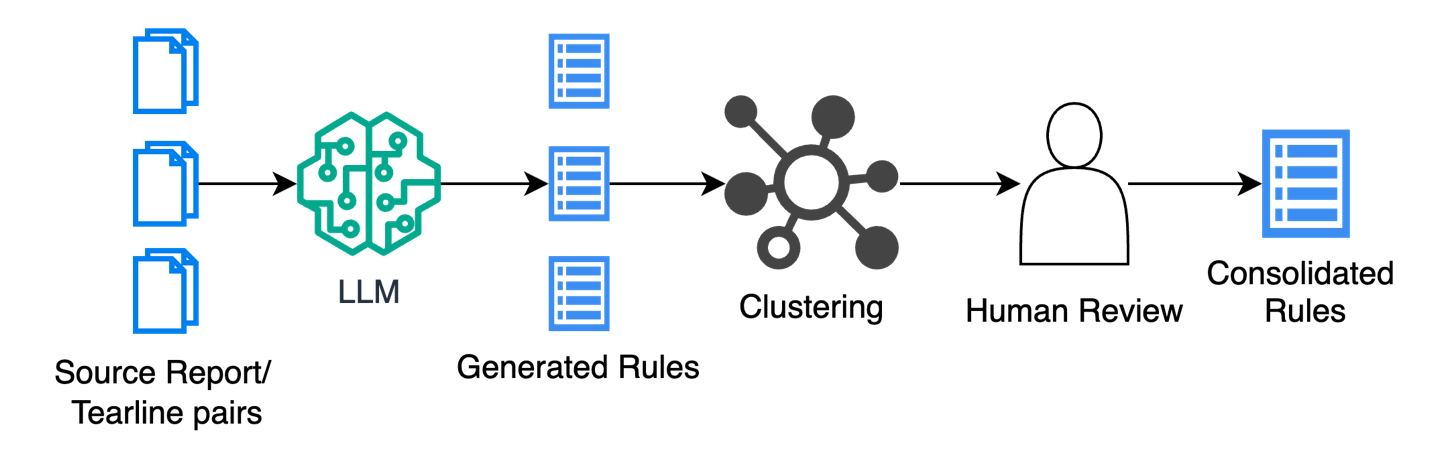
Many of the rules that guide the writing of tearlines are explicitly defined in reporting guidance and security classification guides. Others, however, are informal heuristics that must be learned from experience and vary from office to office. To assist both LLMs and new analysts in writing tearlines we develop an LLM-based pipeline to codify these unwritten rules (Figure 9). First, an LLM generates rules for pairs of source documents and tearlines. Then the rules are clustered and reviewed by senior analysts before being consolidated to a final list. Figure 10 displays example generated rules. The list may serve as a working aid for analysts or as input to the tearline generation model to drive the production of higher quality tearlines.

Conclusion
Here we demonstrated the potential for LLMs to generate tearline drafts in analyst workflows. We quantified LLMs’ ability to follow rules and found that larger models are better than smaller models at this task. Claude 3 models outperformed all others and the best prompt provided a role and required an explanation of reasoning before writing. We also showed that foundation LLMs outperform seq2seq models in assessments of overall quality. Additionally, we quantify the alignment in style and structure between generated and analyst-written tearlines and identify room for improvement in those areas. Finally, we discussed efforts to make explainable tearline drafts and to codify unwritten rules important for tearline creation. There is potential to apply these techniques to mission data in future work.
Contact Info
- Kyle Rose (kymrose@amazon.com)
- Will Gleave (sgleave@amazon.com)
- Julie Hong (hongjth@amazon.com)
This material is based upon work done, in whole or in part, in coordination with the Department of Defense (DoD). Any opinions, findings, conclusions, or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the DoD and/or any agency or entity of the United States Government.
- Categories: